Fine-tuning efisien dalam RLHF
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Fine-tuning hemat parameter
- Fine-tuning seluruh model
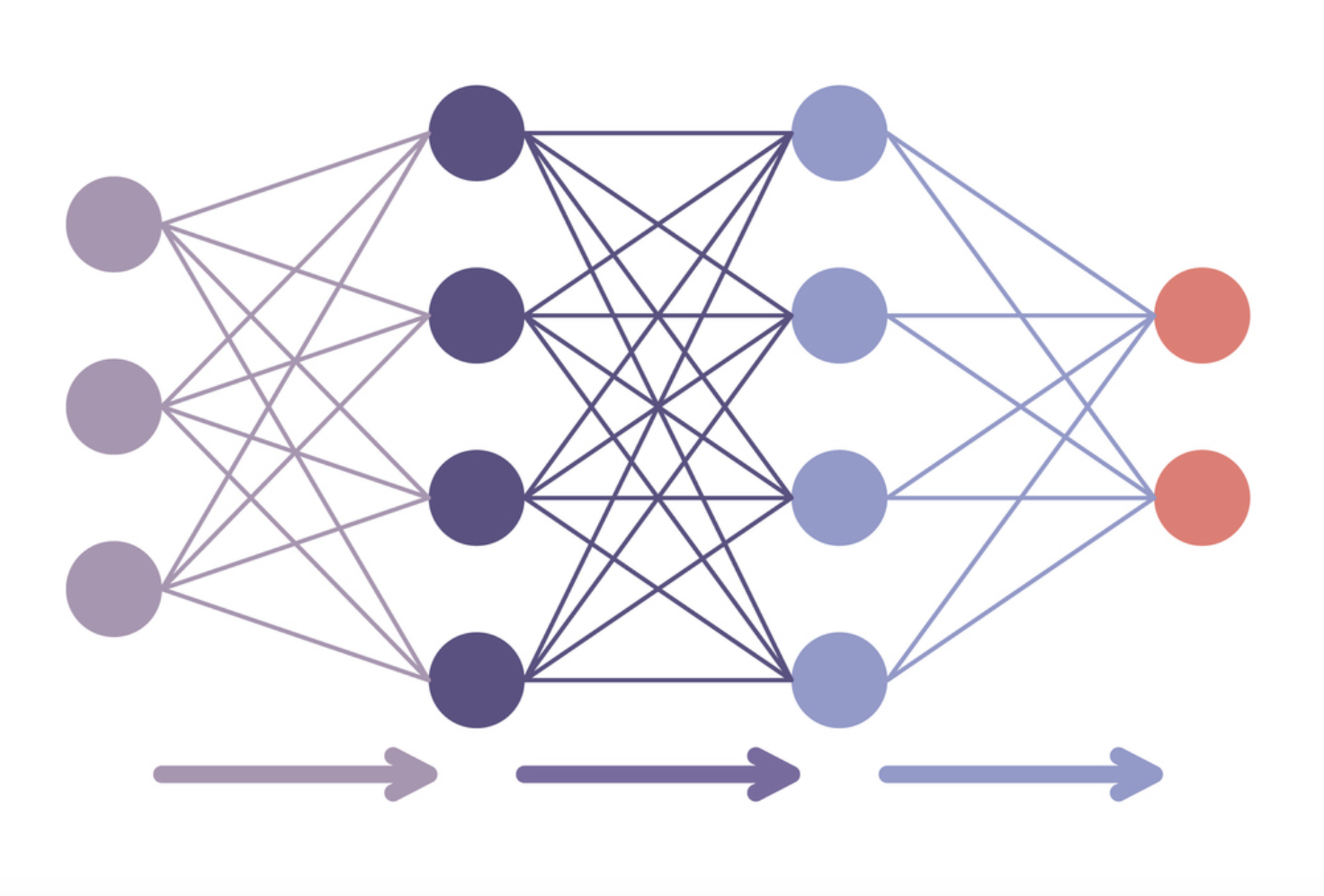
Fine-tuning hemat parameter
- Fine-tuning dengan PEFT
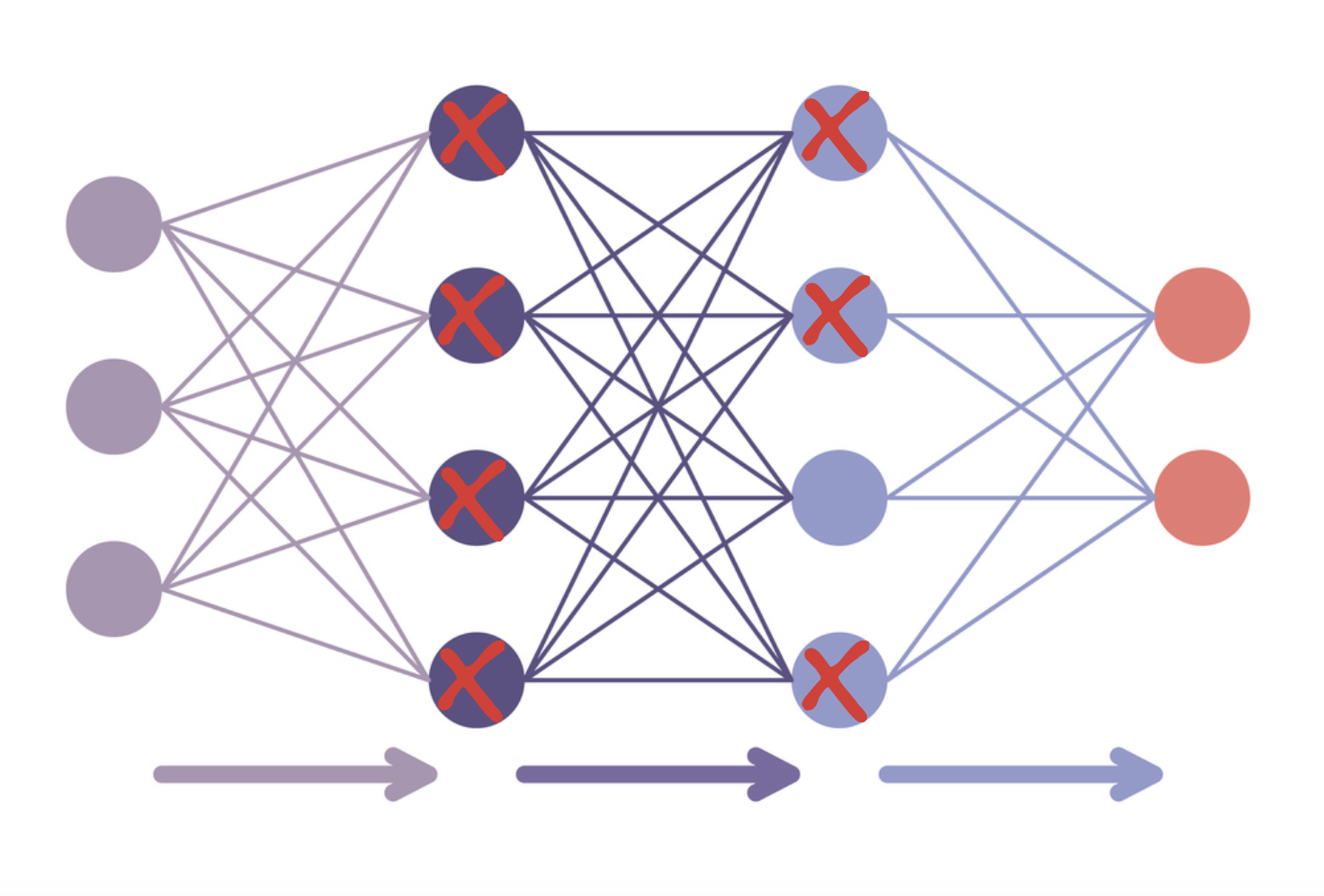
- LoRA: menyesuaikan beberapa lapisan saja
- Kuantisasi: menurunkan presisi tipe data

