Memprediksi transaksi pelanggan
Machine Learning untuk Pemasaran dengan Python

Karolis Urbonas
Head of Analytics & Science, Amazon
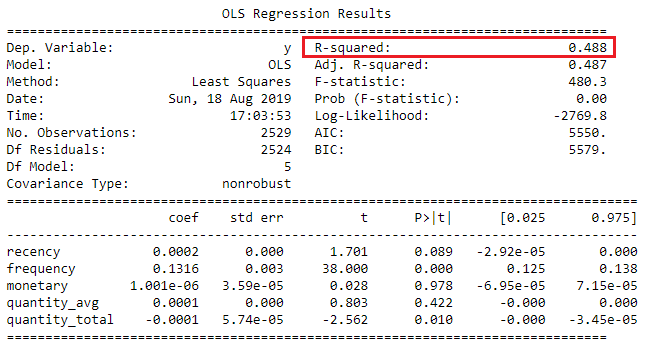
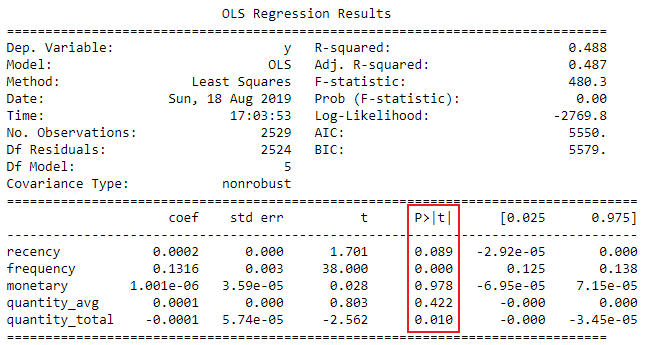
Tabel ringkasan regresi
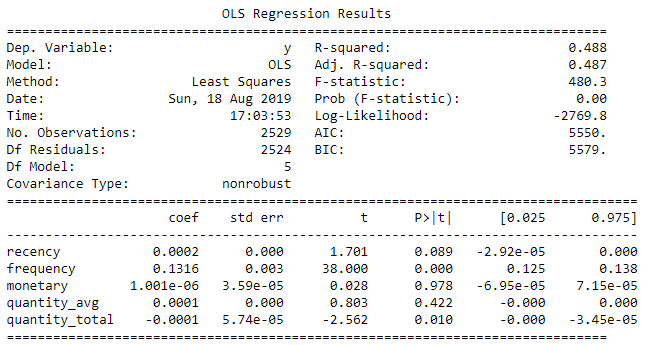
Menafsirkan R-squared
Menafsirkan p-value koefisien
Machine Learning untuk Pemasaran dengan Python
Karolis Urbonas
Head of Analytics & Science, Amazon

