Kriteria frekuensi berbeda
Text Mining dengan Bag-of-Words di R

Ted Kwartler
Instructor
Bobot istilah

Bobot istilah
# Standard term weighting
tf_tdm <- TermDocumentMatrix(text_corp)
tf_tdm_m <- as.matrix(tf_dtm)
tf_tdm_m[505:510, 5:10]
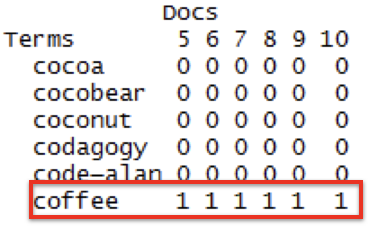
# TfIdf weighting
tf_idf_tdm <- TermDocumentMatrix(text_corp,
control = list(weighting = weightTfIdf))
tf_idf_tdm_m <- as.matrix(tf_idf_dtm)
tf_tdm_m <- as.matrix(tf_dtm)


