Proximal policy optimization
Deep Reinforcement Learning dengan Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
A2C
- Pembaruan kebijakan A2C:
- Berdasar estimasi yang mudah berubah
- Bisa besar dan tidak stabil
- Dapat menurunkan kinerja

PPO
- PPO membatasi besar tiap pembaruan kebijakan
- Meningkatkan stabilitas

Rasio probabilitas
- Inovasi utama PPO: fungsi objektif baru
- Intinya:

- Seberapa lebih mungkin aksi $a_t$ dengan $\theta$ dibanding $\theta_{old}$?
Mengklip rasio probabilitas
- Fungsi clip:
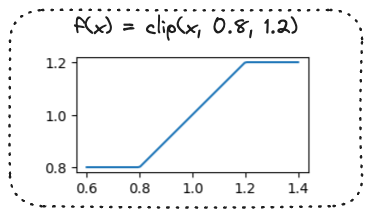
Fungsi objektif PPO

surr1 = ratio * td_error.detach()surr2 = clipped_ratio * td_error.detach()objective = torch.min(surr1, surr2)
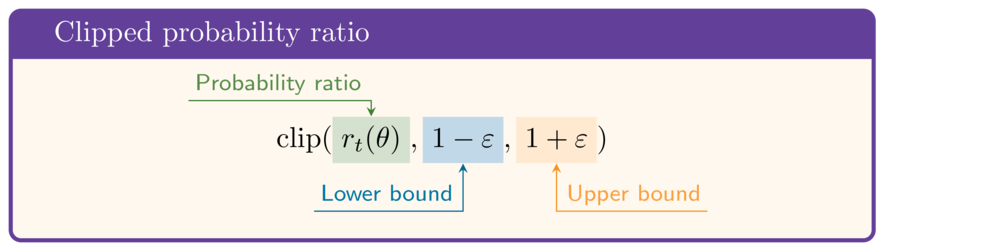
- Surrogate dengan rasio terklip:
$$\mathrm{clip}(r_t(\theta),1-\varepsilon,1+\varepsilon)\hat{A}$$
- Fungsi objektif surrogate terklip PPO:

- Lebih stabil daripada A2C

