Memahami output grid search
Penyetelan Hyperparameter di Python

Alex Scriven
Data Scientist
Kolom 'time' di .cv_results_
Kolom time merujuk waktu untuk melatih (dan menilai) model.
Ingat kita melakukan 5-fold cross-validation? Ini berjalan 5 kali dan menyimpan rata-rata serta simpangan baku waktunya (detik).
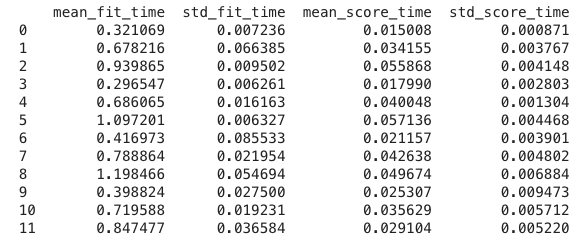
Kolom 'param_' di .cv_results_
Kolom param_ menyimpan parameter yang diuji pada baris itu, satu kolom per parameter
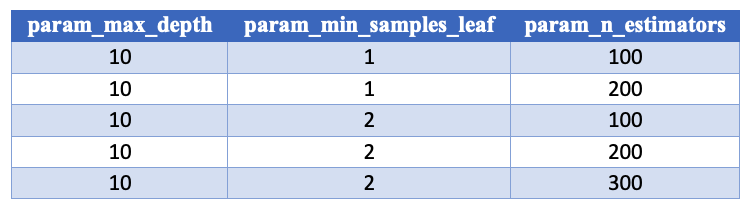
Kolom 'param' di .cv_results_
Kolom params berisi kamus semua parameter:
pd.set_option("display.max_colwidth", -1)
print(cv_results_df.loc[:, "params"])

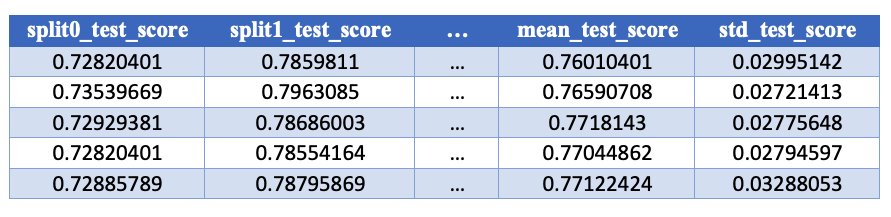
Kolom 'test_score' di .cv_results_
Kolom test_score memuat skor pada test set untuk tiap fold serta ringkasan statistik:
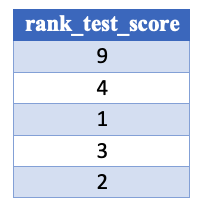
Kolom 'rank_test_score' di .cv_results_
Kolom peringkat, mengurutkan mean_test_score dari terbaik ke terburuk:
Mengekstrak baris terbaik
Kita dapat memilih kotak grid terbaik dari cv_results_ menggunakan kolom rank_test_score
best_row = cv_results_df[cv_results_df["rank_test_score"] == 1]
print(best_row)

Properti best_estimator_
print(grid_rf_class.best_estimator_)


