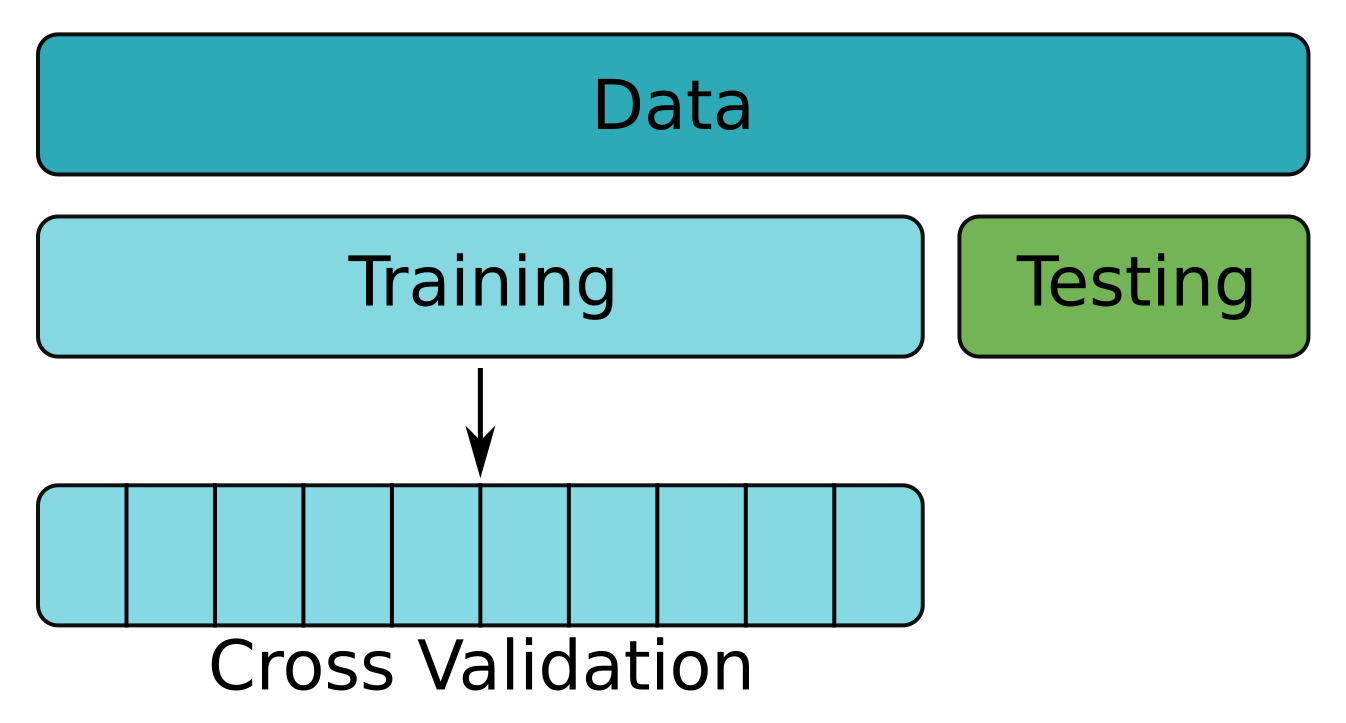
Validasi Silang
Machine Learning dengan PySpark

Andrew Collier
Data Scientist, Fathom Data


Lapisan demi lapisan - lipatan pertama

Lapisan demi lapisan - lipatan kedua
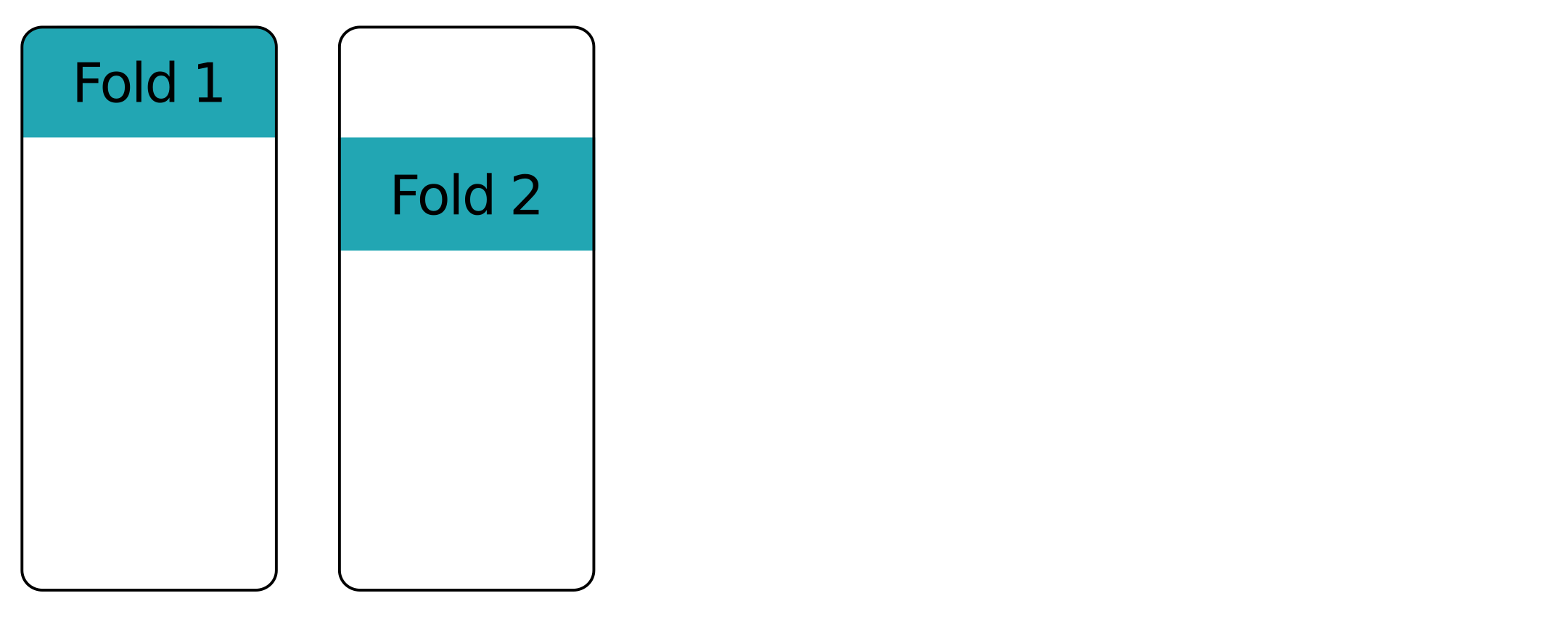
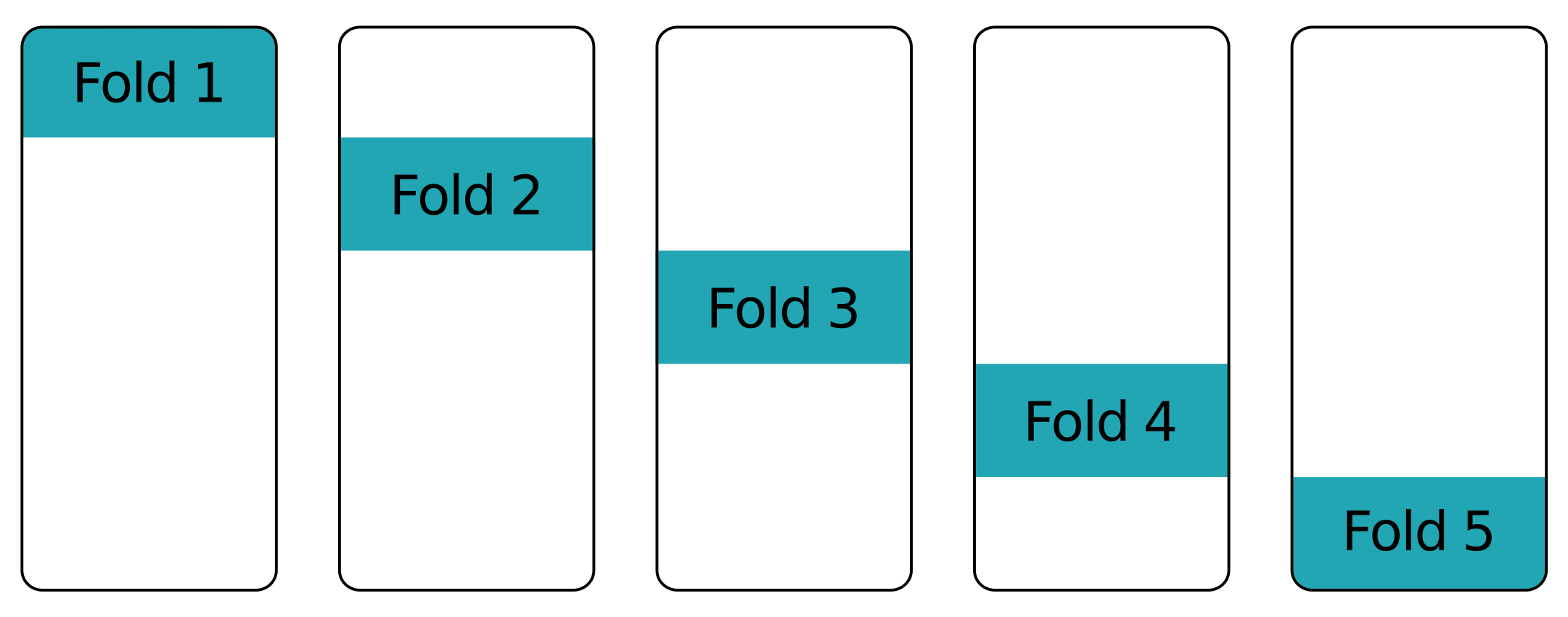
Lapisan demi lapisan - lipatan lain
Machine Learning dengan PySpark
Andrew Collier
Data Scientist, Fathom Data

