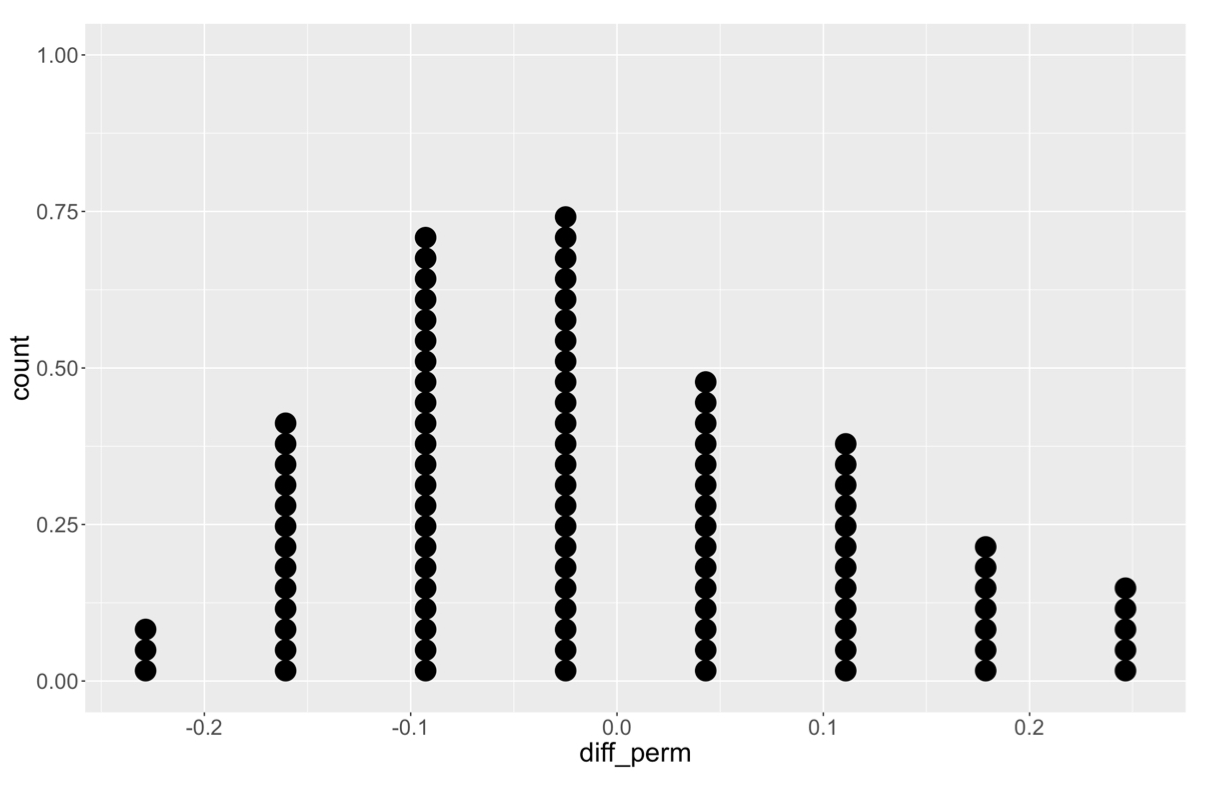
Distribusi teracak
Dasar-dasar Inferensi di R

Jo Hardin
Instructor
Logika inferensi
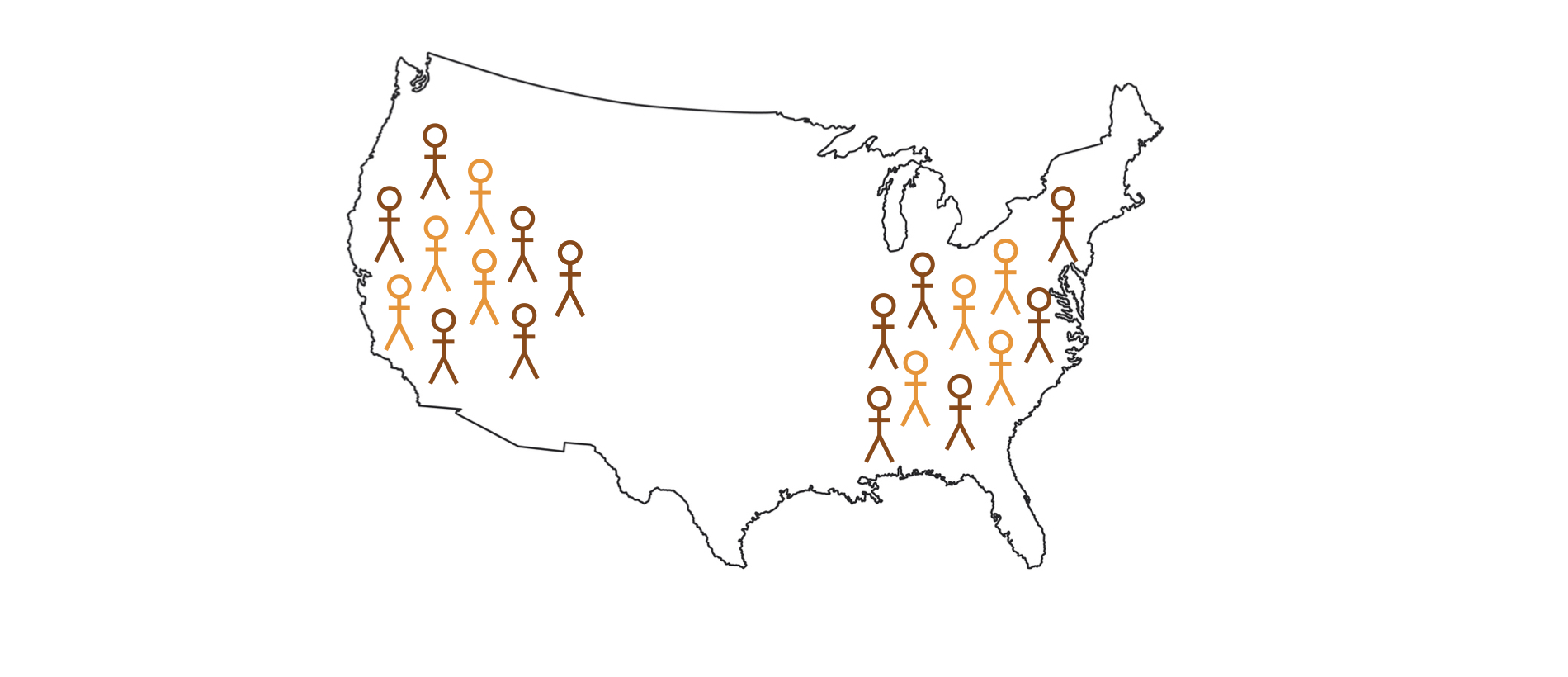
Logika inferensi
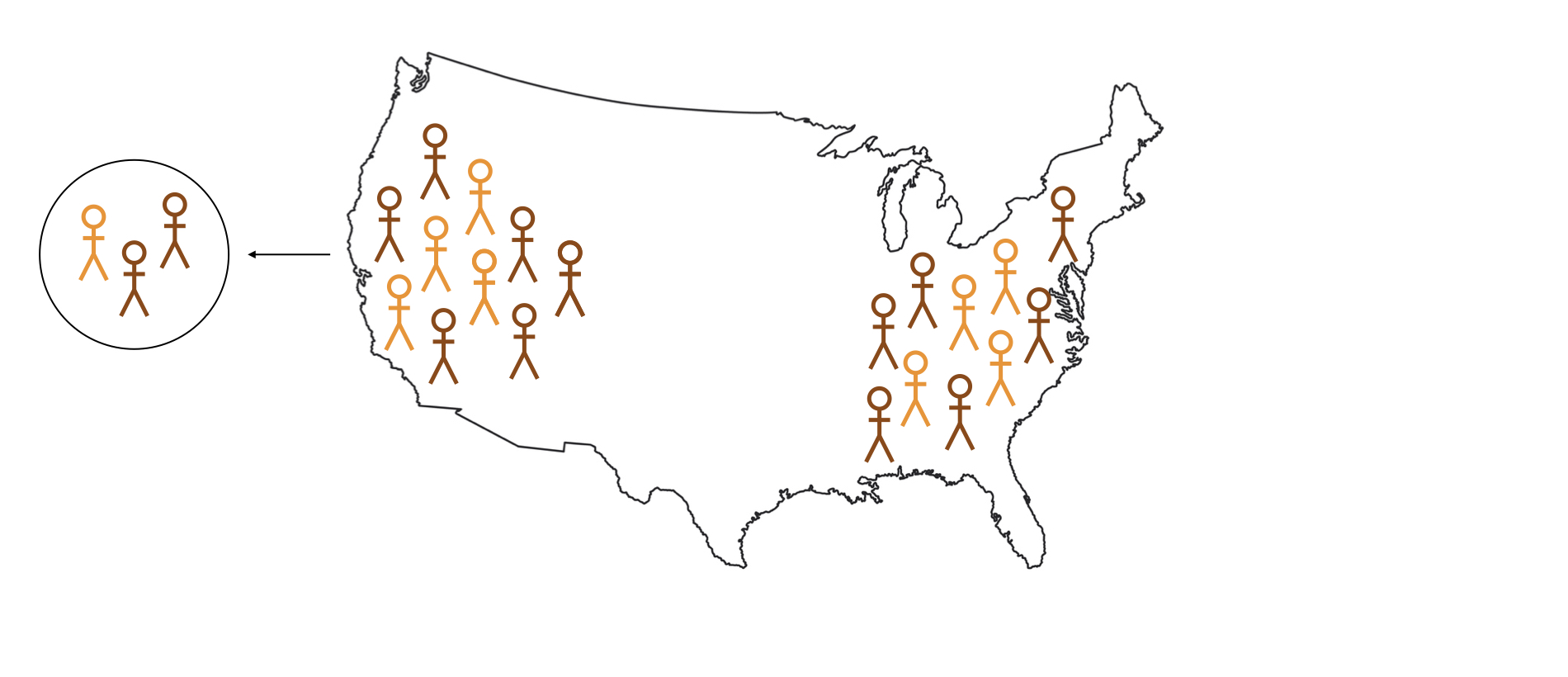
Logika inferensi
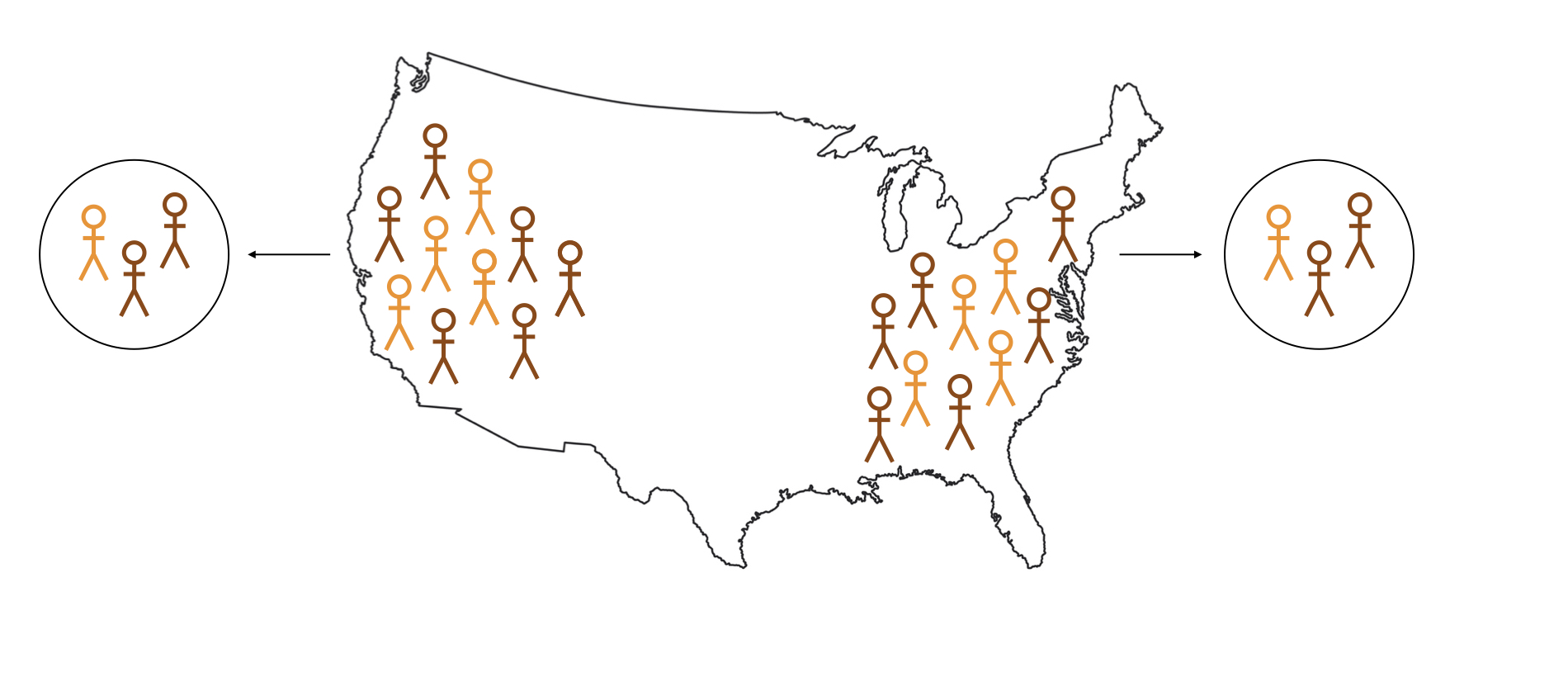
Logika inferensi
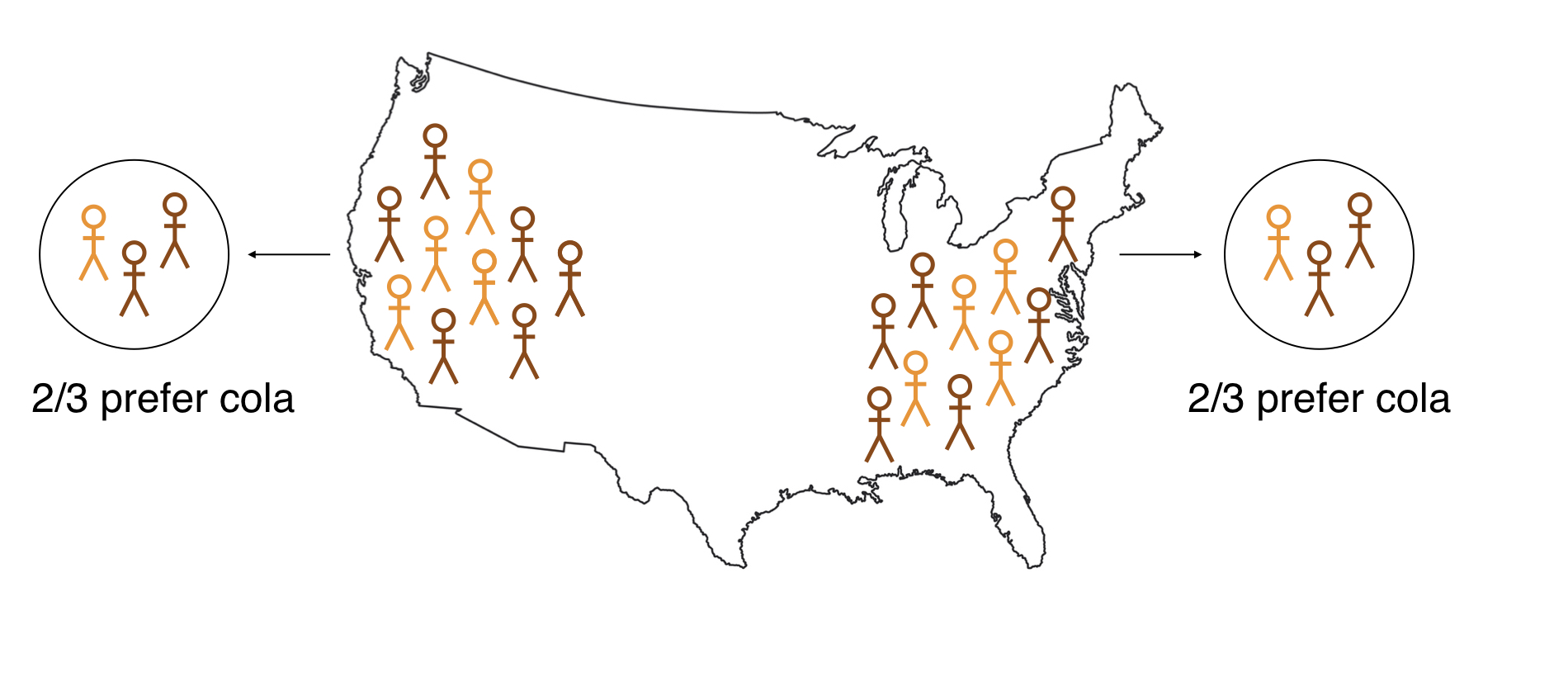
Logika inferensi
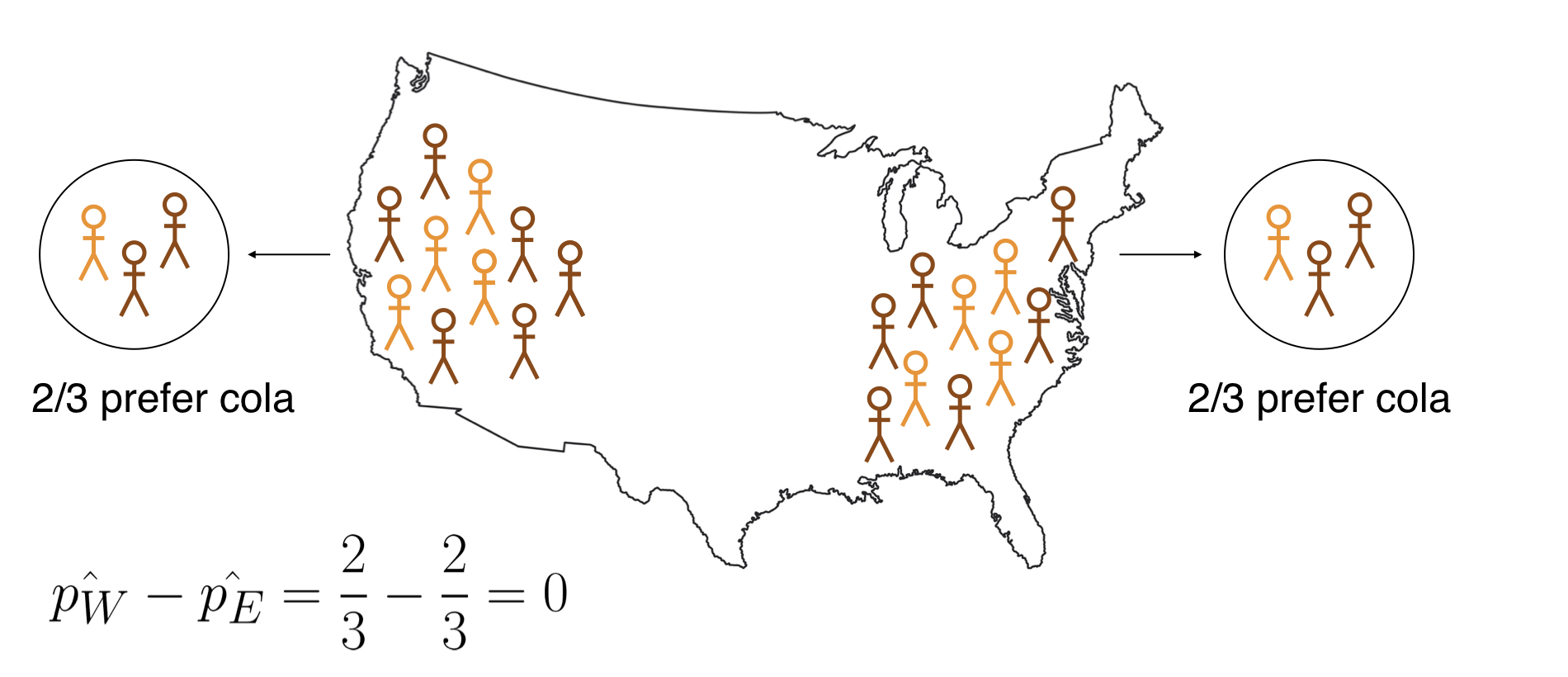
Logika inferensi
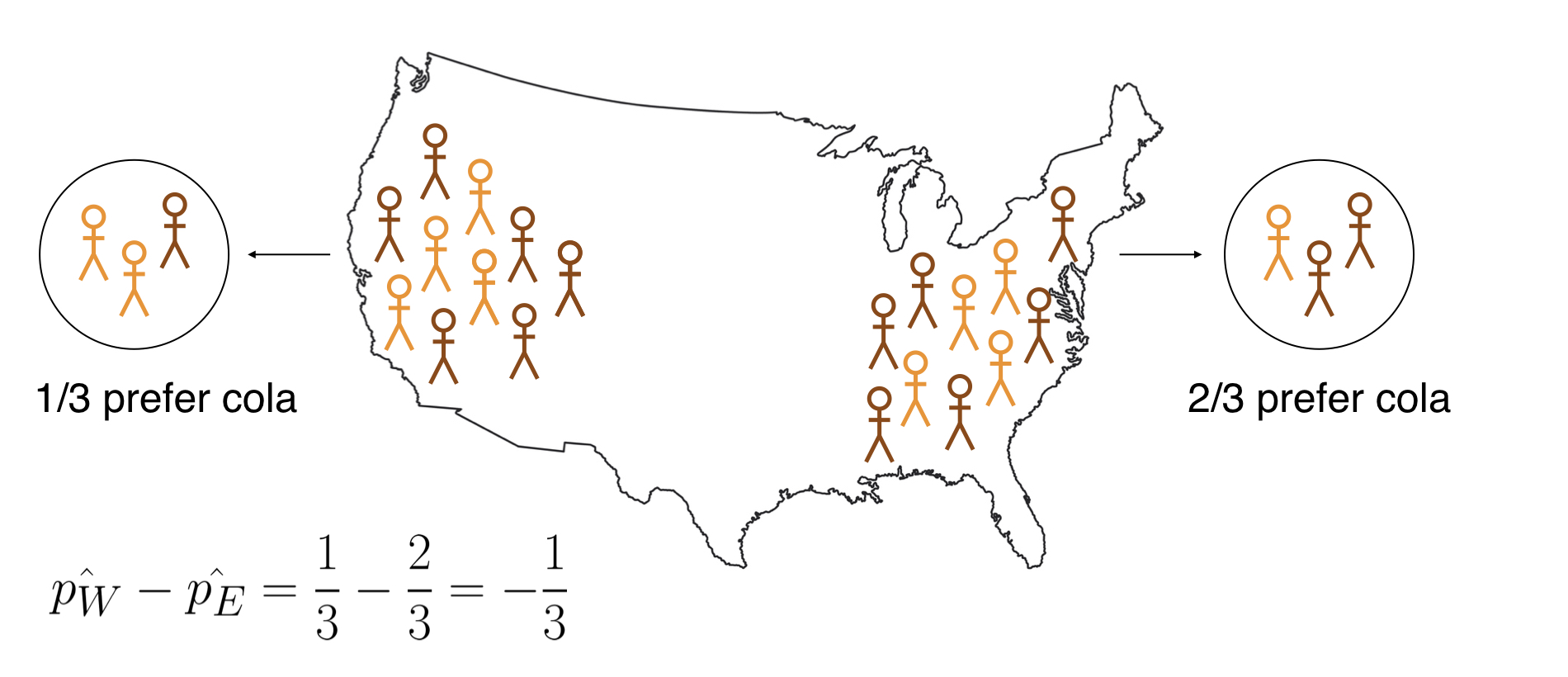
Memahami distribusi nol
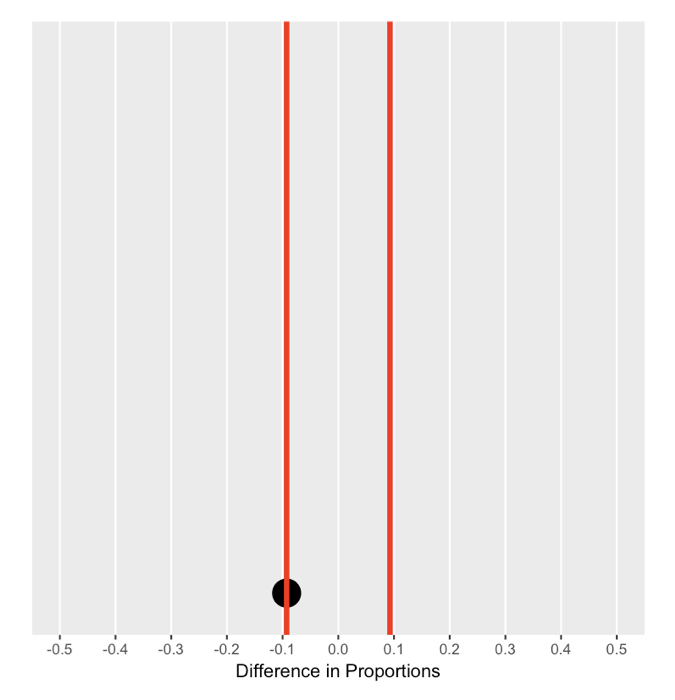
Memahami distribusi nol
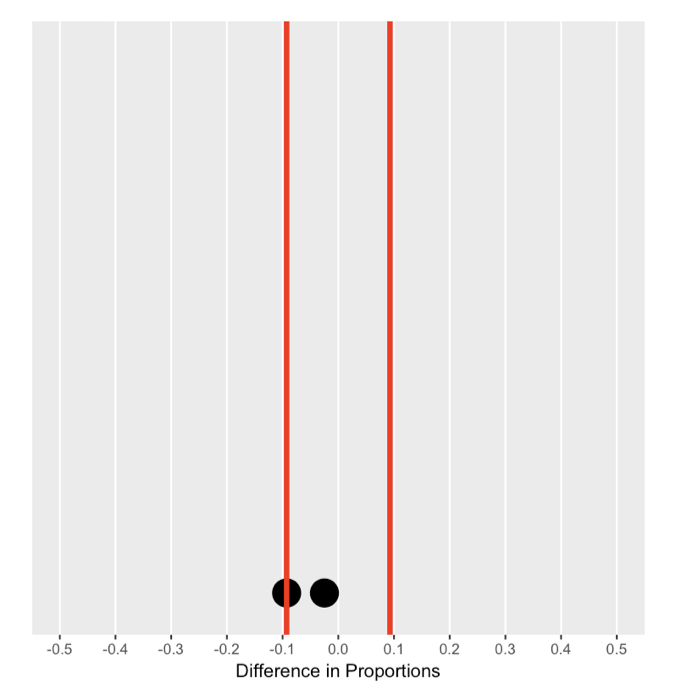
Memahami distribusi nol
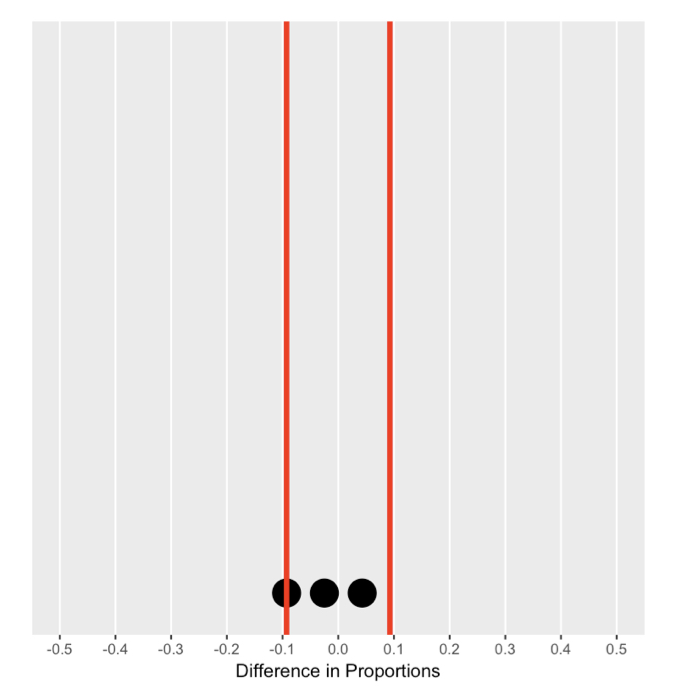
Memahami distribusi nol
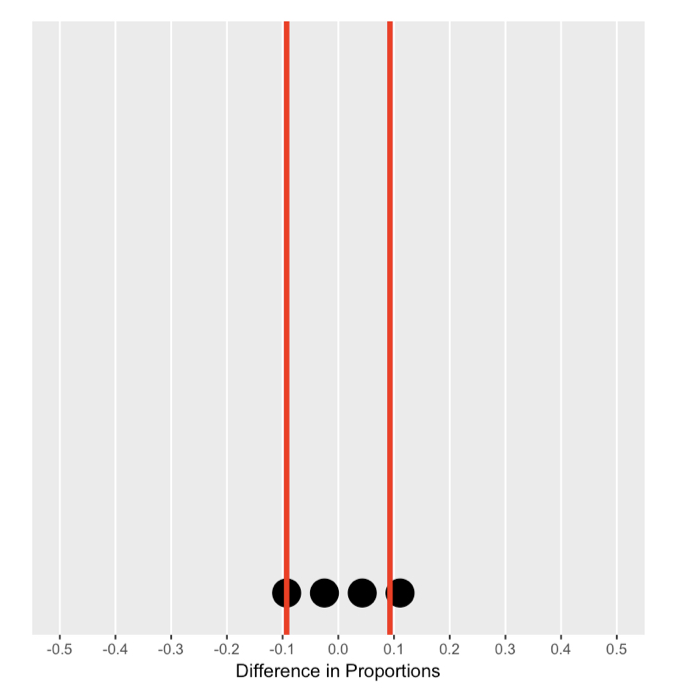
Memahami distribusi nol
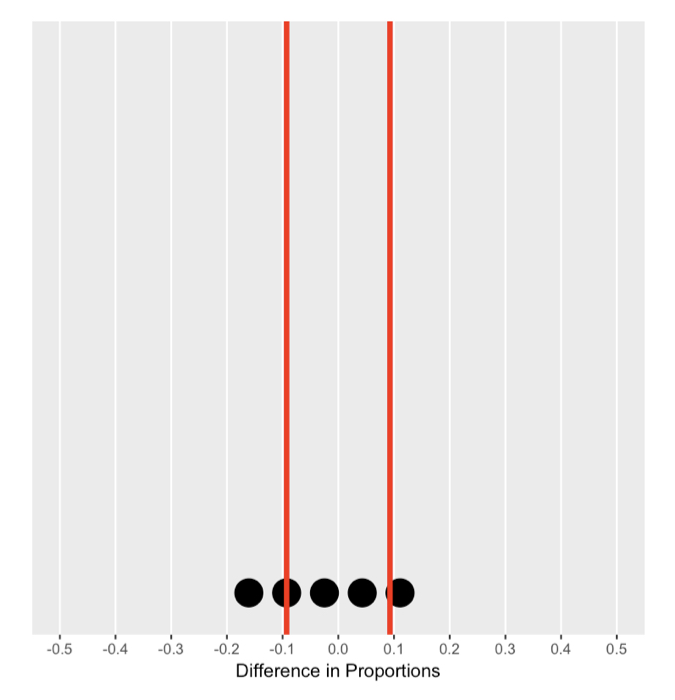
Memahami distribusi nol
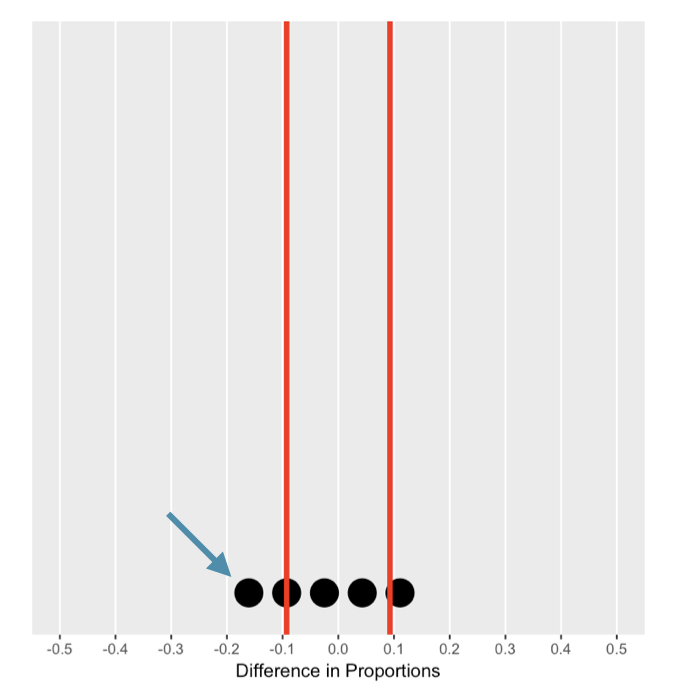
Memahami distribusi nol
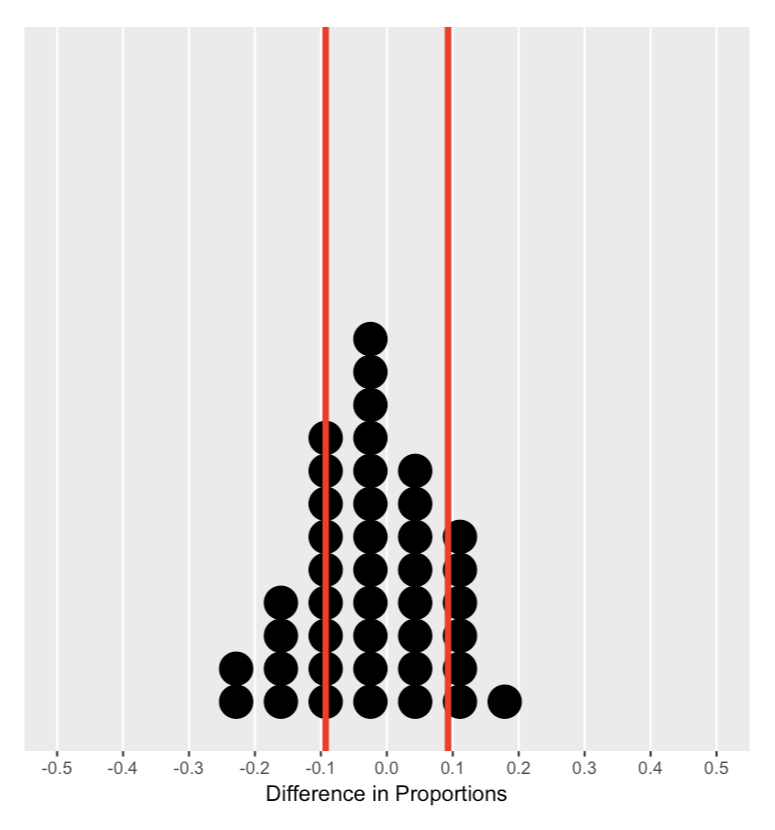
Memahami distribusi nol
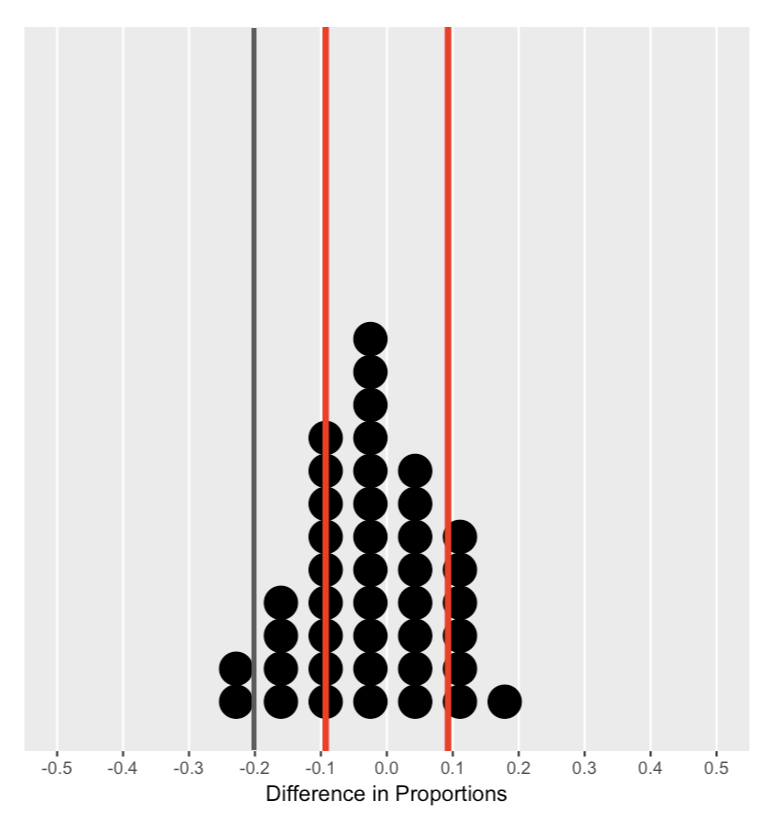
Memahami distribusi nol
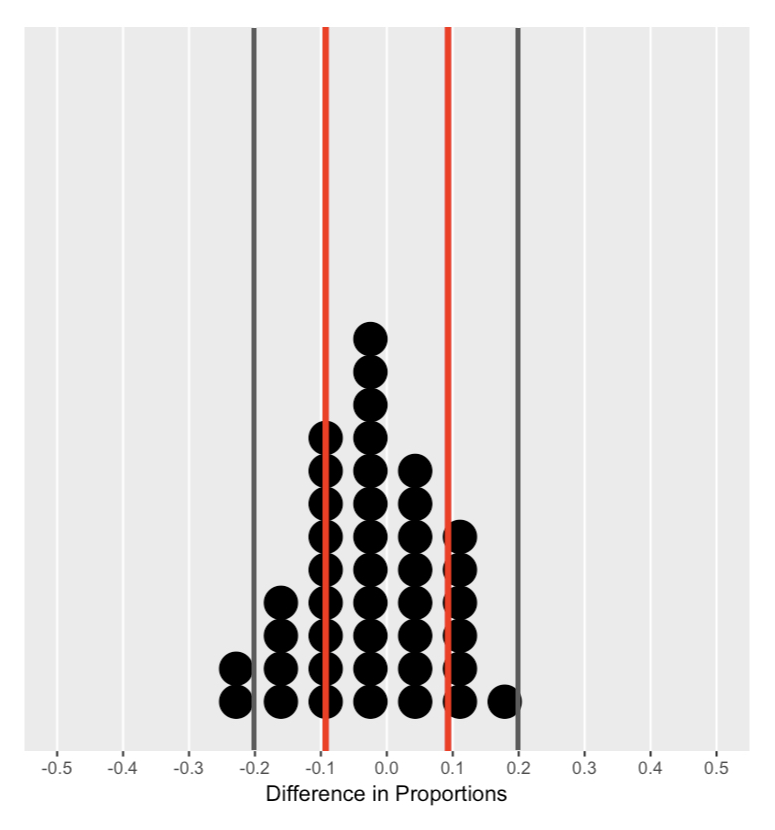
Memahami distribusi nol
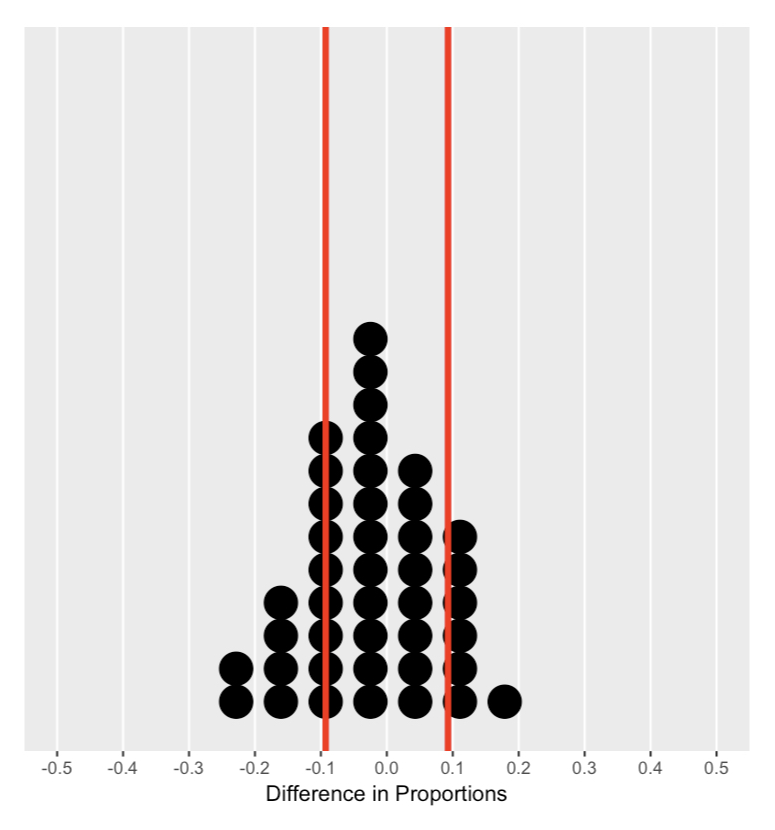
Memahami distribusi nol
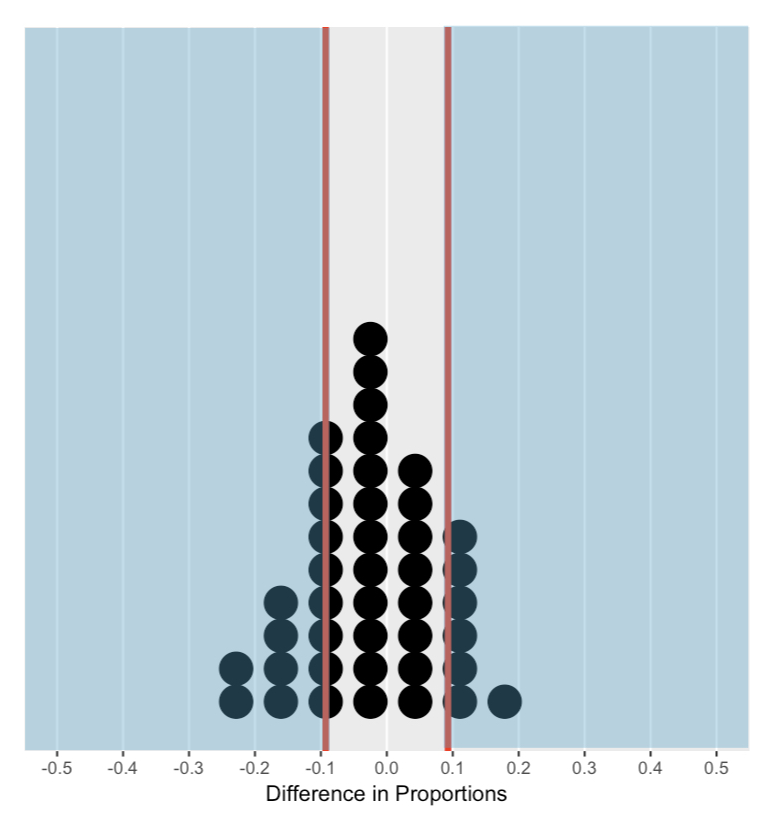
Memahami distribusi nol
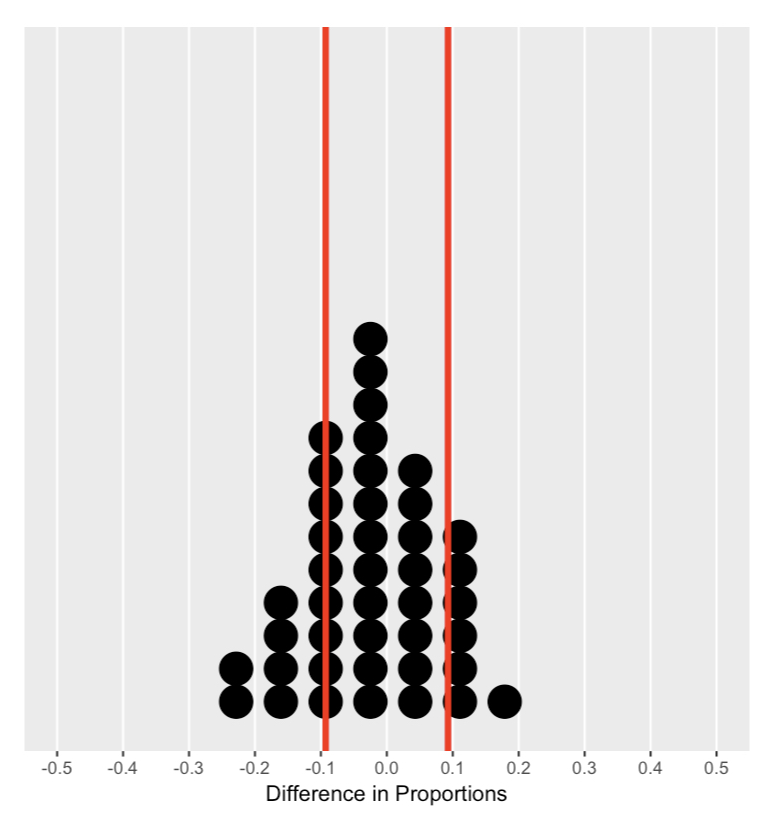
Distribusi acak