Membersihkan dan memroses teks
Text Mining dengan Bag-of-Words di R

Ted Kwartler
Instructor
Fungsi praproses umum
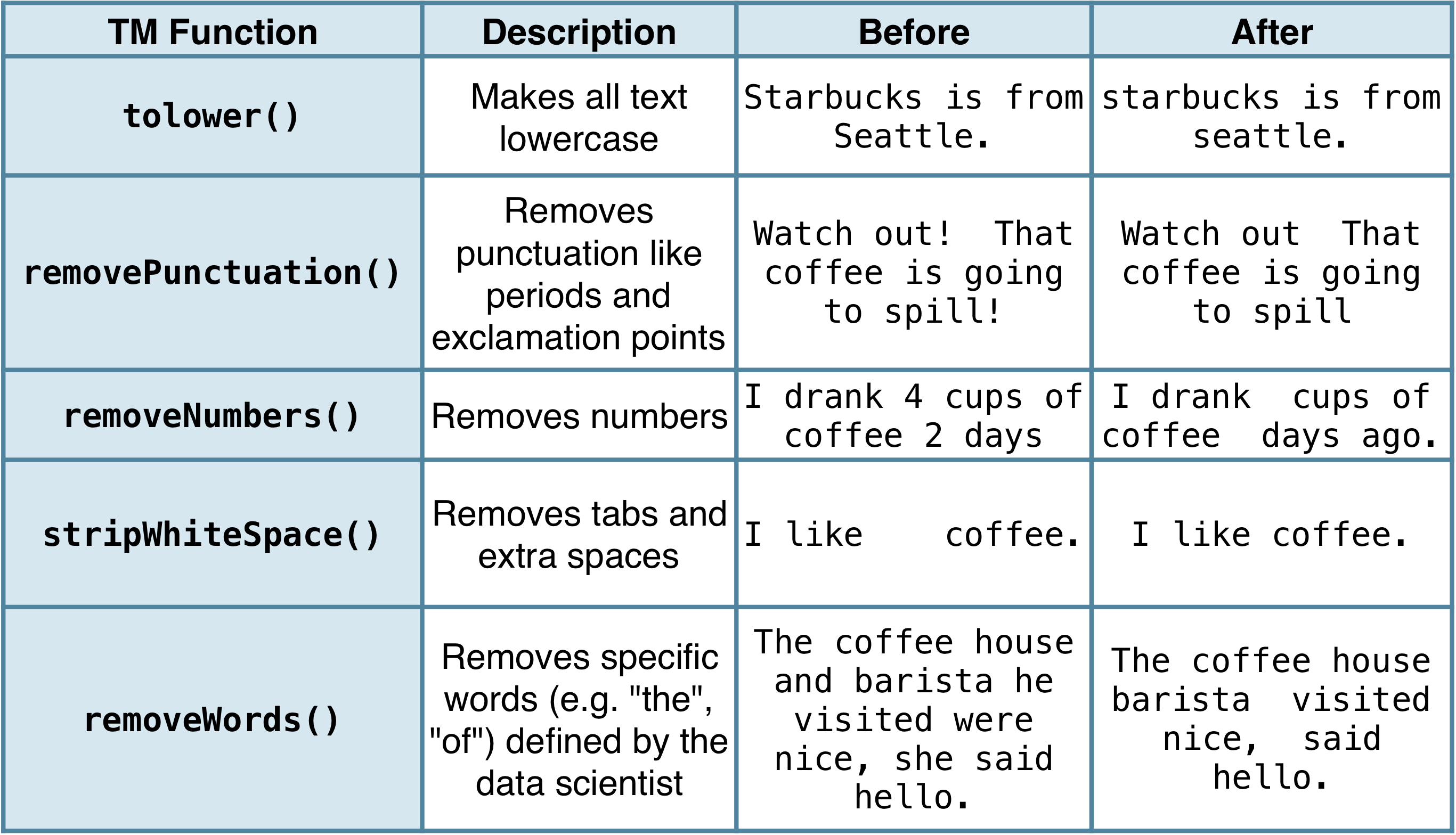
Praproses dalam praktik
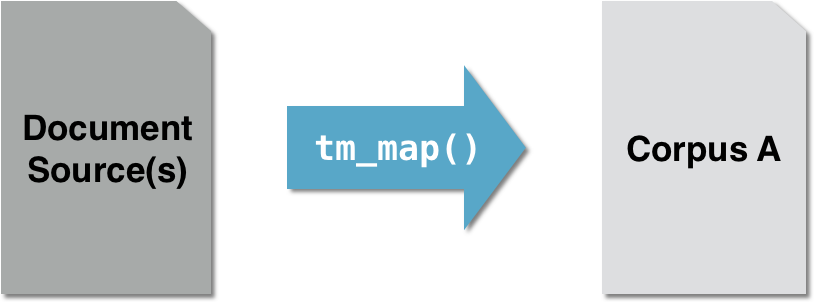
# Buat sumber vektor: coffee_source coffee_source <- VectorSource(coffee_tweets)# Buat korpus volatil: coffee_corpus coffee_corpus <- VCorpus(coffee_source)# Terapkan berbagai fungsi praproses tm_map(coffee_corpus, removeNumbers) tm_map(coffee_corpus, removePunctuation)tm_map(coffee_corpus, content_transformer(replace_abbreviation))

