<html>
<body>
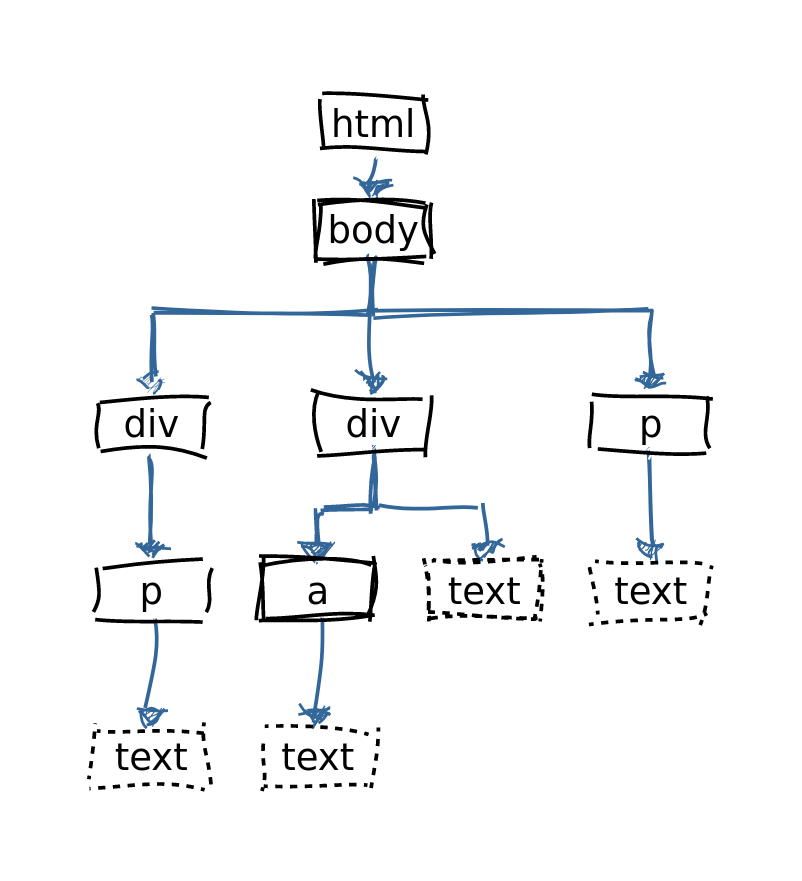
<div>
<p>Paragraf pertama.</p>
</div>
<div>
Bukan paragraf sebenarnya,
tetapi ada <a href="#">tautan</a>.
</div>
<p>Paragraf tanpa
div pembungkus.</p>
</body>
</html>
HTML seperti pohon
<html>
<body>
<div>
<p>Paragraf pertama.</p>
</div>
<div>
Bukan paragraf sebenarnya,
tetapi ada <a href="#">tautan</a>.
</div>
<p>Paragraf tanpa
div pembungkus.</p>
</body>
</html>
HTML seperti pohon
<html>
<body>
<div>
<p>Paragraf pertama.</p>
</div>
<div>
Bukan paragraf sebenarnya,
tetapi ada <a href="#">tautan</a>.
</div>
<p>Paragraf tanpa
div pembungkus.</p>
</body>
</html>
Menavigasi pohon dengan rvest
<html>
<body>
<div>
<p>Paragraf pertama.</p>
</div>
<div>
Bukan paragraf sebenarnya,
tetapi ada <a href="#">tautan</a>.
</div>
<p>Paragraf tanpa
div pembungkus.</p>
</body>
</html>
html <- read_html(html_document)
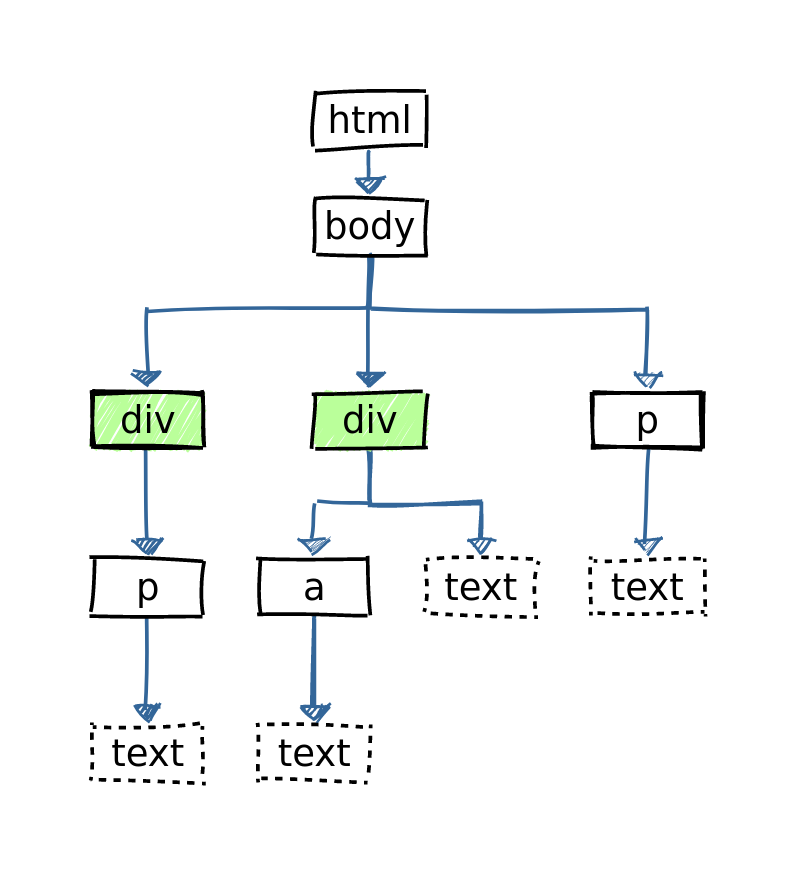
html_children(html)
{xml_nodeset (1)}
[1] <body>\n <div>\n < ...
html %>% html_children()
html %>% html_children() %>% html_text()
[1] "\n \n The first paragraph.\n
\n \n Not an actual paragraph, \n
but with a link.\n \n A paragraph ...
Menavigasi ke node dengan selektor
<html>
<body>
<div>
<p>Paragraf pertama.</p>
</div>
<div>
Bukan paragraf sebenarnya,
tetapi ada <a href="#">tautan</a>.
</div>
<p>Paragraf tanpa
div pembungkus.</p>
</body>
</html>
html <- read_html(html_document)
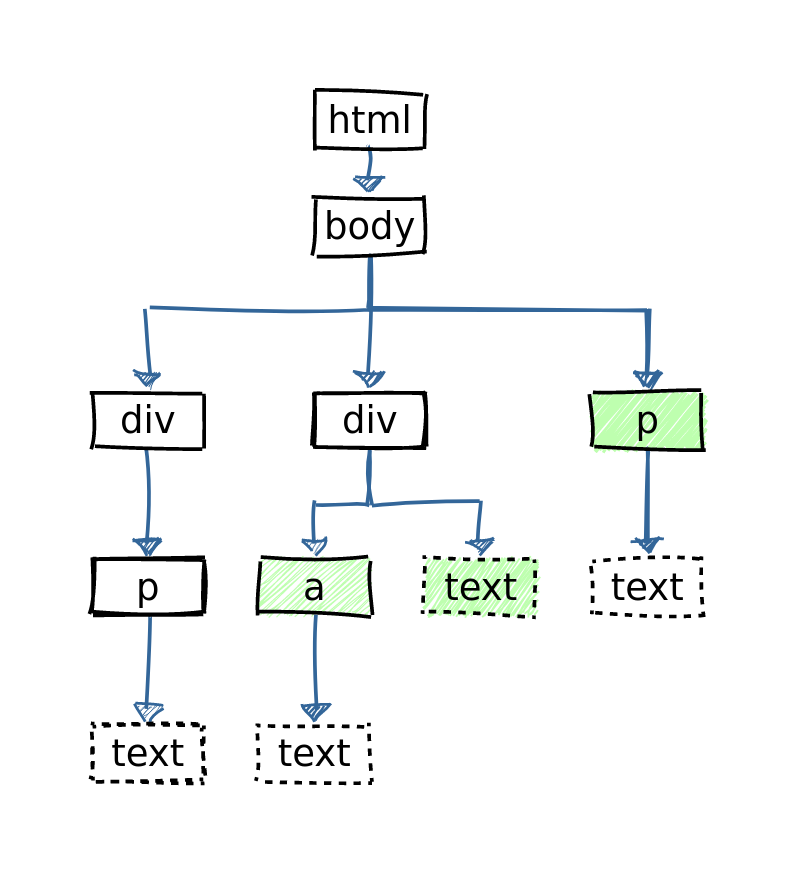
html %>% html_element('body')
{xml_nodeset (1)}
[1] <body>\n <div>\n < ...
html %>% html_elements('div p')
{xml_nodeset (1)}
[1] <p>Paragraf pertama.</p>
Menavigasi ke node dengan selektor
<html>
<body>
<div>
<p>Paragraf pertama.</p>
</div>
<div>
Bukan paragraf sebenarnya,
tetapi ada <a href="#">tautan</a>.
</div>
<p>Paragraf tanpa
div pembungkus.</p>
</body>
</html>
html %>% html_elements('p')
{xml_nodeset (2)}
[1] <p>Paragraf pertama.</p>
[2] <p>Paragraf tanpa div pembun...
html %>% html_elements('div') %>%
html_elements('p')