Membuat dataset sintetis dengan scikit-learn
Privasi Data dan Anonimisasi di Python

Rebeca Gonzalez
Data engineer
Membuat dataset dengan Scikit-learn
Kita dapat membuat dataset yang diambil dari distribusi probabilitas
Misalnya distribusi normal
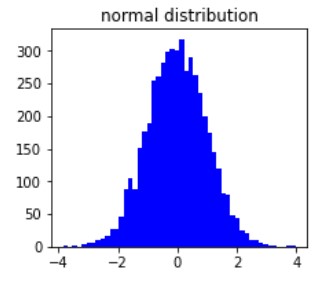
Distribusi normal
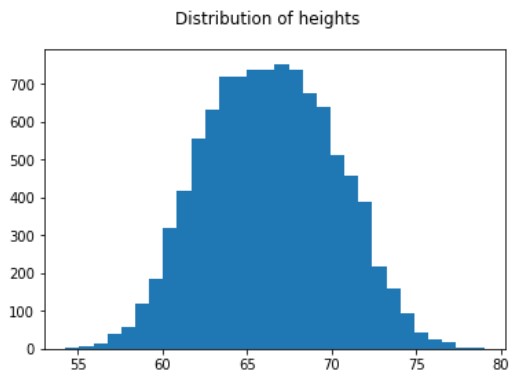
Sampel dari distribusi normal
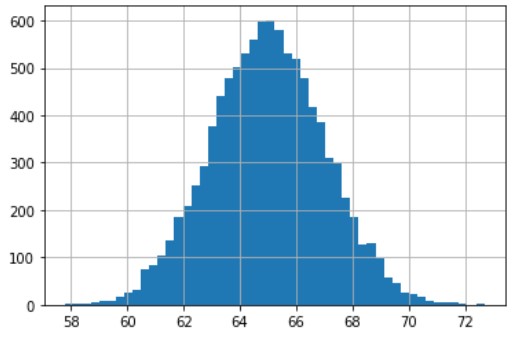
# Gambar histogram untuk melihat distribusi tinggi yang dihasilkan
new_measures['Height'].hist(bins=50)
Data sintetis untuk klasifikasi
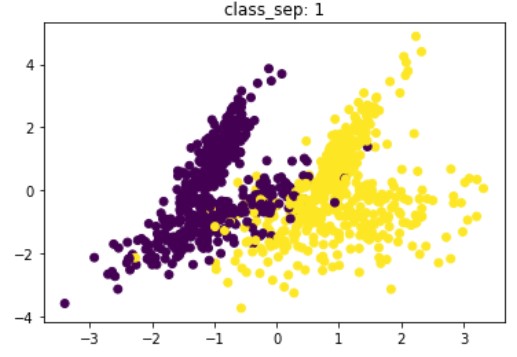
Data sintetis untuk klasifikasi
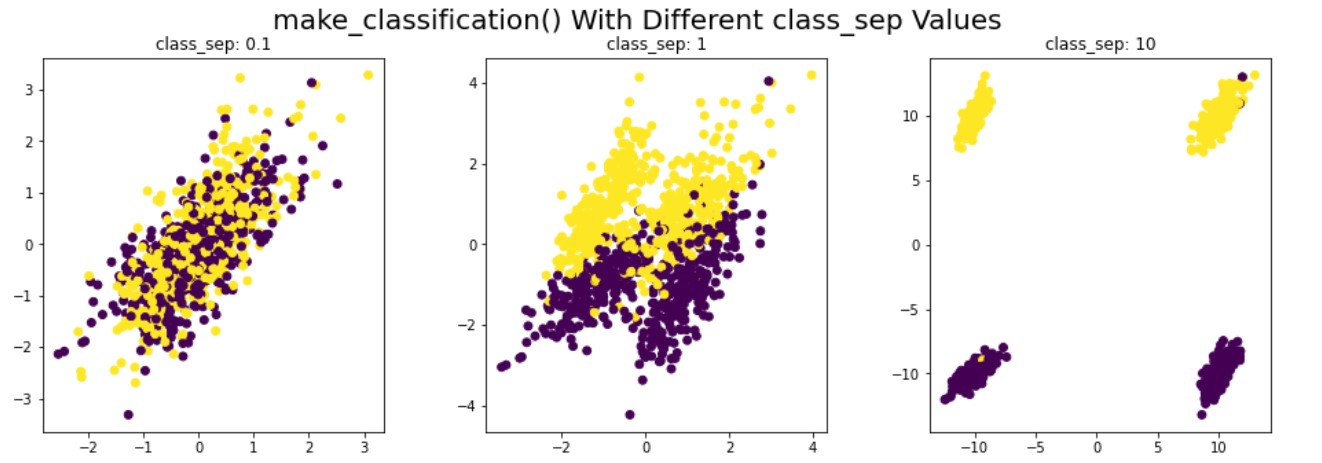
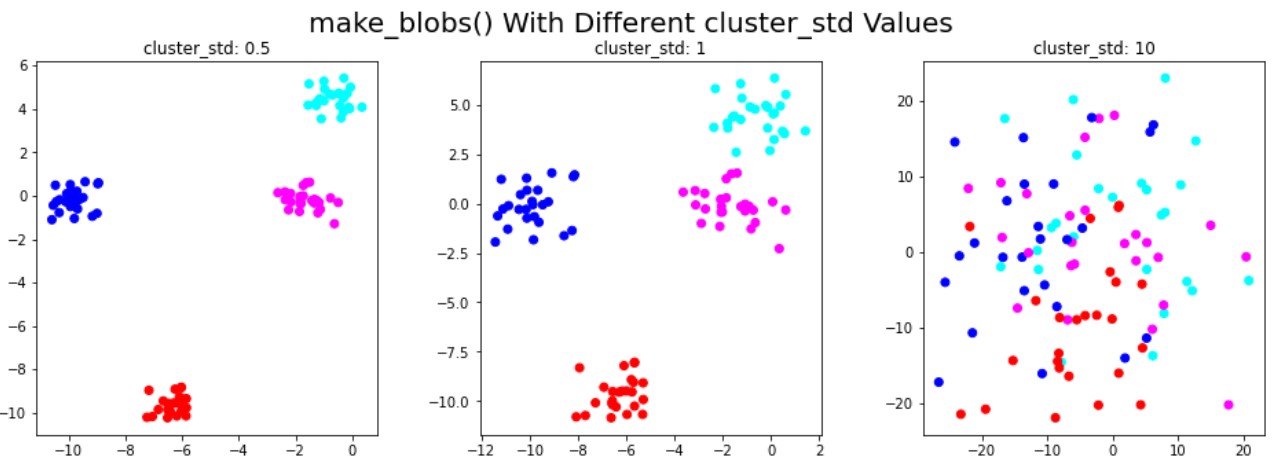
Data sintetis untuk klasterisasi
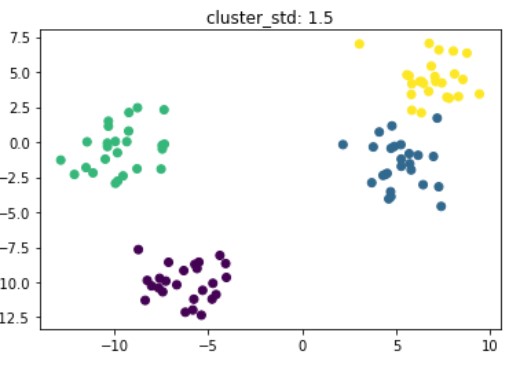
Data sintetis untuk klasterisasi