Pengantar K-anonymity
Privasi Data dan Anonimisasi di Python

Rebeca Gonzalez
Data engineer
Mengapa k-anonymity penting?

Mengapa ini penting?
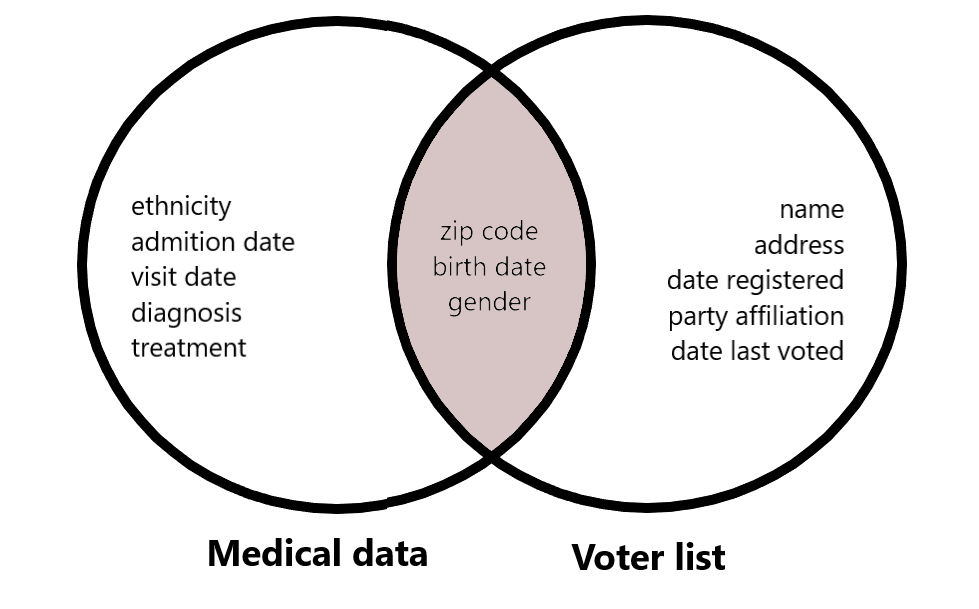
Definisi k-anonymity

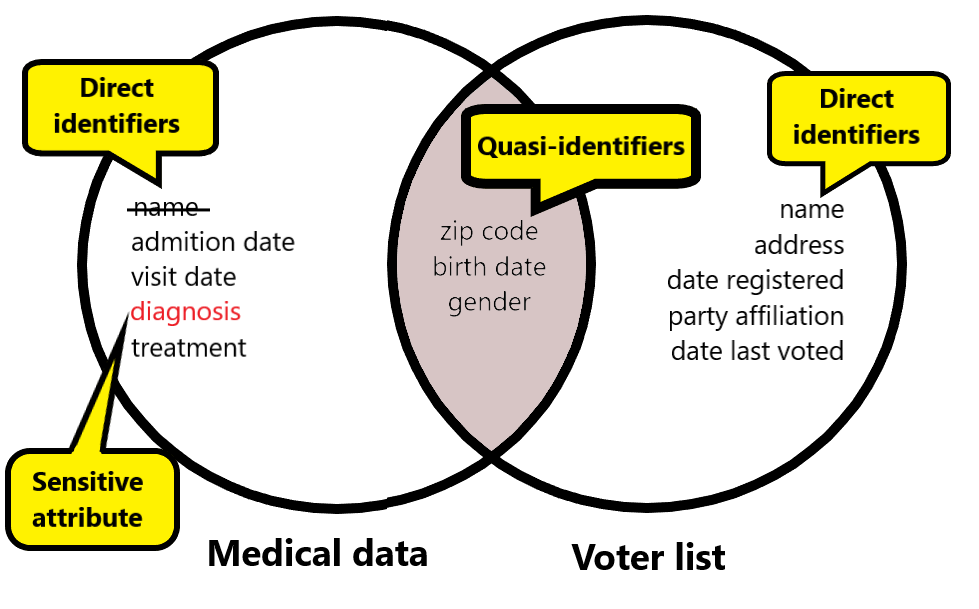
K-anonymity: Terminologi
Privasi Data dan Anonimisasi di Python
Rebeca Gonzalez
Data engineer

