Pelatihan dengan PPO
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Fine-Tuning dengan reinforcement learning
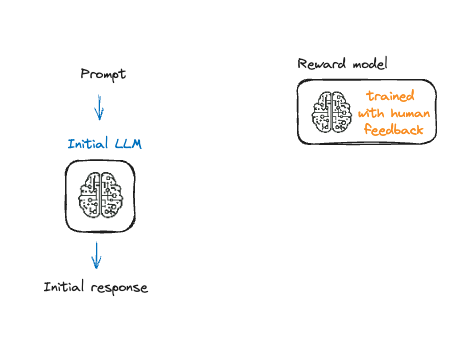
Fine-Tuning dengan reinforcement learning
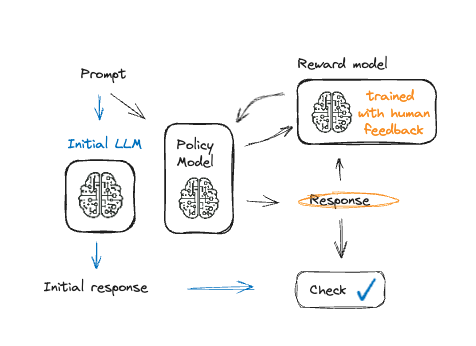
Fine-Tuning Model Bahasa dengan PPO
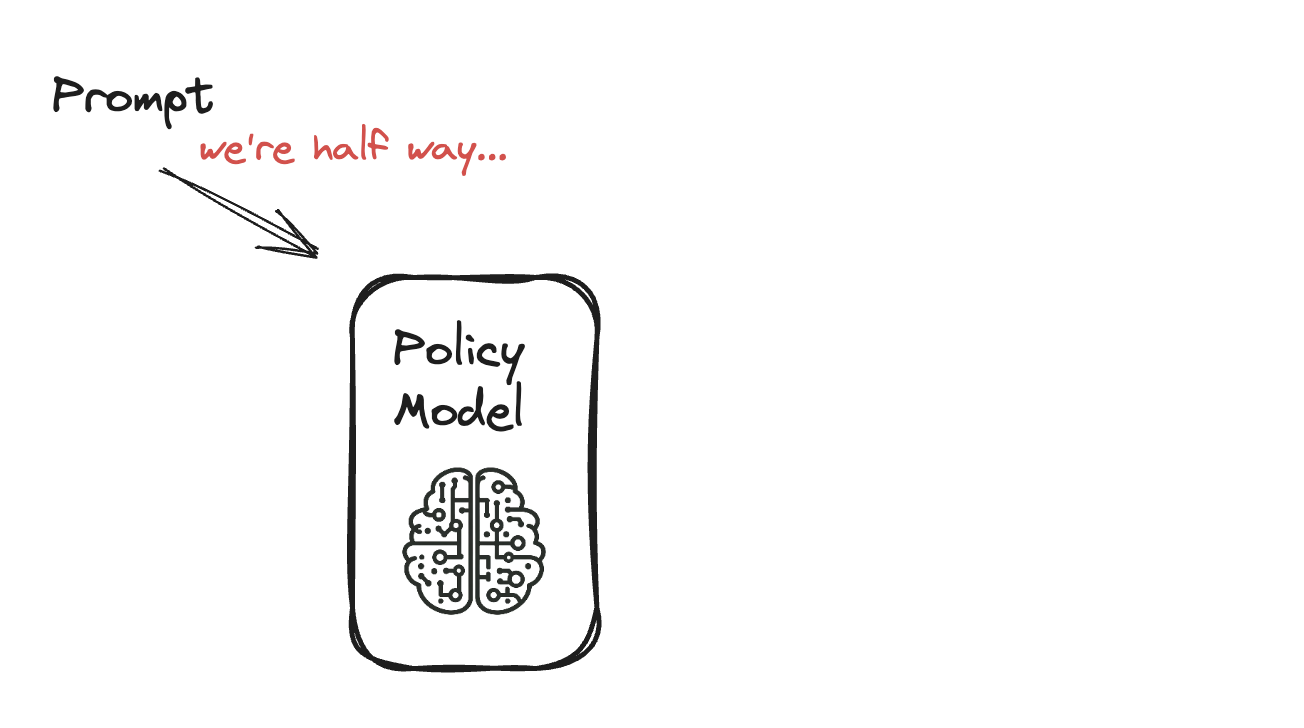
Fine-Tuning Model Bahasa dengan PPO
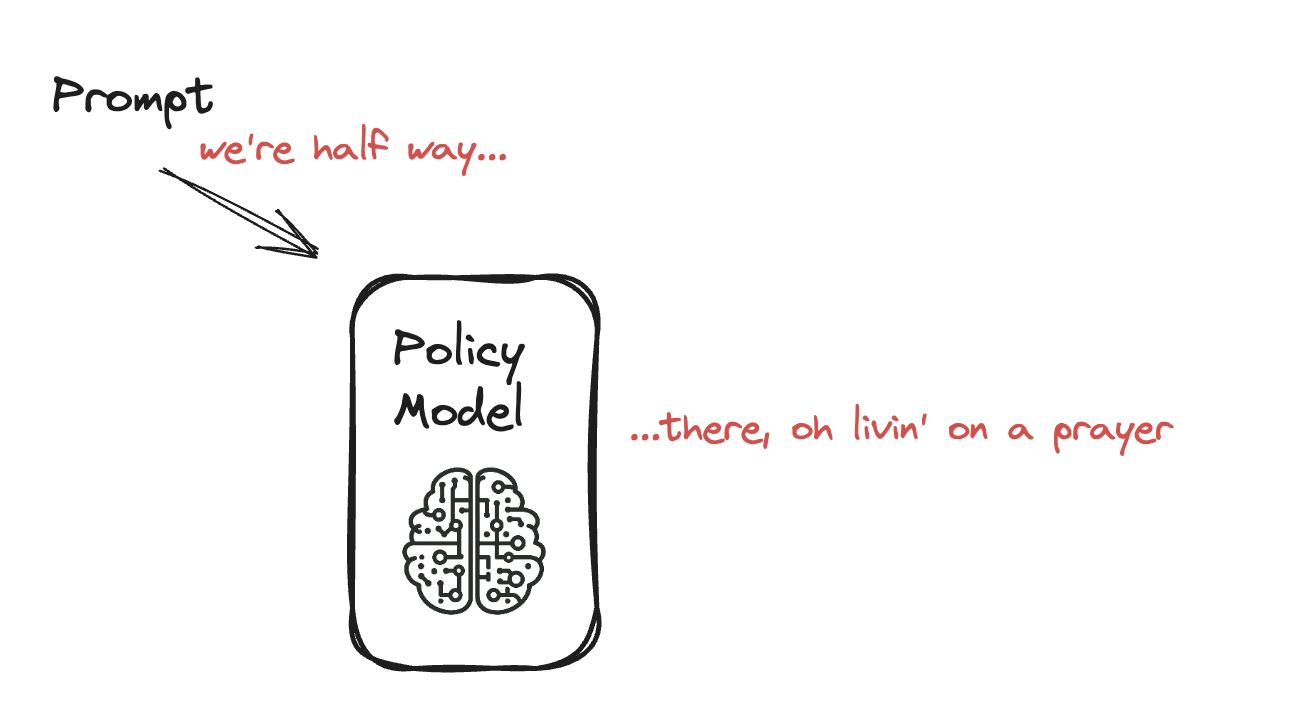
Fine-Tuning Model Bahasa dengan PPO
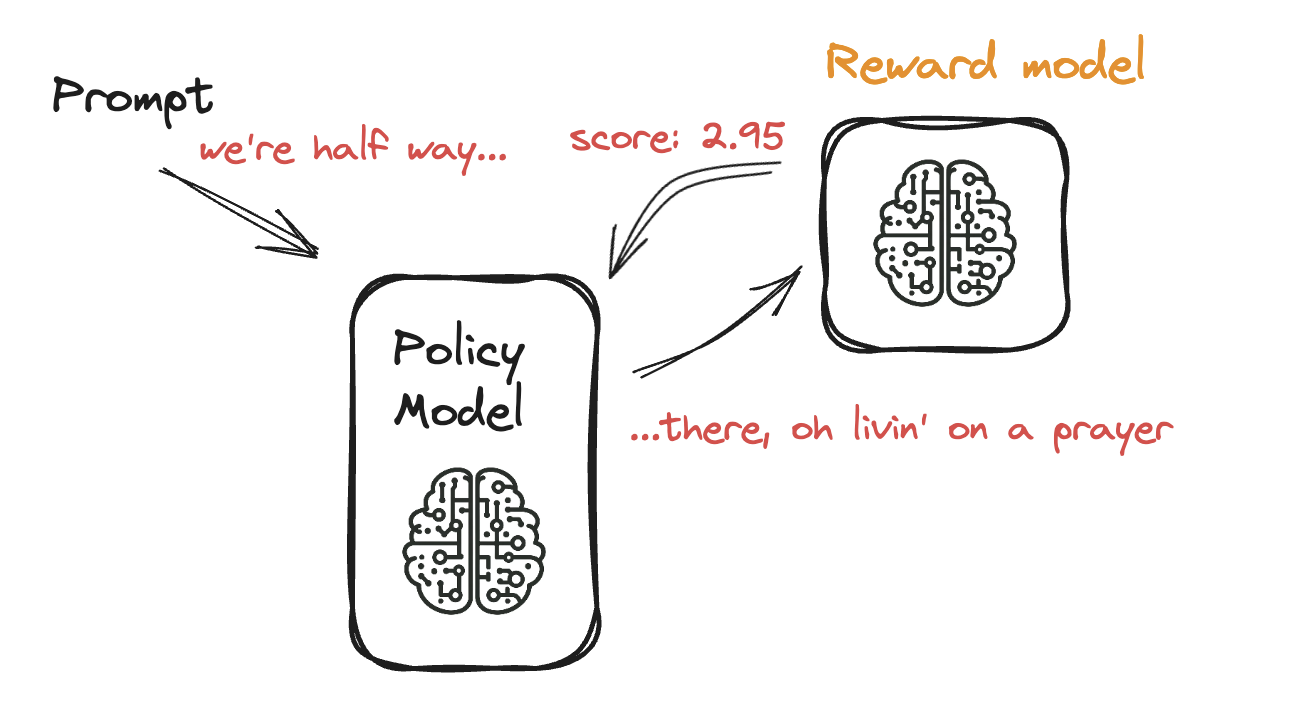
Fine-Tuning Model Bahasa dengan PPO
- PPO: penyesuaian bertahap pada model
- Menghindari overfitting pada umpan balik


