Menjelajahi LLM terlatih awal
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Pentingnya fine-tuning
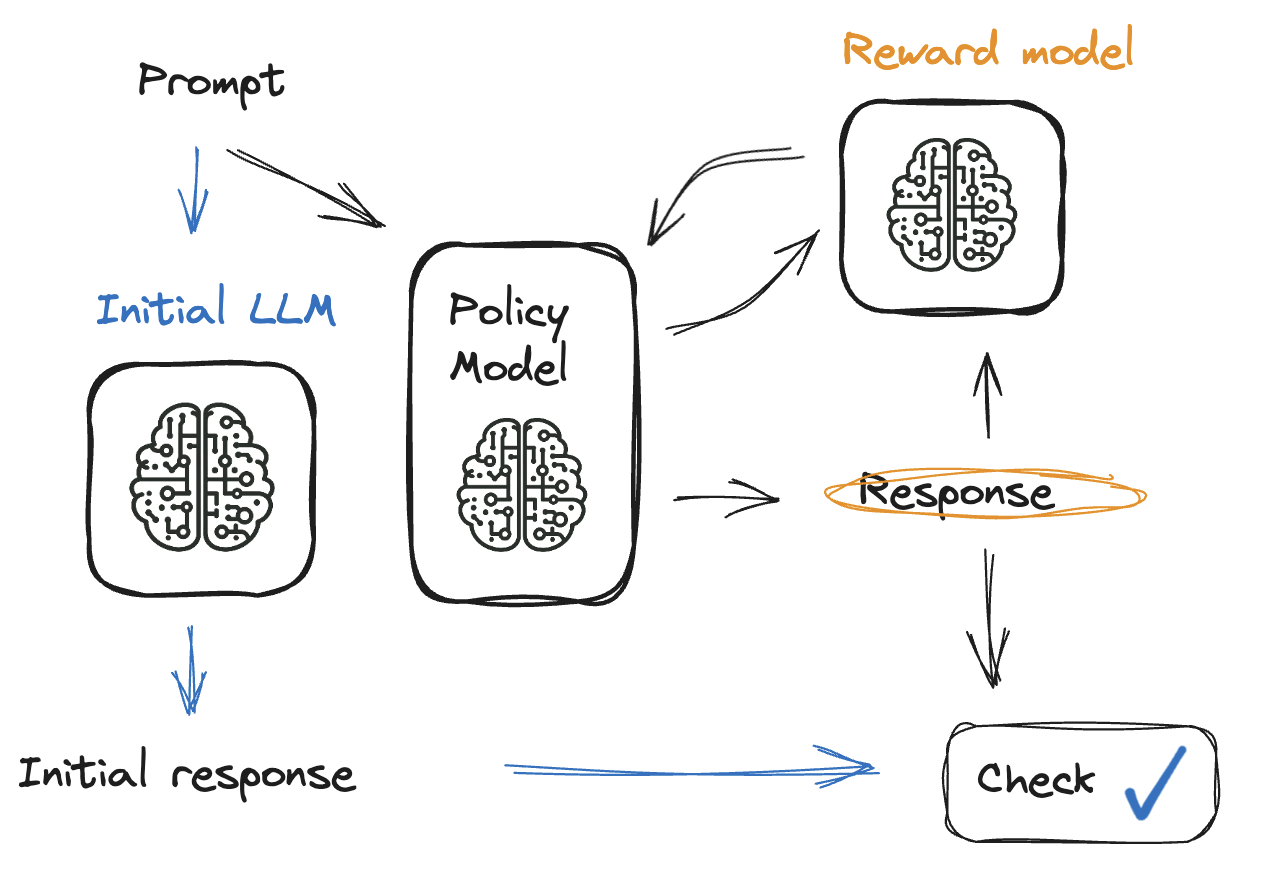
Pentingnya fine-tuning

Panduan langkah demi langkah untuk fine-tuning LLM
Panduan langkah demi langkah untuk fine-tuning LLM
Panduan langkah demi langkah untuk fine-tuning LLM