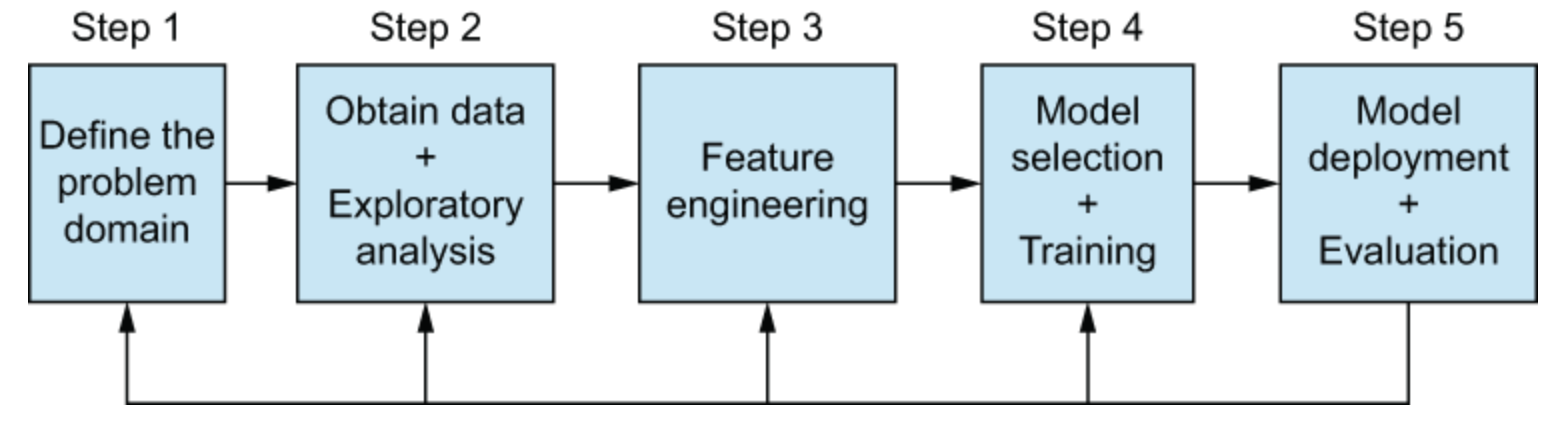
Rekayasa fitur
Mengembangkan Model Machine Learning untuk Produksi

Sinan Ozdemir
Data Scientist and Author
Pengantar rekayasa fitur
- Mentransformasi data latih untuk memaksimalkan kinerja pipeline ML
- Mengurangi kompleksitas komputasi
- Contoh
- Menggabungkan data dari banyak sumber
- Membangun fitur baru
- Menerapkan transformasi fitur
1 https://www.manning.com/books/feature-engineering-bookcamp
Menggabungkan data dari banyak sumber
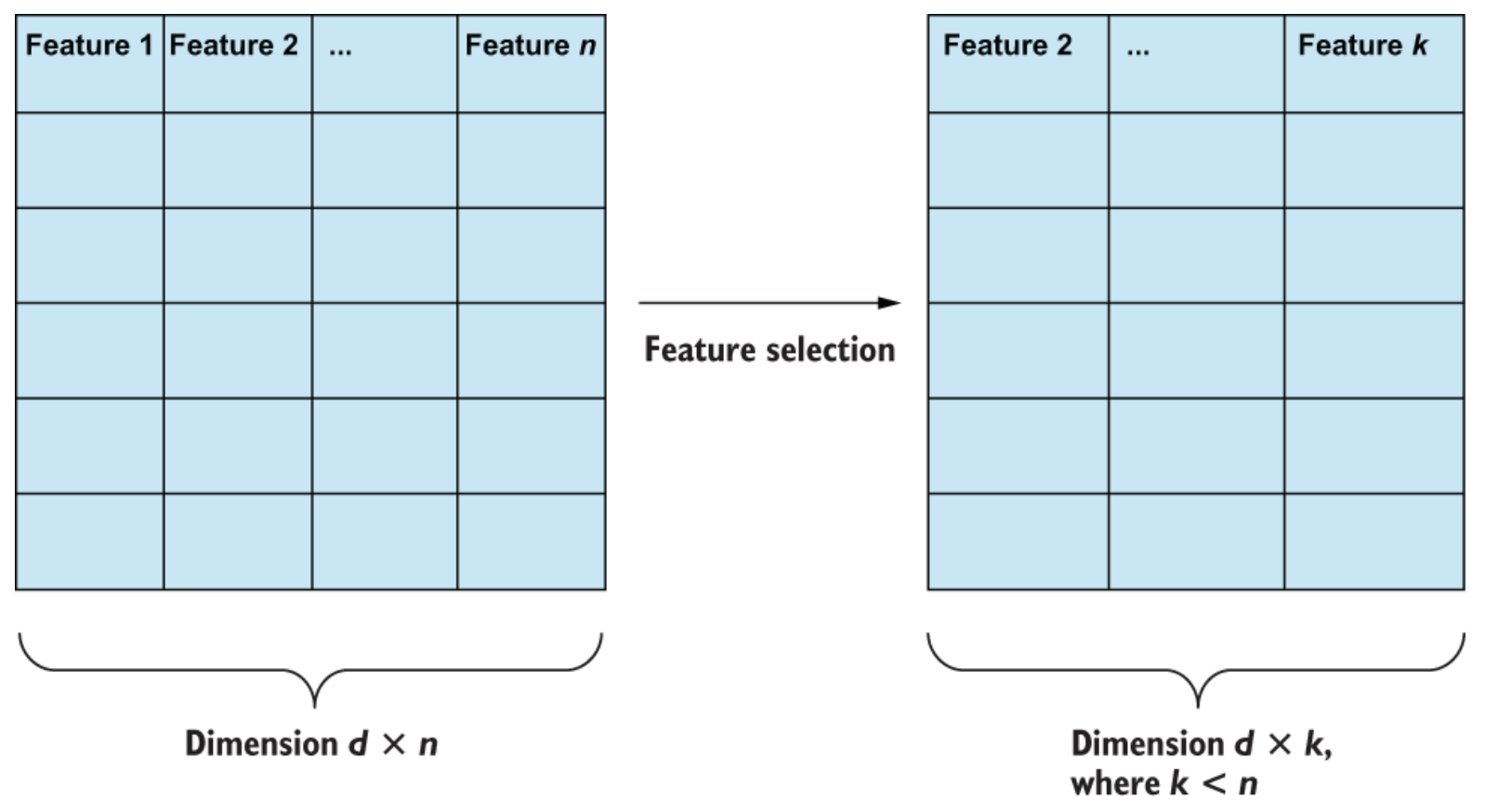
Seleksi fitur
1 https://www.manning.com/books/feature-engineering-bookcamp
Pelajari lebih lanjut tentang rekayasa fitur


