Pipeline
Machine Learning dengan PySpark

Andrew Collier
Data Scientist, Fathom Data
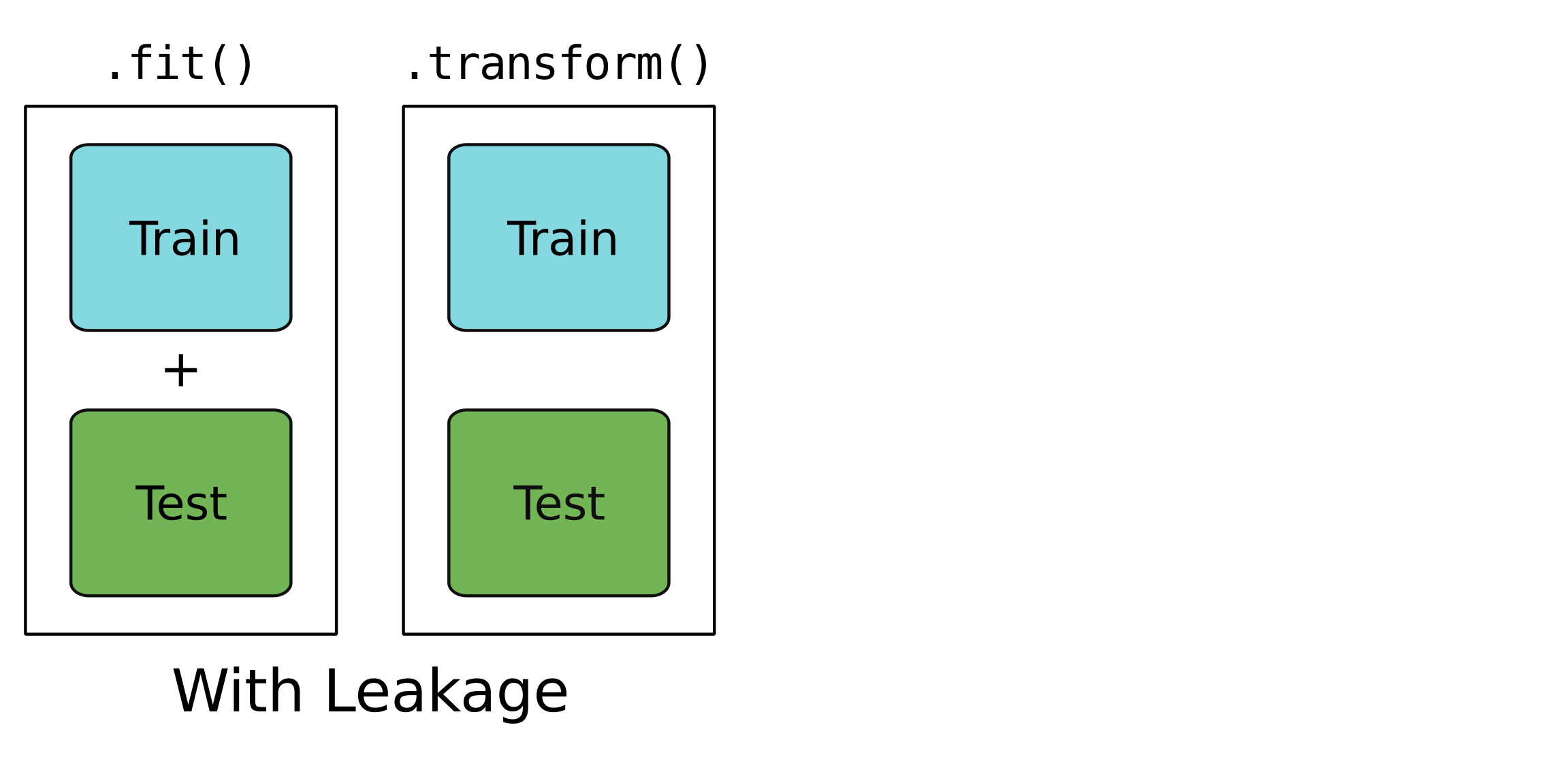
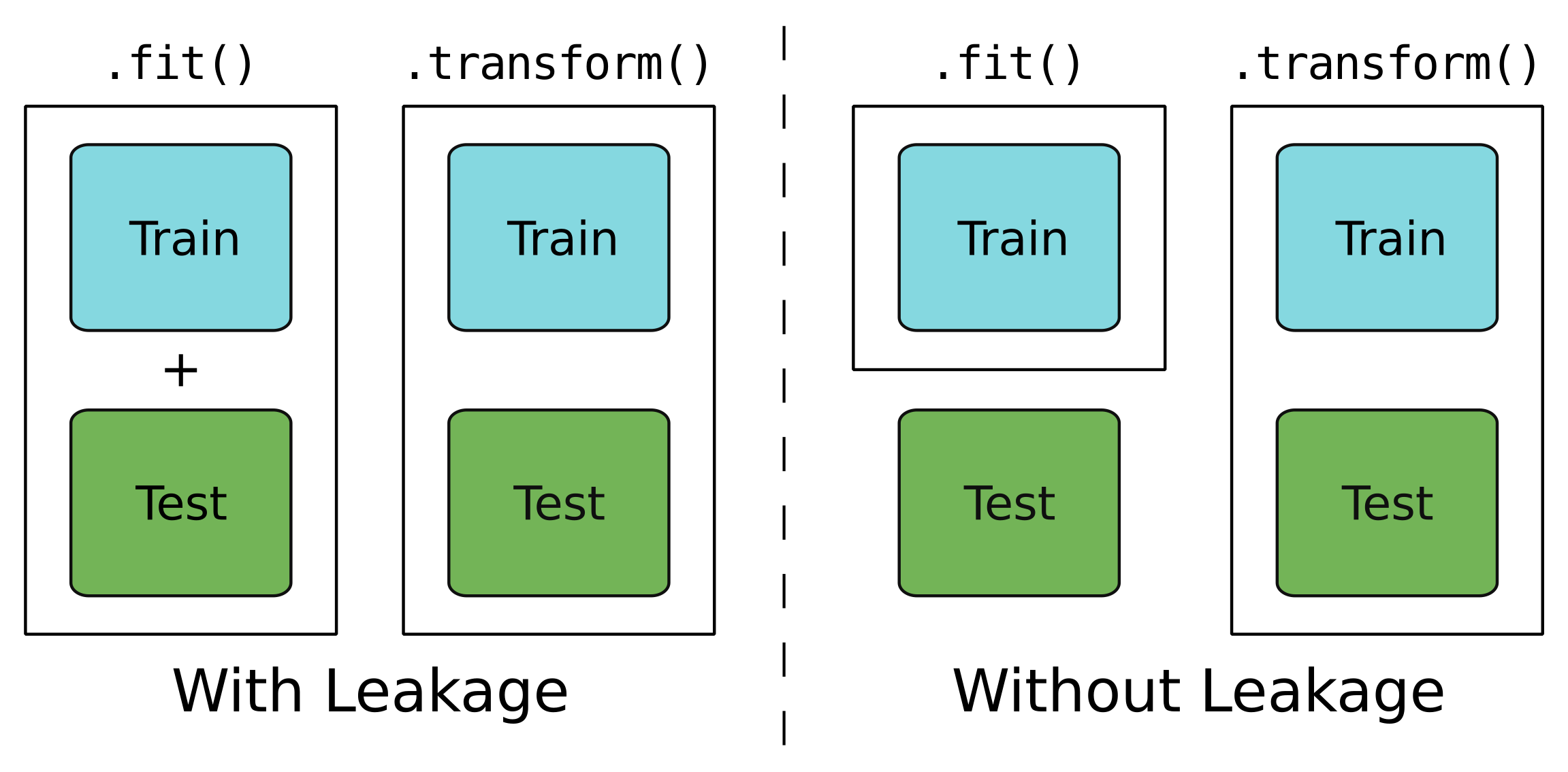
Kebocoran?

Hanya untuk data pelatihan.

Untuk data pengujian dan pelatihan.
Model bocor
Model rapat air
Pipeline
Pipeline terdiri dari serangkaian operasi.

Anda bisa menerapkan setiap operasi satu per satu... atau cukup terapkan pipelinenya!

