Deteksi Kecurangan di Python
Charlotte Werger
Data Scientist
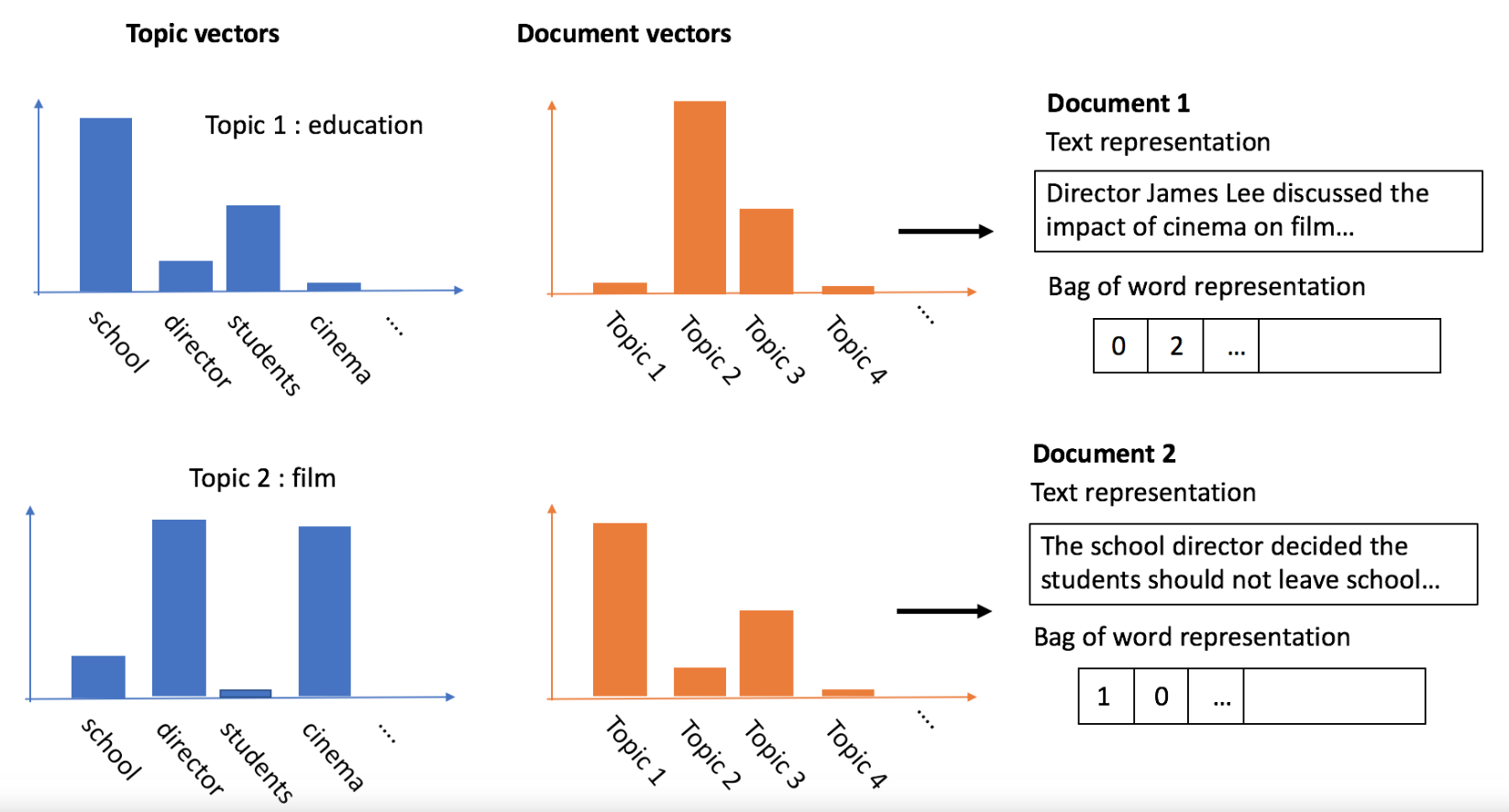
Dengan LDA Anda mendapatkan:
Membangun model topik Anda:
from gensim import corpora
# Create dictionary number of times a word appears dictionary = corpora.Dictionary(cleaned_emails)
# Filter out (non)frequent words dictionary.filter_extremes(no_below=5, keep_n=50000)
# Create corpus corpus = [dictionary.doc2bow(text) for text in cleaned_emails]
import gensim # Define the LDA model ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = 3, id2word=dictionary, passes=15)
# Print the three topics from the model with top words topics = ldamodel.print_topics(num_words=4) for topic in topics: print(topic)
(0, 0.029*"email" + 0.016*"send" + 0.016*"results" + 0.016*"invoice") (1, 0.026*"price" + 0.026*"work" + 0.026*"management" + 0.026*"sell") (2, 0.029*"distribute" + 0.029*"contact" + 0.016*"supply" + 0.016*"fast")