LDA dalam praktik
Pengantar Natural Language Processing di R

Kasey Jones
Research Data Scientist
Finalisasi hasil LDA
- pilih jumlah topik
- perplexity/metric lain
- solusi yang sesuai kebutuhan Anda
Perplexity
- ukuran kecocokan model probabilitas pada data baru
- makin rendah makin baik
- digunakan untuk membandingkan model
- Dalam penalaan parameter LDA
- Memilih jumlah topik
sample_size <- floor(0.90 * nrow(doc_term_matrix))
set.seed(1111)
train_ind <- sample(nrow(doc_term_matrix), size = sample_size)
train <- matrix[train_ind, ]
test <- matrix[-train_ind, ]
1 https://en.wikipedia.org/wiki/Perplexity
Perplexity di R
library(topicmodels)
values = c()
for(i in c(2:35)){
lda_model <- LDA(train, k = i, method = "Gibbs",
control = list(iter = 25, seed = 1111))
values <- c(values, perplexity(lda_model, newdata = test))
}
plot(c(2:35), values, main="Perplexity for Topics",
xlab="Number of Topics", ylab="Perplexity")
Perplexity lagi!
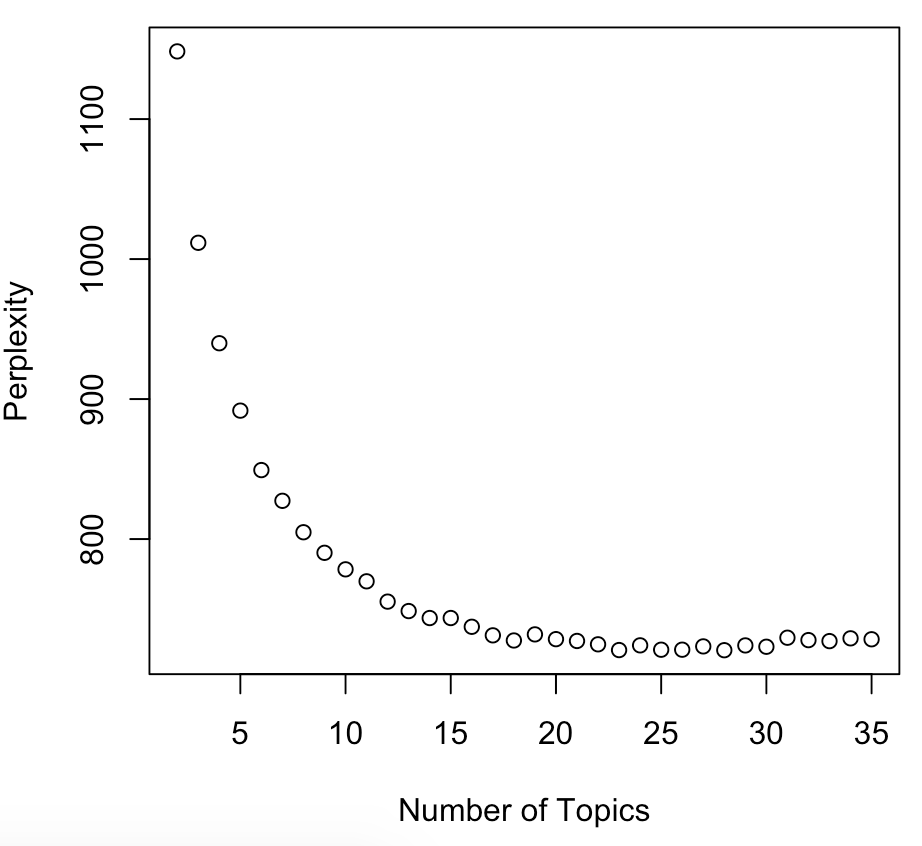
Pemilihan praktis
- Berapa topik yang sesuai untuk situasinya
- 20 topik mungkin sulit dicakup
- Bagaimana Anda menampilkan hasil
- Grafik dengan 5 topik lebih mudah daripada 100 topik
- Aturan praktis:
- Gunakan sedikit topik, tiap topik diwakili beberapa dokumen
- Jumlah topik besar hanya jika ada waktu untuk menelaah tiap topik
Menggunakan hasil
- Tinjau atau minta peninjau menemukan "tema" tiap topik
- beri peninjau daftar kata teratas dalam topik
- beri peninjau daftar dokumen teratas untuk topik itu
Meninjau output
betas <- tidy(lda_model, matrix = "beta")
betas %>%
filter(topic == 1) %>%
arrange(desc(beta)) %>%
select(term)
# A tibble: 2,000 x 1
term
<chr>
1 athletic
2 quick
3 strong
4 tough
...
gammas <- tidy(lda_model, matrix = "gamma")
gammas %>%
filter(topic == 1) %>%
arrange(desc(gamma)) %>%
select(document)
# A tibble: 1,000 x 1
document
<chr>
1 232
2 292
3 921
4 643
5 468
Meringkas output
gammas <- tidy(lda_model, matrix = "gamma")
gammas %>%
group_by(document) %>%
arrange(desc(gamma)) %>%
slice(1) %>%
group_by(topic) %>%
tally(topic, sort=TRUE)
topic n
1 1 1326
2 5 1215
3 4 804
...
Ringkas output lagi
gammas %>%
group_by(document) %>%
arrange(desc(gamma)) %>%
slice(1) %>%
group_by(topic) %>%
summarize(avg=mean(gamma)) %>%
arrange(desc(avg))
topic avg
1 1 0.696
2 5 0.530
3 4 0.482
...
Latihan LDA.
Pengantar Natural Language Processing di R

