Mengukur kemiripan semantik dengan spaCy
Pemrosesan Bahasa Alami dengan spaCy

Azadeh Mobasher
Principal Data Scientist
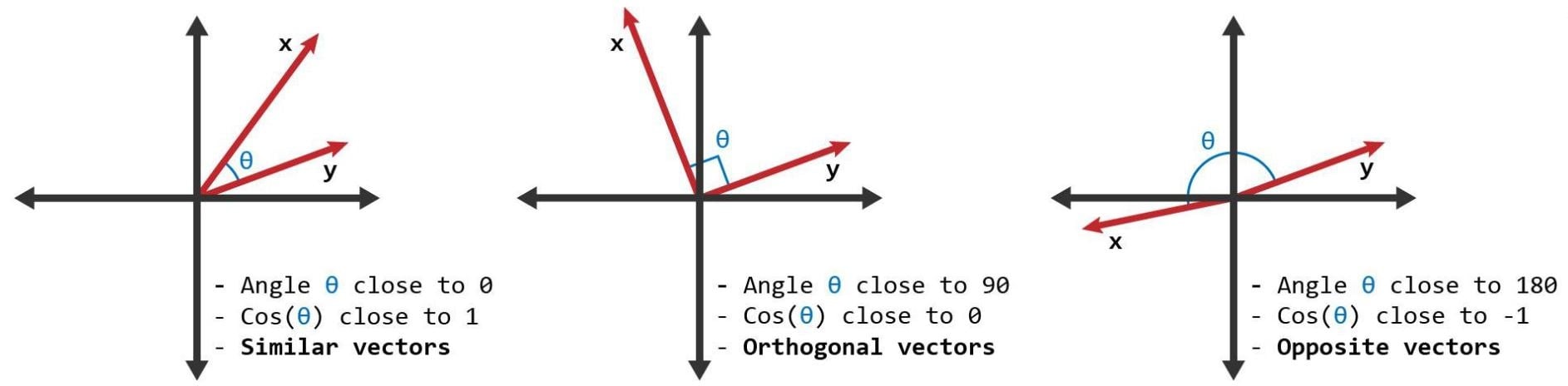
Skor kemiripan
- Sebuah metrik untuk teks
- Untuk mengukur kemiripan gunakan cosine similarity dan word vector
- Cosine similarity bernilai antara 0 dan 1