Dask DataFrame
Pemrograman Paralel dengan Dask di Python

James Fulton
Climate Informatics Researcher
pandas DataFrame vs. Dask DataFrame
import pandas as pd# Baca satu file CSV pandas_df = pd.read_csv( "dataset/chunk1.csv" )
Ini langsung membaca satu file CSV.
import dask.dataframe as dd# Baca semua file CSV secara lazy dask_df = dd.read_csv( "dataset/*.csv" )
Ini membaca semua file CSV di folder dataset secara lazy.
Dask DataFrame
print(dask_df)
Struktur Dask DataFrame:
ID col1 col2 col3 col4 ...
npartitions=3
int64 object object int64 float64 ...
... ... ... ... ... ...
... ... ... ... ... ...
... ... ... ... ... ...
Dask Name: getitem, 3 tasks
Graf tugas Dask DataFrame
dask.visualize(dask_df)
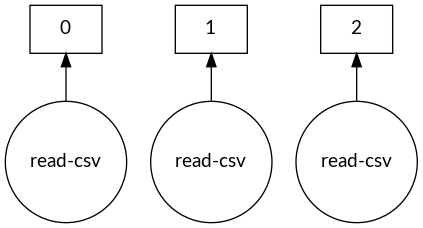
Mengontrol ukuran blok
# Setel memori maksimum per chunk dask_df = dd.read_csv("dataset/*.csv", blocksize="10MB")print(dask_df)
Struktur Dask DataFrame:
ID col1 col2 col3 col4 ...
npartitions=7
int64 object object int64 float64 ...
... ... ... ... ... ...
... ... ... ... ... ...
... ... ... ... ... ...
Dask Name: getitem, 7 tasks
Menjelaskan partisi
# Setel memori maksimum per chunk
dask_df = dd.read_csv("dataset/*.csv", blocksize="10MB")
Mengapa 7 partisi?
size file
9M dataset/chunk1.csv
18M dataset/chunk2.csv
32M dataset/chunk3.csv
Menjelaskan partisi
# Setel memori maksimum per chunk
dask_df = dd.read_csv("dataset/*.csv", blocksize="10MB")
Mengapa 7 partisi?
size file
9M dataset/chunk1.csv # menjadi 1 partisi
18M dataset/chunk2.csv # menjadi 2 partisi
32M dataset/chunk3.csv # menjadi 4 partisi
Analisis dengan Dask DataFrame
- Pilih kolom
col1 = dask_df['col1'] - Menetapkan kolom
dask_df['double_col1'] = 2 * col1 - Operasi matematis, misalnya
dask_df.std() dask_df.min()
- Groupby
dask_df.groupby(col1).mean() - Bahkan fungsi yang Anda pakai sebelumnya
dask_df.nlargest(n=3, columns='col1')
Datetime dan fungsionalitas pandas lainnya
import pandas as pd # Mengonversi string ke format datetime pd.to_datetime(pandas_df['start_date'])# Mengakses atribut datetime pandas_df['start_date'].dt.year pandas_df['start_date'].dt.day pandas_df['start_date'].dt.hour pandas_df['start_date'].dt.minute
import dask.dataframe as dd # Mengonversi string ke format datetime dd.to_datetime(dask_df['start_date'])# Mengakses atribut datetime dask_df['start_date'].dt.year dask_df['start_date'].dt.day dask_df['start_date'].dt.hour dask_df['start_date'].dt.minute
Membuat hasil tidak lazy
# Tampilkan 5 baris
print(dask_df.head())
ID double_col1 col1 col2 col3 ...
0 543795 20 10 436 0 ...
1 874535 24 12 268 0 ...
2 781326 62 31 211 0 ...
3 112457 18 9 898 1 ...
4 103256 142 71 663 0 ...
# Ubah Dask DataFrame (lazy) menjadi pandas DataFrame di memori
results_df = df.compute()
Kirim jawaban langsung ke file
# 7 partisi (chunk) jadi 7 file keluaran
dask_df.to_csv('answer/part-*.csv')
part-0.csv
part-1.csv
part-2.csv
part-3.csv
part-4.csv
part-5.csv
part-6.csv
Format file lebih cepat - Parquet
# Baca dari parquet
dask_df = dd.read_parquet('dataset_parquet')
# Simpan ke parquet
dask_df.to_parquet('answer_parquet')
- Format Parquet beberapa kali lebih cepat dibaca daripada CSV
- Bisa lebih cepat saat menulis
Ayo berlatih!
Pemrograman Paralel dengan Dask di Python

