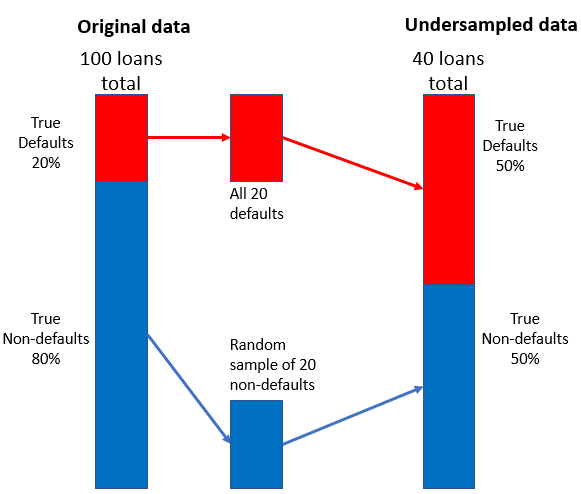
Ketidakseimbangan kelas pada data pinjaman
Pemodelan Risiko Kredit dengan Python

Michael Crabtree
Data Scientist, Ford Motor Company
Fungsi rugi model
- Gradient Boosted Trees di
xgboostmemakai fungsi rugi log-loss- Tujuannya meminimalkan nilai ini
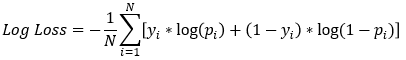
| Status pinjaman benar | Probabilitas prediksi | Log Loss |
|---|---|---|
| 1 | 0.1 | 2.3 |
| 0 | 0.9 | 2.3 |
- Prediksi gagal bayar yang keliru berdampak finansial lebih besar
Strategi undersampling
- Gabungkan sampel acak kecil non-gagal bayar dengan gagal bayar