Tuning hyperparameter di Python
Penyetelan Hyperparameter di Python

Alex Scriven
Data Scientist
Parameter pada Logistic Regression
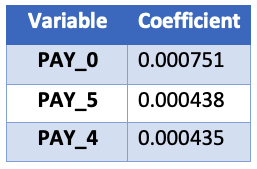
Sekarang urutkan dan cetak tiga koefisien teratas
coefs.sort_values(by=["Coefficient"], axis=0, inplace=True, ascending=False)
print(coefs.head(3))