PCA untuk anonimisasi
Privasi Data dan Anonimisasi di Python

Rebeca Gonzalez
Data engineer
Principal component analysis (PCA)
$$ $$ Metode reduksi dimensi yang sering dipakai untuk mengurangi dimensi dataset besar.
Masking data dengan PCA
PCA membuat "komponen utama" baru dari transformasi linear fitur asli.
Dalam dataset bir, PCA akan membangun fitur baru. Contoh:
$$ 2\times AlcoholicVolume - BitternessLevel$$
Masking data dengan PCA
Proyeksi baru dari data
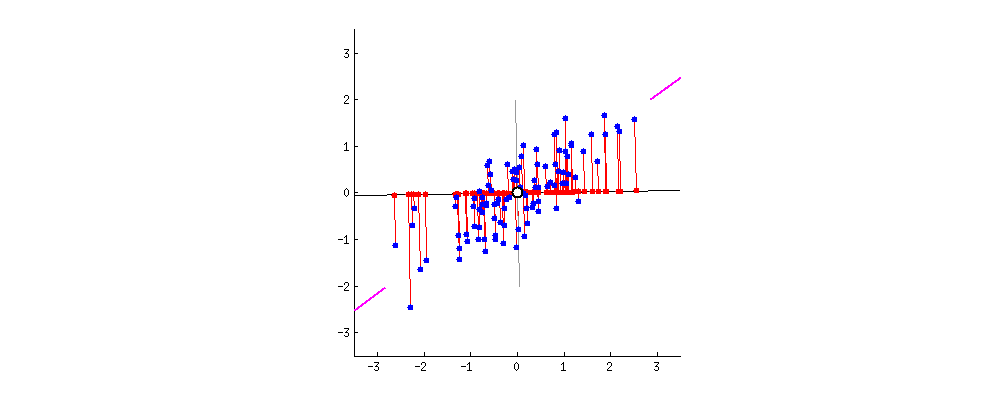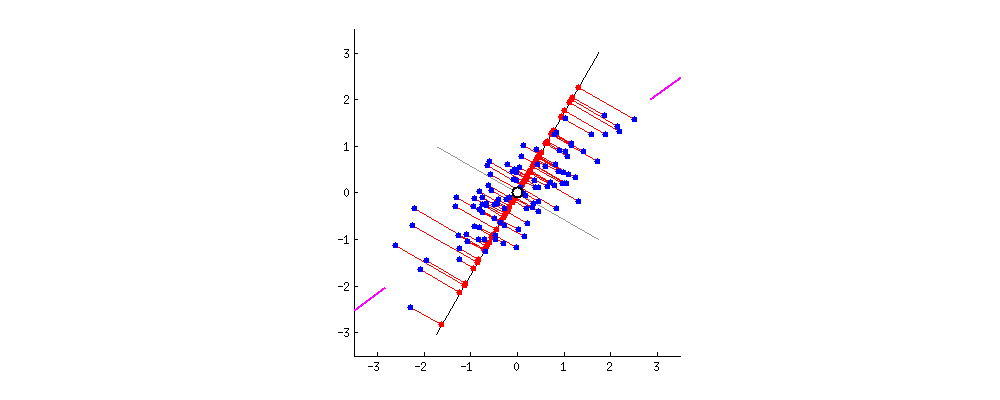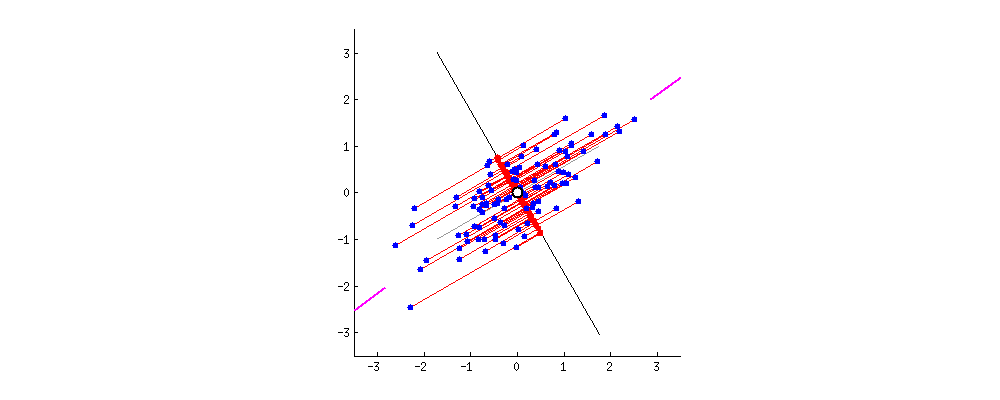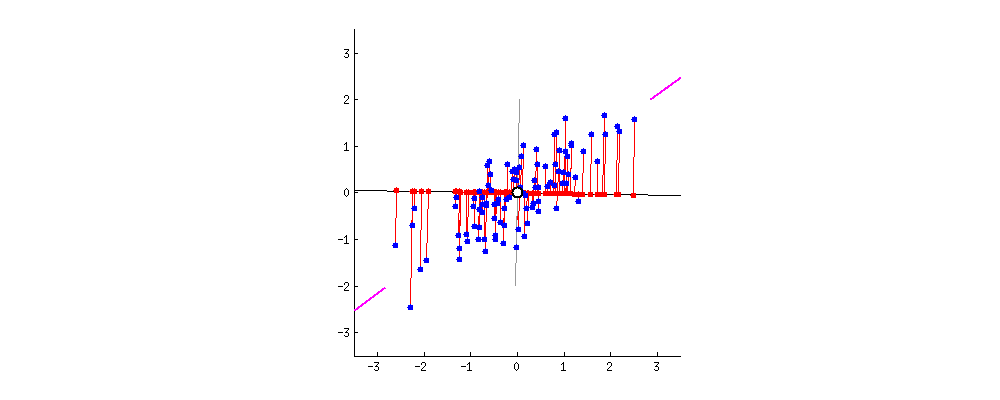
Masking data dengan PCA
PCA tanpa reduksi dimensi
$$
- Hanya rotasi ruang asli pada dataset.
- Jarak tetap terjaga.
- Keuntungan untuk tugas dan algoritme prediktif.
Masking data dengan PCA
- Jika nilai hasil ini dirilis tanpa penjelasan, algoritme tetap dapat dilatih dan membuat prediksi akurat.
- Pihak penyerang tidak tahu cara menafsirkan nilai terselubung itu.
Masking data dengan PCA
# Jelajahi dataset
heart_df.head()
age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target
0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1
1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1
2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1
3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1
4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1
Masking data dengan PCA dan Scikit-learn
# Ambil data tanpa kolom target x_data = df.drop(['target'], axis = 1)# Kolom target sebagai array nilai y = df.target.values
Masking data dengan PCA dan Scikit-learn
# Impor PCA dari Scikit-learn from sklearn.decomposition import PCA# Inisialisasi PCA dengan jumlah komponen sama dengan jumlah kolom pca = PCA(n_components=len(x_data.columns))# Terapkan PCA ke data x_data_pca = pca.fit_transform(x_data)
Masking data dengan PCA dan Scikit-learn
# Lihat datanya
x_data_pca
array([[-1.22673448e+01, 2.87383781e+00, 1.49698788e+01, ...,
7.31102828e-01, -2.90393586e-01, 5.12575925e-01],
[ 2.69013712e+00, -3.98713736e+01, 8.77882303e-01, ...,
4.04206943e-01, -4.25920179e-01, -1.48124511e-01],
[-4.29502141e+01, -2.36368199e+01, 1.75944589e+00, ...,
-9.15397287e-01, 2.17828257e-01, 7.97593843e-02],
...,
Masking data dengan PCA dan Scikit-learn
# Buat DataFrame dari data hasil transformasi PCA df_x_data_pca = pd.DataFrame(x_data_pca)# Periksa bentuk dataset df_x_data_pca.shape
(1213, 13)
Kegunaan data setelah masking PCA
- Lakukan klasifikasi dengan regresi logistik dan cari penurunan akurasi dengan membandingkan data asli vs hasil.
$$
- Regresi logistik adalah algoritme klasifikasi untuk memprediksi keluaran biner dari sekumpulan variabel independen.
Kegunaan data setelah masking PCA
Lakukan klasifikasi dengan regresi logistik dan cek penurunan akurasi.
# Bagi dataset hasil menjadi data latih dan uji x_train, x_test, y_train, y_test = train_test_split(x_data_pca, y, test_size=0.2)# Buat model lr = LogisticRegression(max_iter=200)# Latih model lr.fit(x_train,y_train)# Jalankan model dan prediksi untuk mendapatkan skor akurasi acc = lr.score(x_test, y_test) * 100 print("Test Accuracy is ", acc)
Test Accuracy is 85.24590163934425
Kegunaan data sebelum masking PCA
Lakukan klasifikasi dengan regresi logistik dan lihat skor dengan data asli
# Bagi dataset hasil menjadi data latih dan uji
x_train, x_test, y_train, y_test = train_test_split(x_data.to_numpy(),y,test_size = 0.2)
# Buat model
lr = LogisticRegression(max_iter=200)
# Latih model
lr.fit(x_train,y_train)
# Jalankan model dan prediksi untuk mendapatkan skor akurasi
acc = lr.score(x_test,y_test) * 100
print("Test Accuracy is ", acc)
Test Accuracy is 85.24590163934425
Ayo berlatih!
Privasi Data dan Anonimisasi di Python

