Pipeline pembelajaran terawasi
Merancang Alur Kerja Machine Learning di Python

Dr. Chris Anagnostopoulos
Honorary Associate Professor
Data berlabel
- Variabel fitur (singkatan:
X) - Label atau kelas (singkatan:
y)
credit_scoring.head(4)
checking_status duration ... foreign_worker class
0 '<0' 6 ... yes good
1 '0<=X<200' 48 ... yes bad
2 'no checking' 12 ... yes good
3 '<0' 42 ... yes good
Rekayasa fitur
- Kebanyakan pengklasifikasi mengharapkan fitur numerik
- Kolom string perlu diubah ke angka
Pramuat dengan LabelEncoder dari sklearn.preprocessing:
le = LabelEncoder()
le.fit_transform(credit_scoring['checking_status'])[:4]
array([1, 0, 3, 1])
Pelatihan model
.fit(features, labels).predict(features)
features, labels = credit_scoring.drop('class', 1), credit_scoring['class']model_nb = GaussianNB() model_nb.fit(features, labels) model_nb.predict(features.head(5))
['good' 'bad' 'good' 'bad' 'good']
Akurasi 60% pada 5 contoh pertama.
Pemilihan model
.fit()mengoptimalkan parameter model- Bagaimana dengan model lain?
AdaBoostClassifier mengungguli GaussianNB pada lima titik data pertama:
model_ab = AdaBoostClassifier()
model_ab.fit(features, labels)
model_ab.predict(features.head(5))
numpy.array(labels[0:5])
['good' 'bad' 'good' 'good' 'bad']
['good' 'bad' 'good' 'good' 'bad']
Penilaian kinerja
Ukuran sampel lebih besar => estimasi akurasi lebih baik:
from sklearn.metrics import accuracy_score
accuracy_score(labels, model_nb.predict(features)) # naive bayes
0.706
accuracy_score(labels, model_ab.predict(features)) # adaboost
0.802
Apa yang salah dengan perhitungan ini?
Overfitting dan pemisahan data
Overfitting: model selalu tampil lebih baik pada data latih dibanding data yang belum pernah dilihat.
Latih pada X_train, y_train, nilai akurasi pada X_test, y_test:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)GaussianNB().fit(X_train, y_train).predict(X_test)
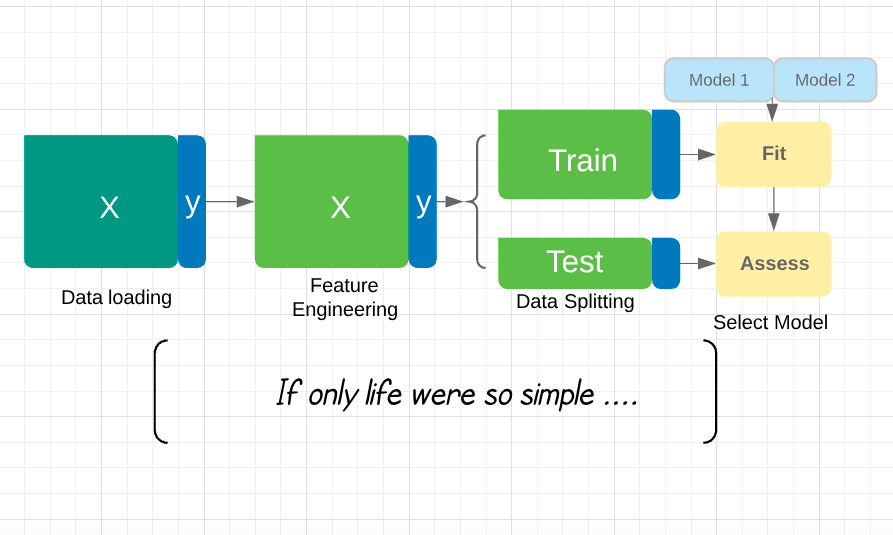
Jadi, apa isi kursus ini?
- Cara skala untuk menyetel pipeline Anda.
- Memastikan prediksi relevan dengan melibatkan pakar domain.
- Memastikan model tetap berkinerja baik seiring waktu.
- Melatih model saat label tidak cukup.
Bisakah Anda mencegah krisis KPR?
Merancang Alur Kerja Machine Learning di Python

