Imputasi k-Nearest Neighbors
Menangani Data Hilang dengan Imputasi di R

Michal Oleszak
Machine Learning Engineer
Imputasi k-Nearest Neighbors
Imputasi k-Nearest Neighbors
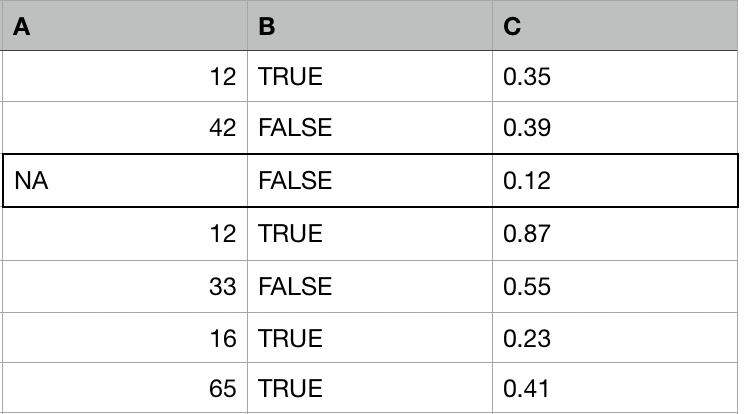
Untuk tiap observasi dengan nilai hilang:
- Temukan k observasi lain (donor, tetangga) yang paling mirip.
Imputasi k-Nearest Neighbors
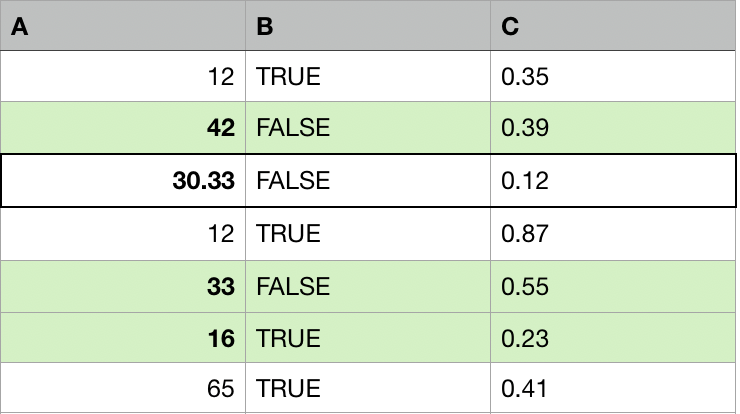
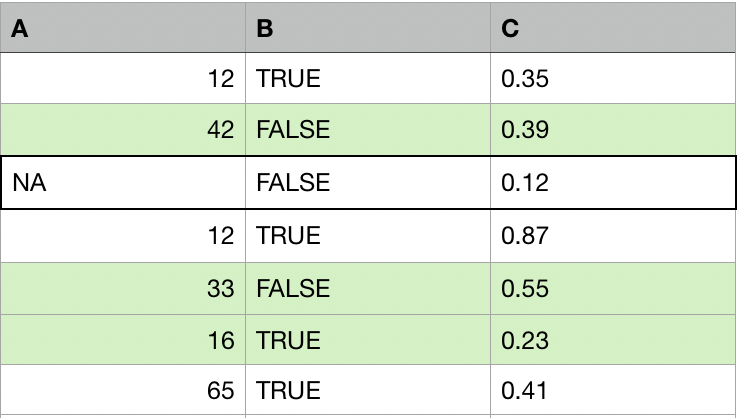
Untuk tiap observasi dengan nilai hilang:
- Temukan k observasi lain (donor, tetangga) yang paling mirip.
- Ganti nilai hilang dengan agregasi dari k donor (mean, median, mode).
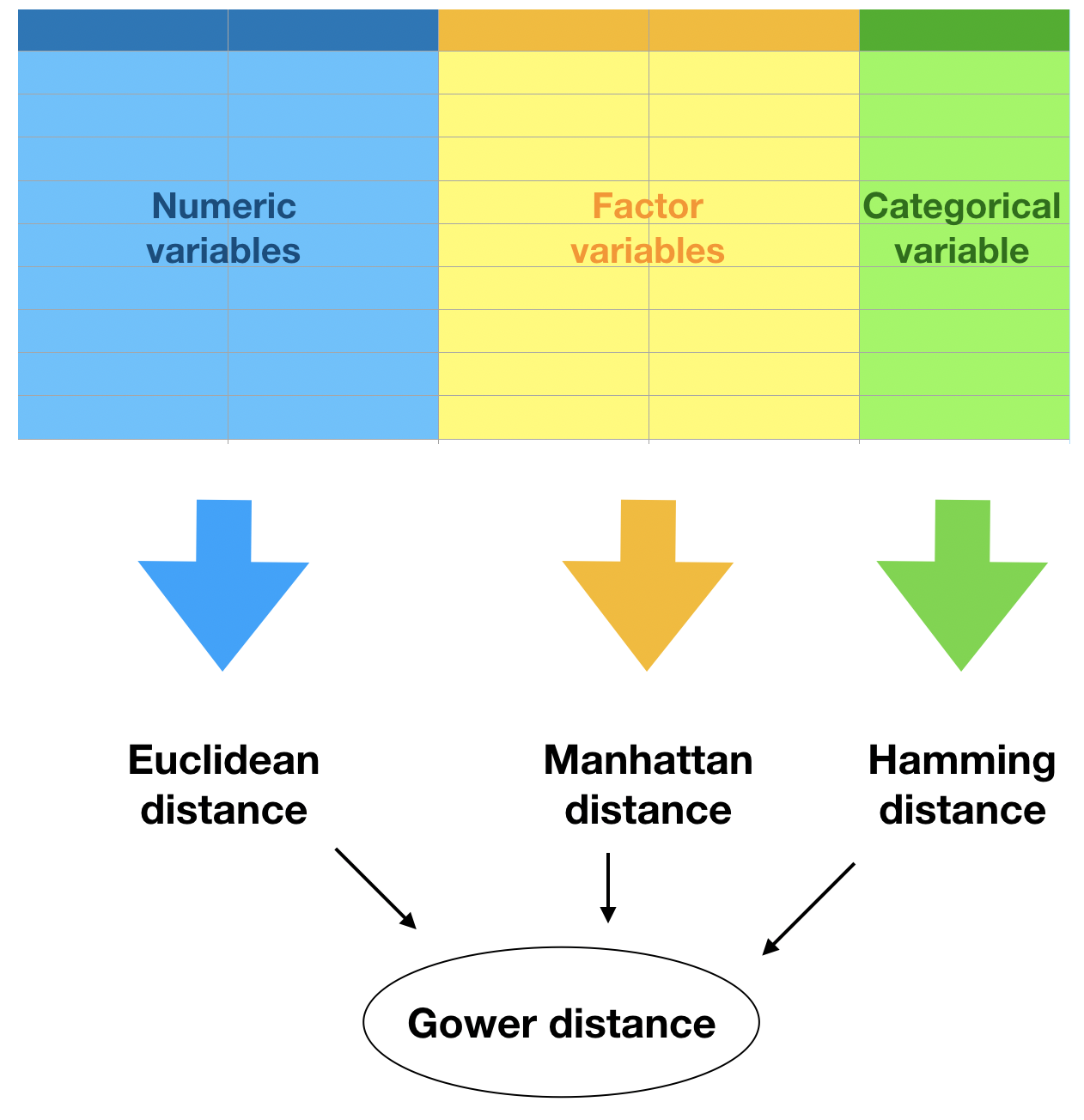
Ukuran jarak
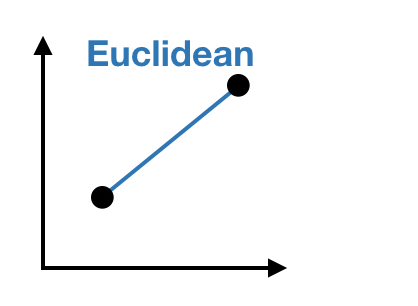
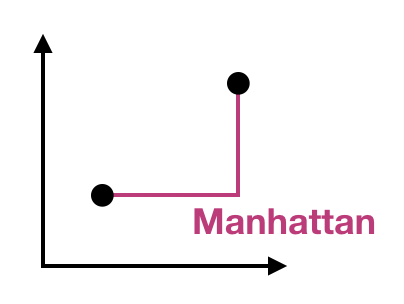
Jarak Gower
Jarak Gower