Estimasi Parametrik
Manajemen Risiko Kuantitatif dengan Python

Jamsheed Shorish
Computational Economist
Kelayakan kecocokan
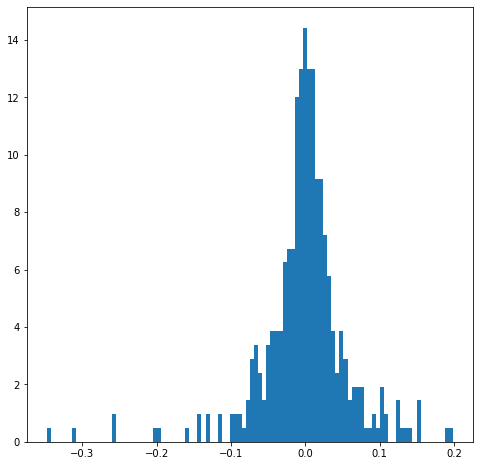
Kelayakan kecocokan
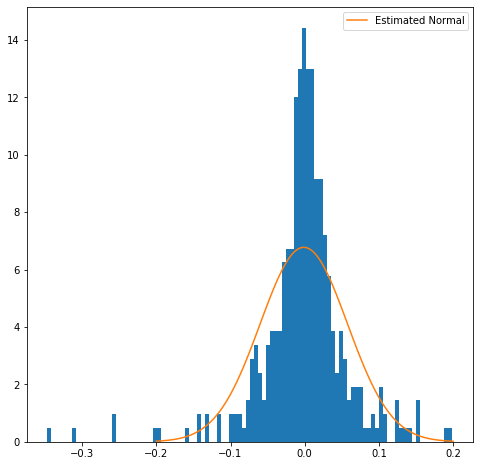
Kelayakan kecocokan
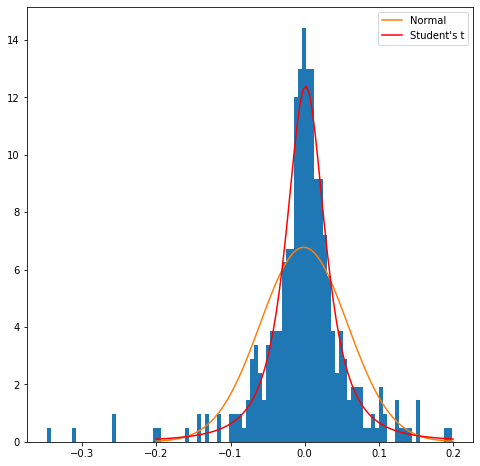
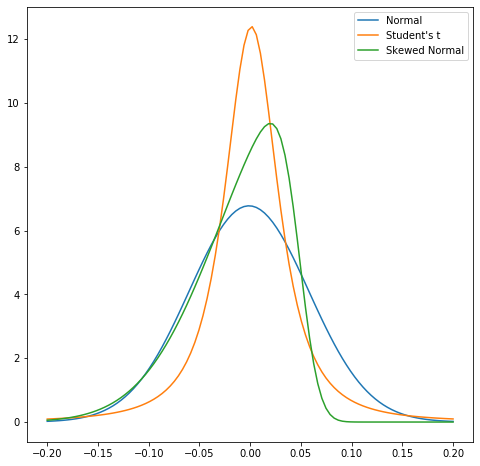
Skewness
Skewness
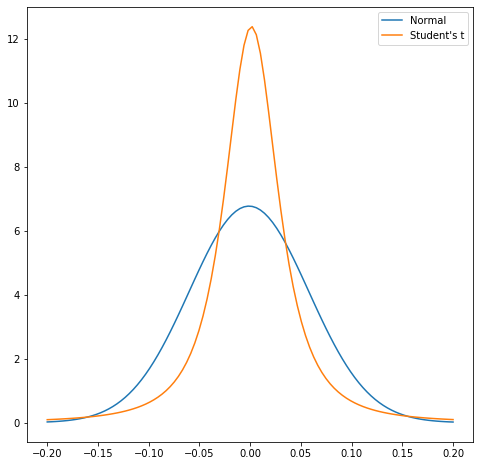
Skewness
Manajemen Risiko Kuantitatif dengan Python
Jamsheed Shorish
Computational Economist

