Menggabungkan beragam sumber umpan balik
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Generalization model yang lebih baik

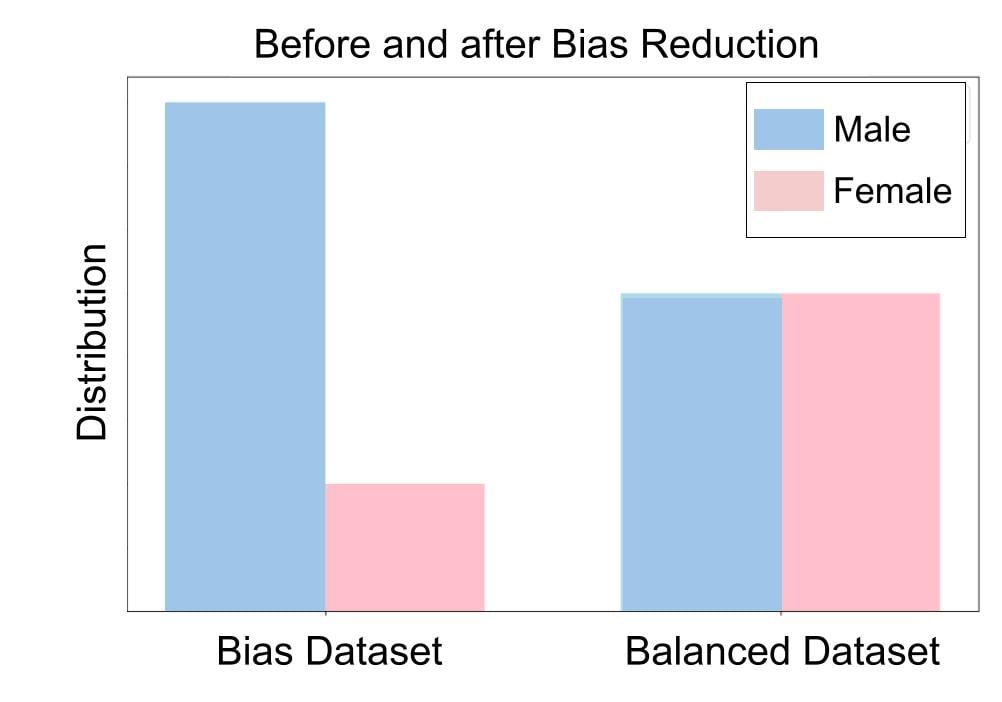
Bias berkurang
Kesesuaian yang lebih baik dengan nilai manusia

Adaptabilitas yang lebih baik

Ketahanan meningkat
Mengintegrasikan data preferensi dari banyak sumber
Data preferensi preference_df dengan sumber 'Journalist', 'Social Media Influencer', dan 'Marketing Professional':

Sumber data preferensi yang tidak andal
Data preferensi preference_df2 dengan tiga pakar yang sama:


