Mengukur Segregasi: Indeks Dissimilarity
Menganalisis Data Sensus AS dengan Python

Lee Hachadoorian
Asst. Professor of Instruction, Temple University
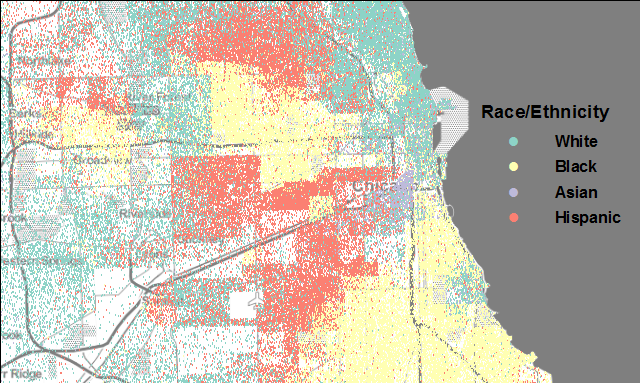
Apa itu Segregasi?
Rumus Indeks Dissimilarity
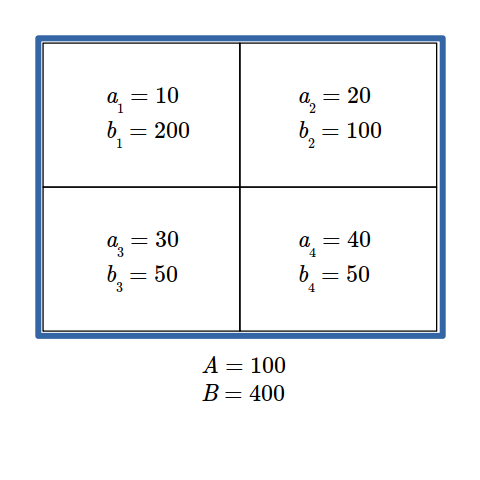
Rumus Indeks Dissimilarity
Rumus Indeks Dissimilarity
Rumus Indeks Dissimilarity
Rumus Indeks Dissimilarity
Rumus Indeks Dissimilarity
Rumus Indeks Dissimilarity
Rumus Indeks Dissimilarity
Rumus Indeks Dissimilarity
Rumus Indeks Dissimilarity

