Ringkasan
Pemrosesan Bahasa Alami dengan spaCy

Azadeh Mobasher
Principal data scientist
Bab 1 - Pengantar NLP dan spaCy
- Gunakan pipeline pemrosesan teks
spaCyuntuk mengekstrak fitur linguistik:

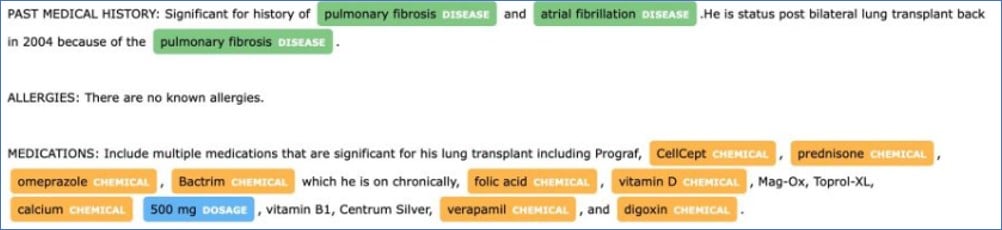
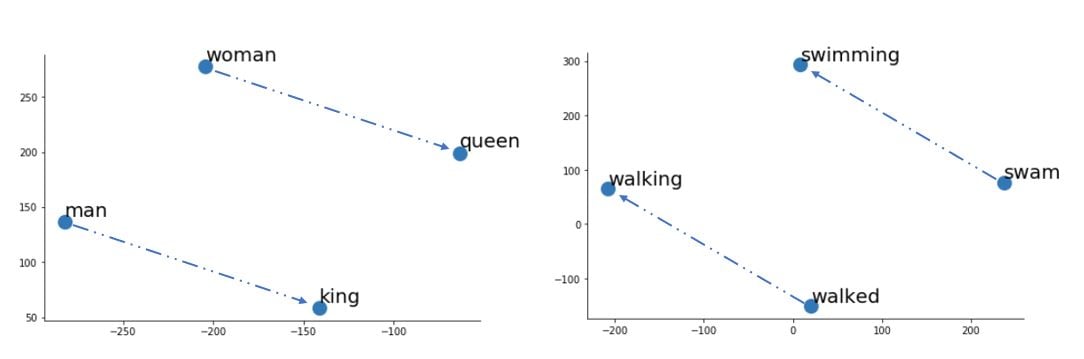
Bab 2 - Anotasi linguistik spaCy dan vektor kata
- Gunakan kelas
spaCysepertiDoc,Token, danSpan, serta prediksi kemiripan semantik dengan vektor kata:
Bab 4 - Kustomisasi model spaCy
- Anotasi dan siapkan data untuk pelatihan
- Latih model
spaCydan gunakan saat inferensi