Metode pendeteksian kecurangan berbasis klaster lainnya
Deteksi Kecurangan di Python

Charlotte Werger
Data Scientist
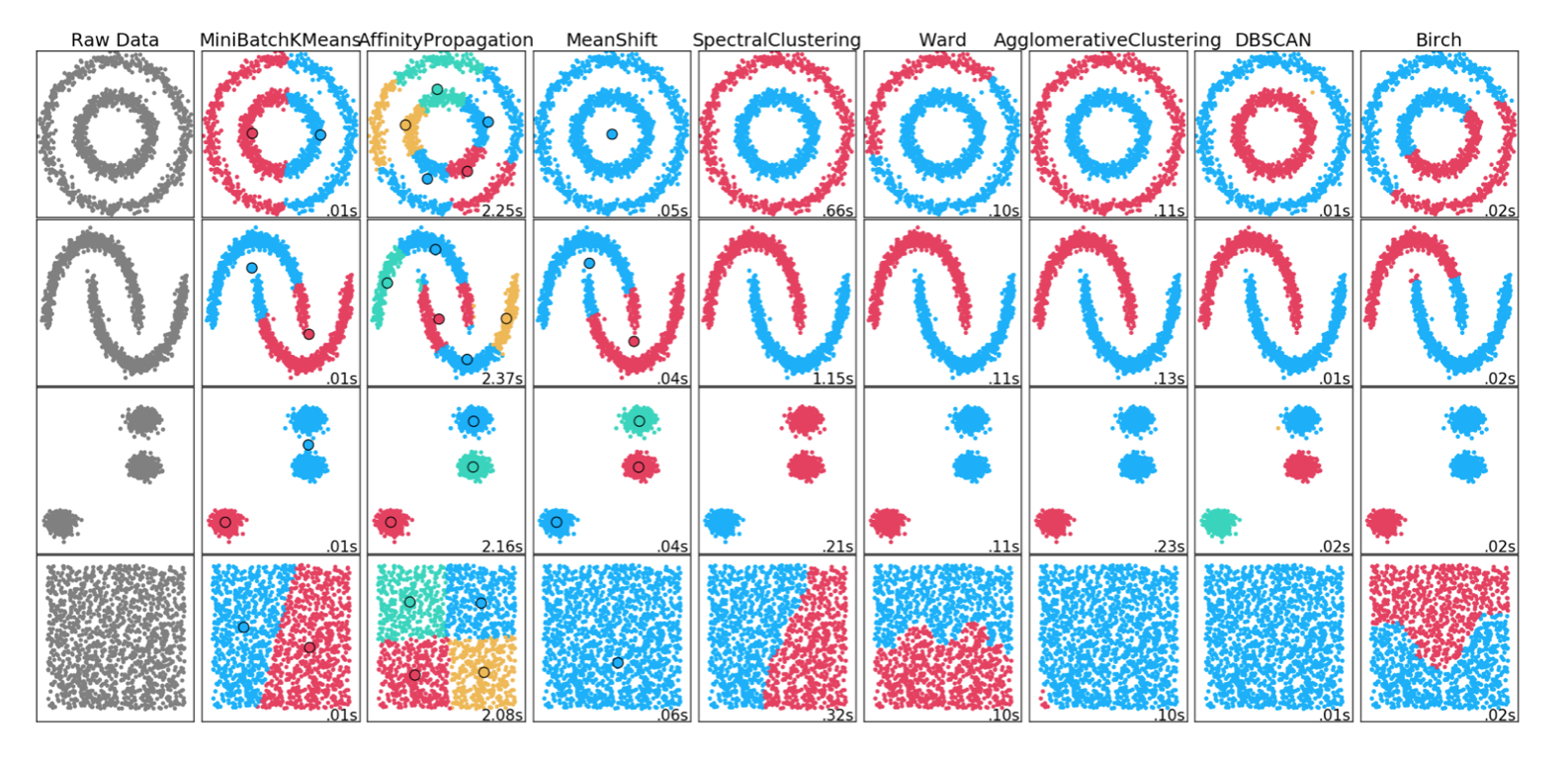
Ada banyak metode pengelompokan
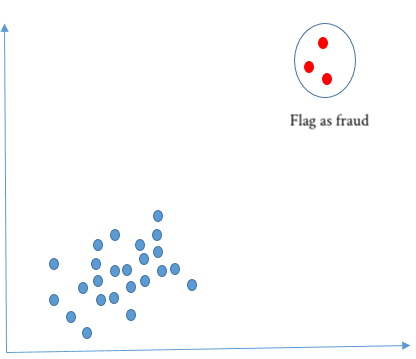
Cara menandai kecurangan: gunakan klaster terkecil
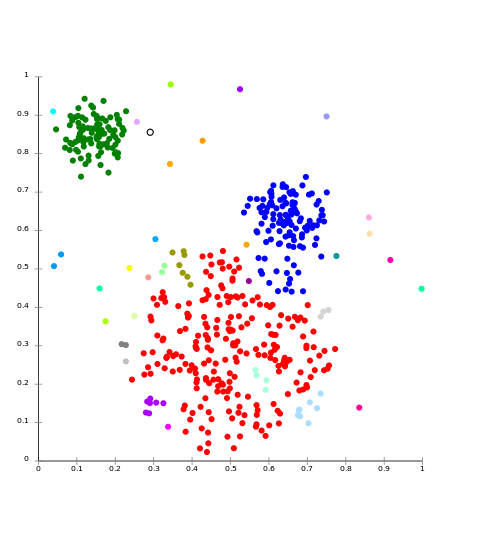
Kenyataannya lebih seperti ini
Deteksi Kecurangan di Python
Charlotte Werger
Data Scientist

