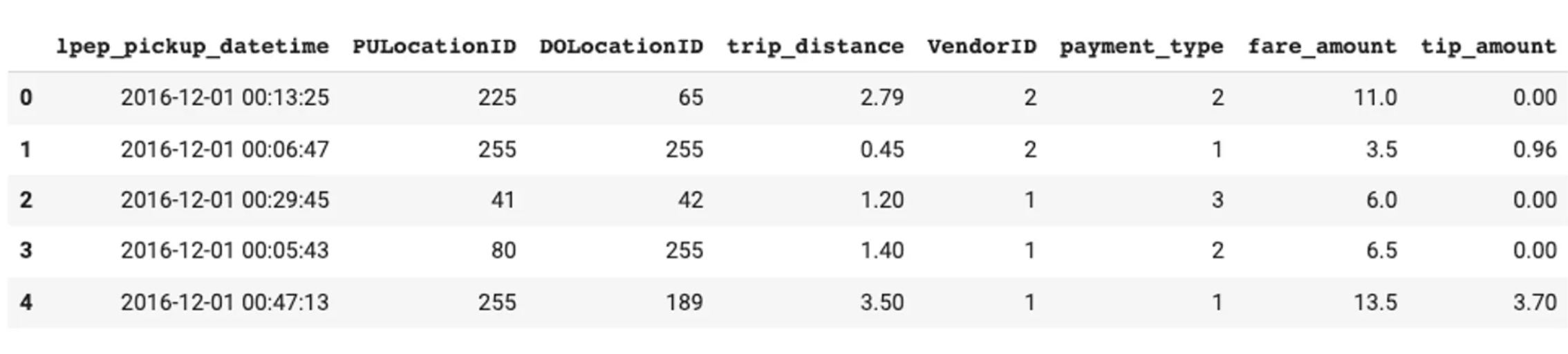
# Target column name
target = 'tip_amount'
# Features column name
features = ["PULocationID", "DOLocationID", "trip_distance", "VendorID", "pickup_time"]
# Training the model
model = LGBMRegressor(random_state=42)
model.fit(X_train, y_train)
# Making predictions
y_pred_train = model.predict(X_train)
y_pred_test = model.predict(X_test)
# Evaluating the model on train and test set
mae_train = MAE(y_train, y_pred_train)
mae_test = MAE(y_test, y_pred_test)
# Deploying the model to production
y_pred_prod = model.predict(X_prod)
Membuat set referensi dan analisis
Periode referensi
Menggunakan set uji
Memerlukan ground truth
Menetapkan kinerja baseline
Periode analisis
Data produksi terbaru
Ground truth opsional
NannyML menganalisis drift data dan kinerja
# Creating reference set
reference = X_test.copy() # Test set features
reference['y_pred'] = y_pred_test # Predictions
reference['tip_amount'] = y_test # Labels
reference = reference.join(
data['lpep_pickup_datetime']) # Timestamp
# Creating analysis set
analysis = X_prod.copy() # Production features
analysis['y_pred'] = y_pred_prod # Predictions
analysis = analysis.join(
data['lpep_pickup_datetime']) # Timestamp
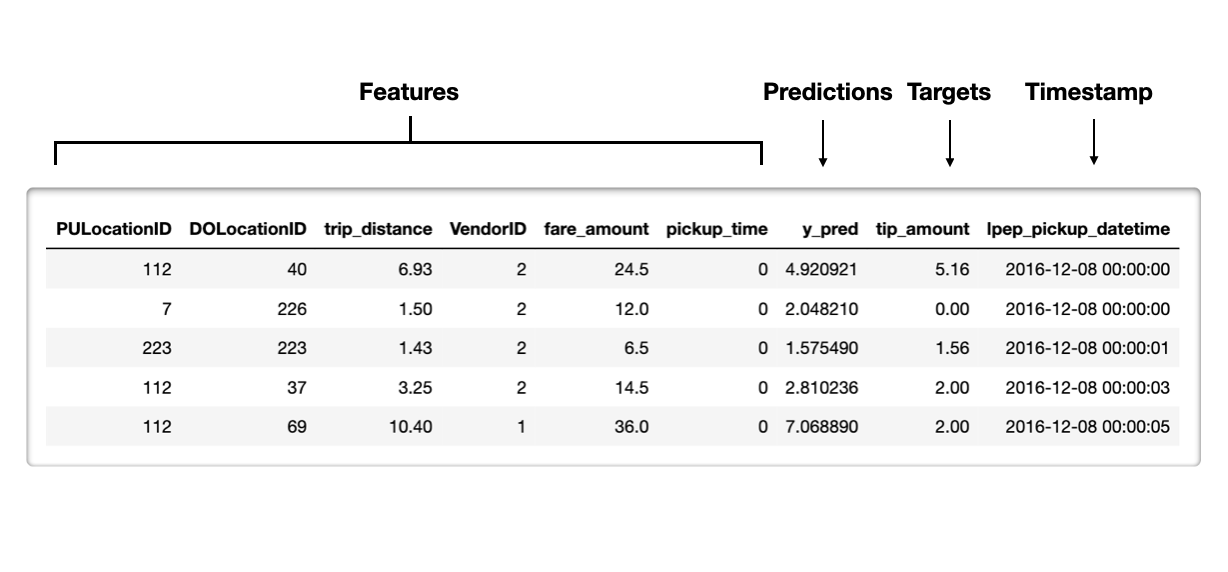
Contoh set referensi
Timestamp - waktu observasi terjadi (opsional)
Fitur - fitur yang diberikan ke model
Keluaran model
Prediksi - skor prediksi dari model
Label kelas prediksi - skor probabilitas yang ditreshold