Metode mengumpulkan umpan balik berkualitas tinggi
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Metode mengumpulkan umpan balik berkualitas tinggi
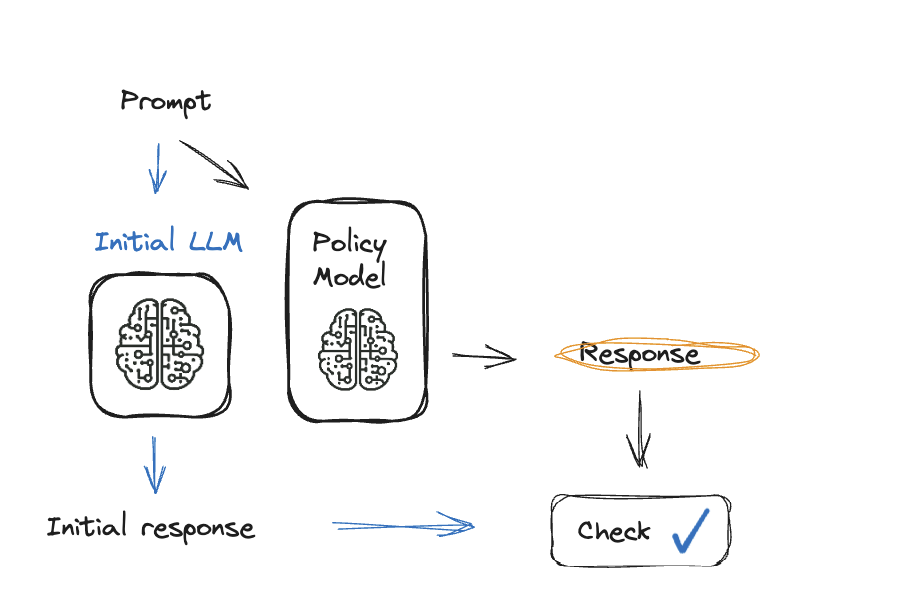
Metode mengumpulkan umpan balik berkualitas tinggi

Perbandingan berpasangan

Rating

Faktor psikologis

Panduan mengumpulkan umpan balik berkualitas tinggi


