Menganonimkan data kategorikal
Privasi Data dan Anonimisasi di Python

Rebeca Gonzalez
Instructor
Generalisasi
Age Gender Department Condition
0 30 F Finance Anxiety disorders
1 42 M Production Bronchitis
2 35 F Marketing Dysthymia
3 39 F Production Dysthymia
4 40 M Marketing Flu
Age Gender Department Condition
0 <40 F Finance Anxiety disorders
1 >=40 M Production Bronquitis
2 <40 F Finance Dysthymia
3 <40 F Production Dysthymia
4 >=40 M Marketing Flu
Generalisasi data kategorikal
# Lihat dataset
hr.head()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 49 Travel_Frequently Research & Development Life Sciences 2
2 37 Travel_Rarely Research & Development Other 4
3 33 Travel_Frequently Research & Development Life Sciences 5
4 27 Travel_Rarely Research & Development Medical 7
Data kategorikal
Jumlah nilai mungkin yang terbatas atau tetap.
- ras
- gender
- kota asal
- kelompok usia
- tingkat pendidikan
- film yang disukai dan preferensi
Menganonimkan data kategorikal
Menganonimkan data kategorikal
Department EducationField
0 Sales Life Sciences
1 Research & Development Life Sciences
2 Research & Development Other
3 Research & Development Life Sciences
4 Research & Development Medical
Dataset asli
Department EducationField
0 Sales Medical
1 Research & Development Marketing
2 Research & Development Life Sciences
3 Research & Development Other
4 Research & Development Life Sciences
Dataset hasil sampling dari distribusi probabilitas kolom educationField pada dataset asli.
Sampling dari data
Sensus AS merilis sampel data publik tentang warga.
Memungkinkan perhitungan pola statistik skala besar:
- rata-rata
- varians
- klaster
Jelajahi distribusi
# Tampilkan frekuensi absolut tiap nilai unik
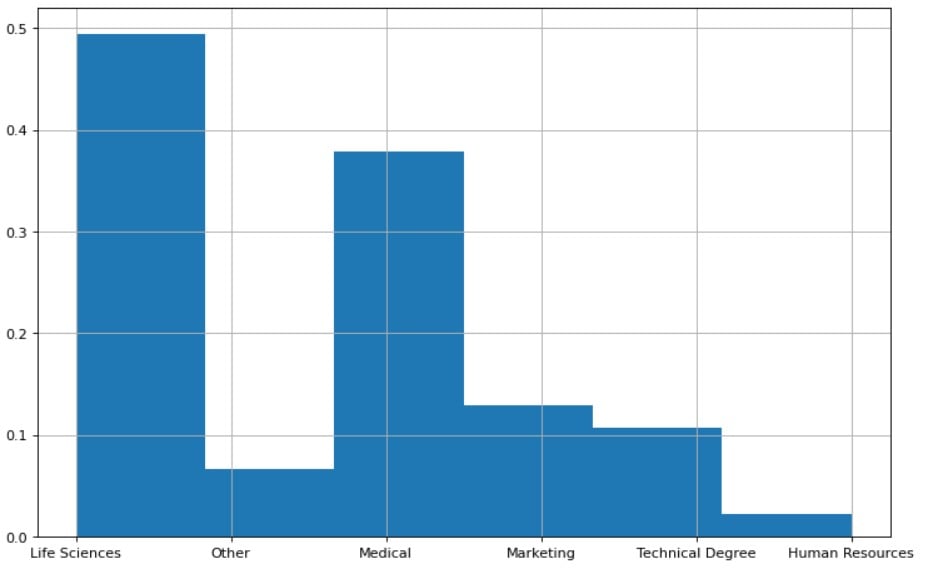
hr['EducationField'].value_counts()
Life Sciences 606
Medical 464
Marketing 159
Technical Degree 132
Other 82
Human Resources 27
Name: EducationField, dtype: int64
Jelajahi distribusi
# Buat bar plot untuk kategori
df['BusinessTravel'].value_counts().plot(kind='bar')
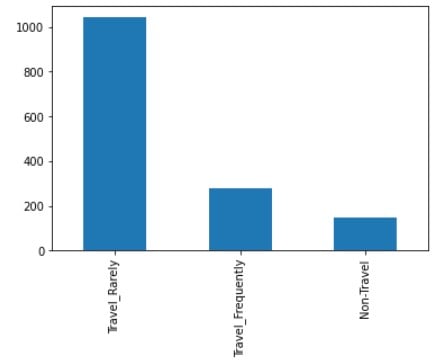
Jelajahi distribusi
# Dapatkan frekuensi absolut tiap nilai unik
counts = hr['EducationField'].value_counts()
# Cetak daftar indeks
print(counts.index)
Index(['Life Sciences', 'Medical', 'Marketing',
'Technical Degree', 'Other', 'Human Resources'],
dtype='object')
Jelajahi distribusi
# Distribusi probabilitas tiap nilai unik
counts = df['EducationField'].value_counts(normalize=True)
Life Sciences 0.412245
Medical 0.315646
Marketing 0.108163
Technical Degree 0.089796
Other 0.055782
Human Resources 0.018367
Name: EducationField, dtype: float64
Jelajahi distribusi
# Nilai frekuensi tiap nilai unik
df['EducationField'].value_counts(normalize=True).values
array([0.4122449 , 0.31564626, 0.10816327, 0.08979592, 0.05578231,
0.01836735])
Sampling dari distribusi yang sama
# Sampling dari distribusi probabilitas hr_sample['EducationField']= np.random.choice(counts.index, p=counts.values, size=len(hr))# Lihat dataset hasil hr.head()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 49 Travel_Frequently Research & Development Medical 2
2 37 Travel_Rarely Research & Development Marketing 4
3 33 Travel_Frequently Research & Development Technical Degree 5
4 27 Travel_Rarely Research & Development Medical 7
Sampling dari distribusi yang sama
# Tampilkan frekuensi absolut tiap kategori
hr['EducationField'].value_counts()
Life Sciences 606
Medical 464
Marketing 159
Technical Degree 132
Other 82
Human Resources 27
Name: EducationField, dtype: int64
# Tampilkan frekuensi kolom hasil
hr_sample['EducationField'].value_counts()
Life Sciences 604
Medical 493
Marketing 158
Technical Degree 120
Other 61
Human Resources 34
Name: EducationField, dtype: int64
Ayo berlatih!
Privasi Data dan Anonimisasi di Python

