Transforming inputs before modeling
Supervised Learning di R: Regresi

Nina Zumel and John Mount
Win-Vector LLC
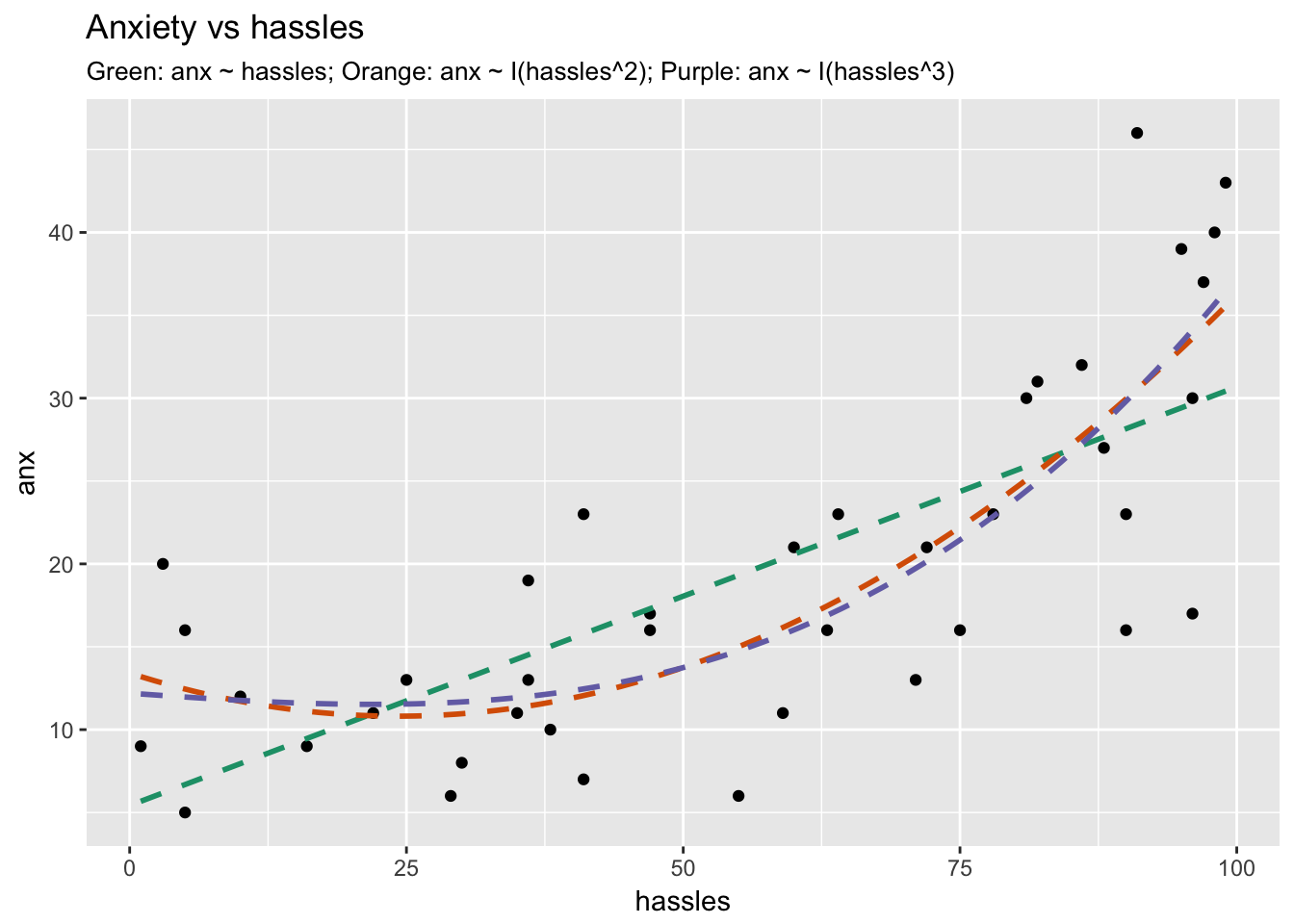
Example: Predicting Anxiety
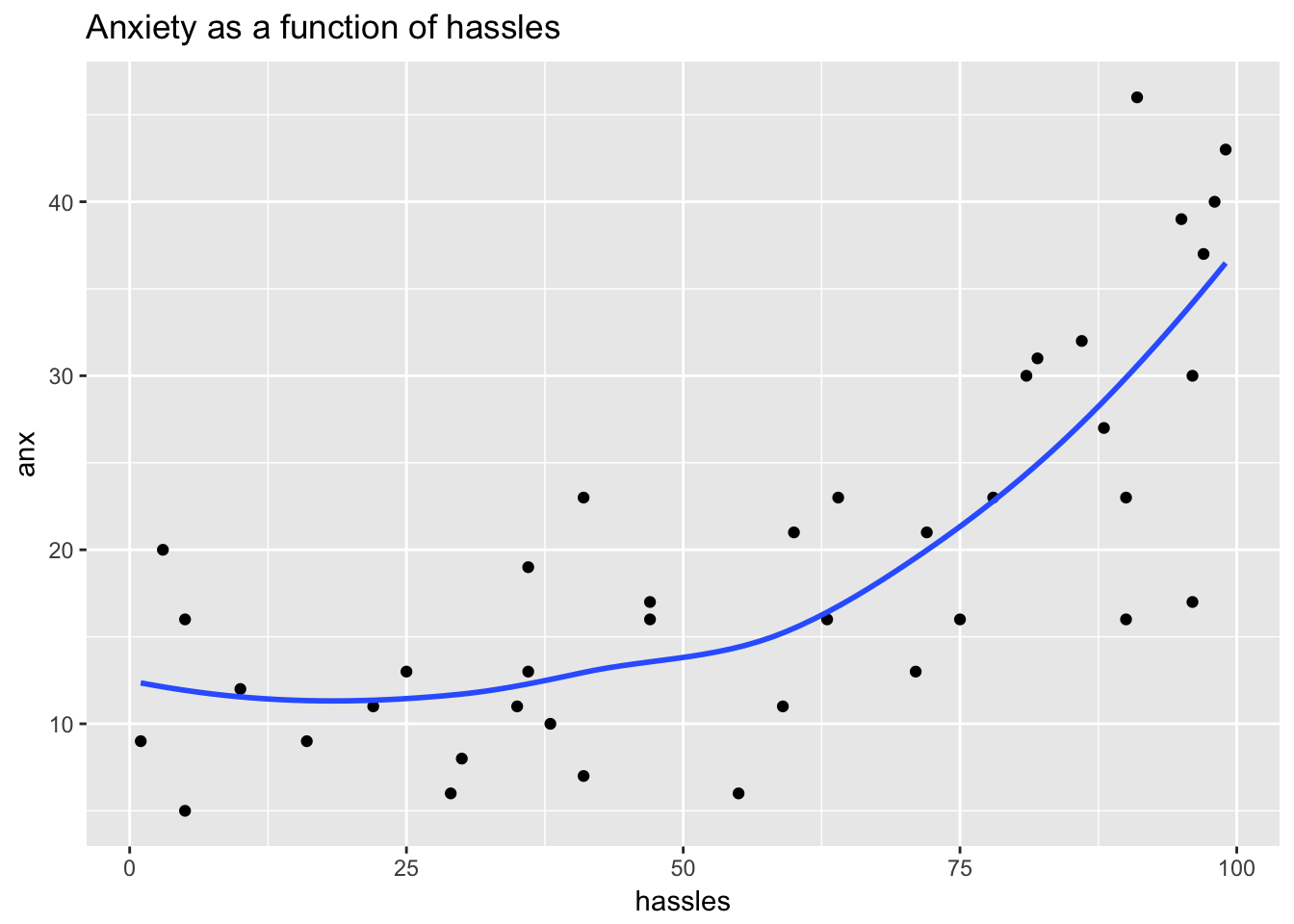
Transforming the hassles variable
Supervised Learning di R: Regresi
Nina Zumel and John Mount
Win-Vector LLC

