Metrik model dan penyesuaian
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Mengapa gunakan model referensi?

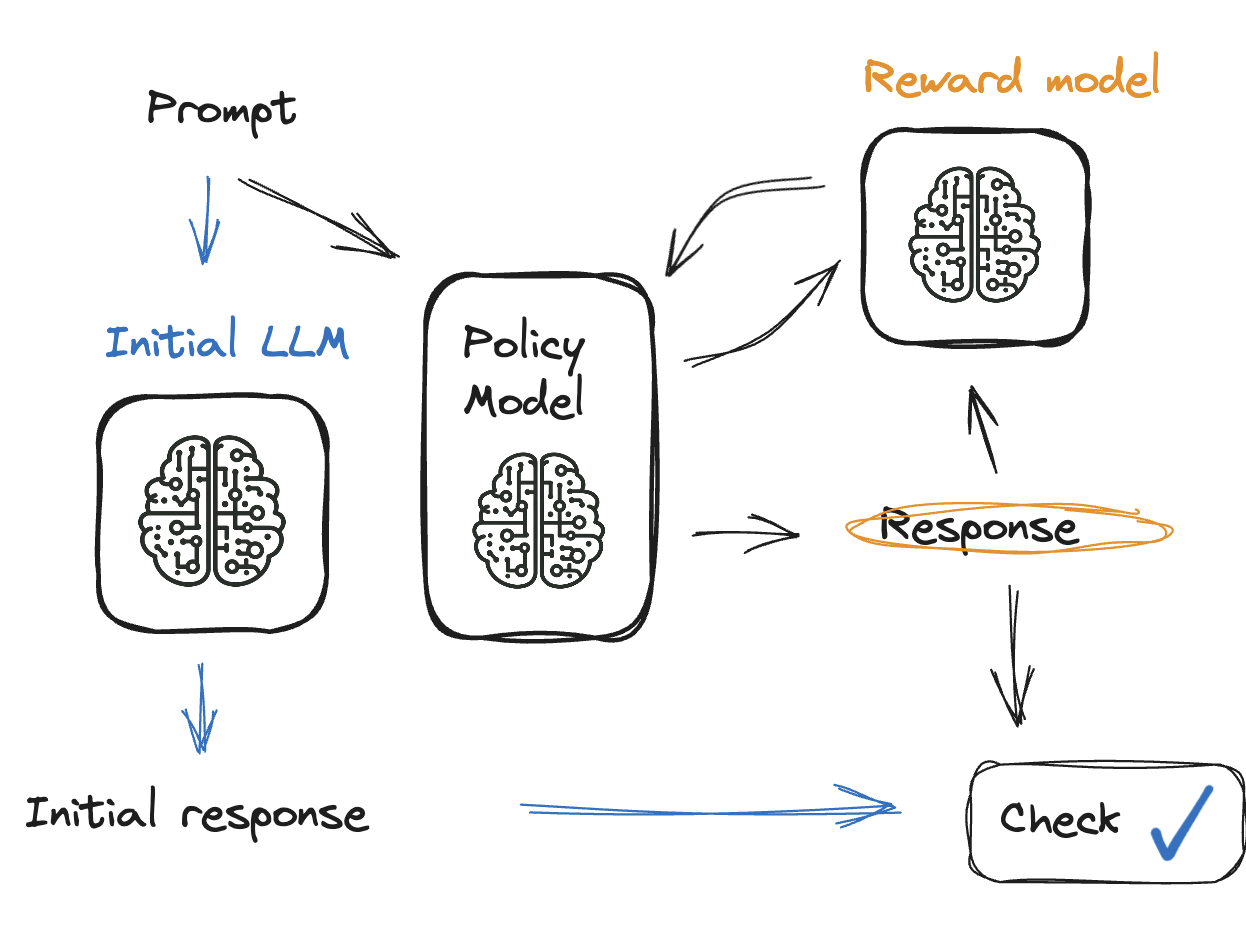
Memeriksa output model
Solusi: divergensi KL
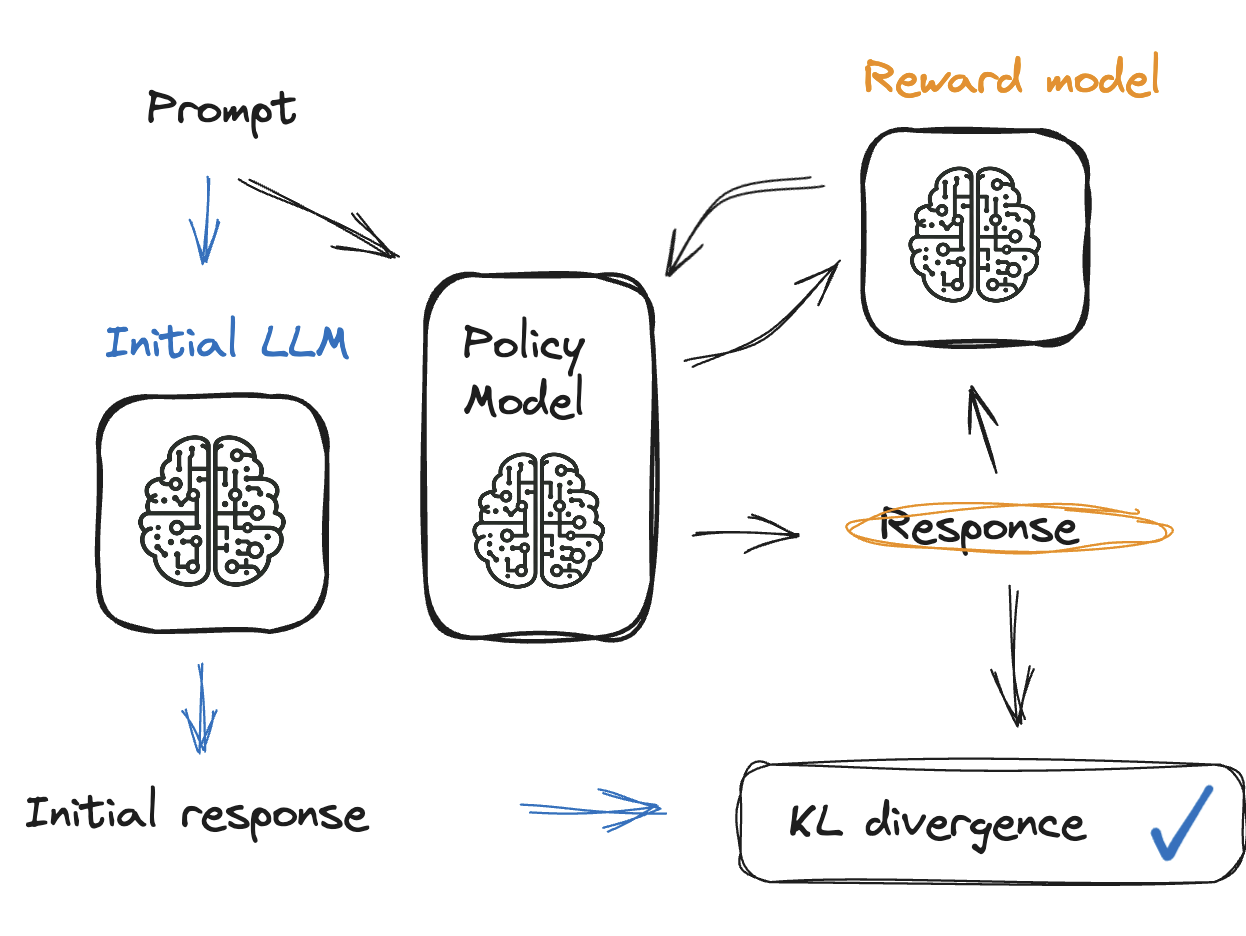
Solusi: divergensi KL
- Tambahkan penalti ke model reward
- Penalti mengoreksi arah saat output tidak relevan
- Divergensi KL membandingkan model saat ini dan model reward

- Antara 0 dan 10, dan tidak pernah negatif

