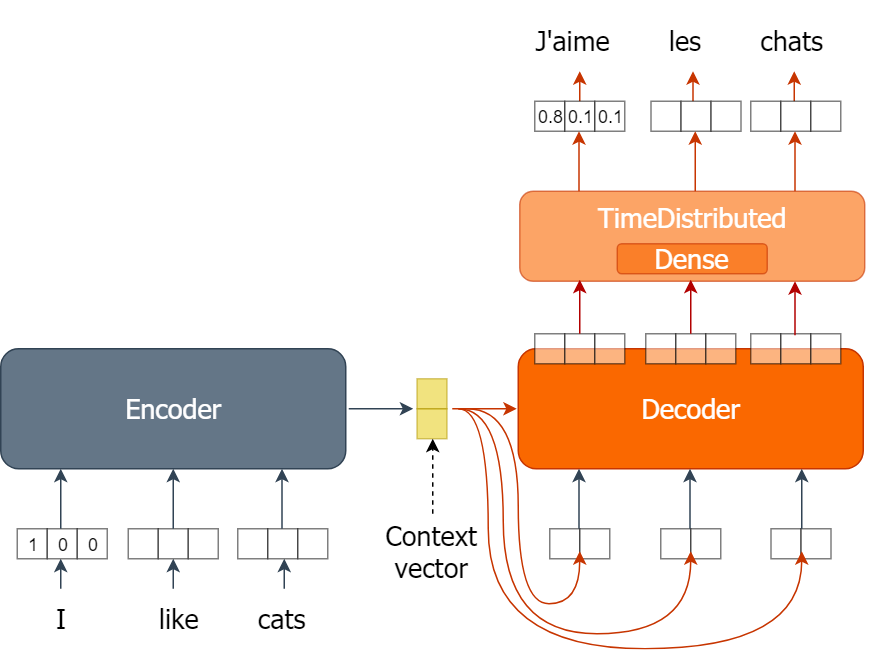
Melatih model NMT
Penerjemahan Mesin dengan Keras

Thushan Ganegedara
Data Scientist and Author
Meninjau ulang model
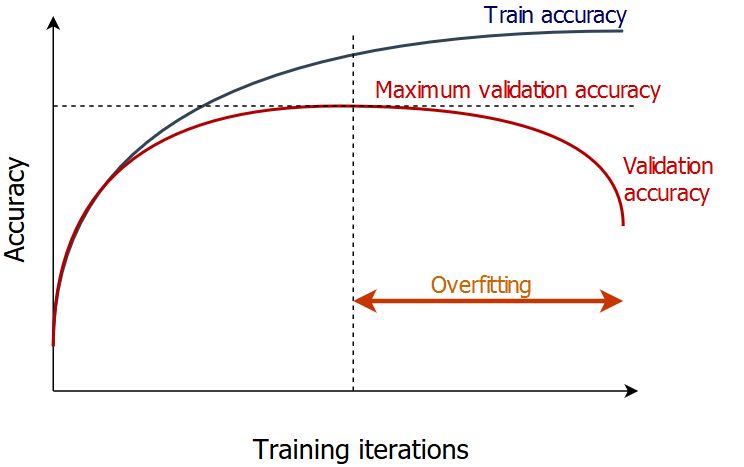
Menghindari overfitting
- Bagi dataset menjadi dua bagian
- Training set - untuk melatih model
- Validation set - untuk memantau akurasi model
- Hentikan pelatihan saat akurasi validasi tidak lagi meningkat.