Jalur pintas pendekatan
Inferensi untuk Data Kategorik di R

Andrew Bray
Assistant Professor of Statistics at Reed College
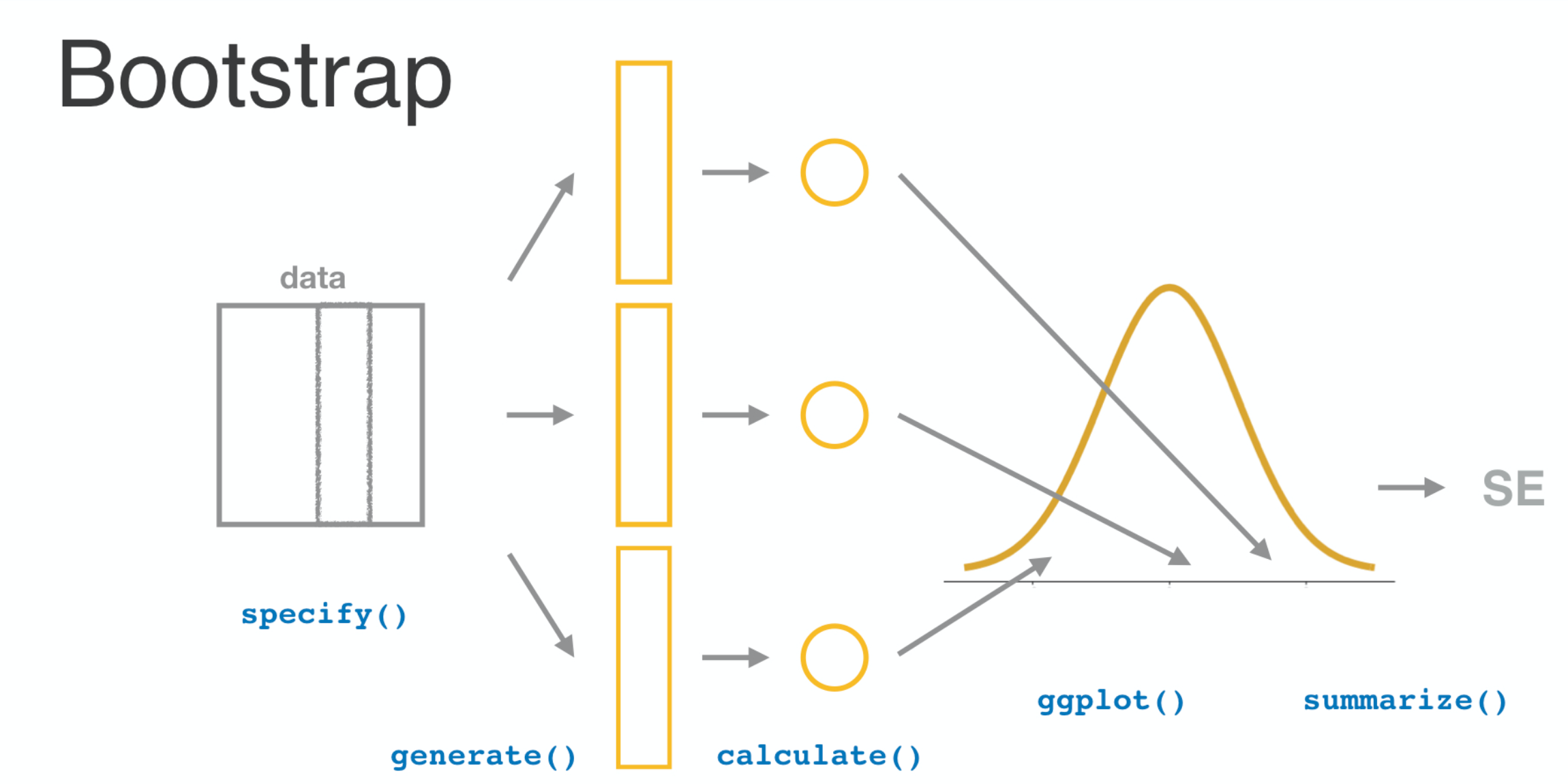
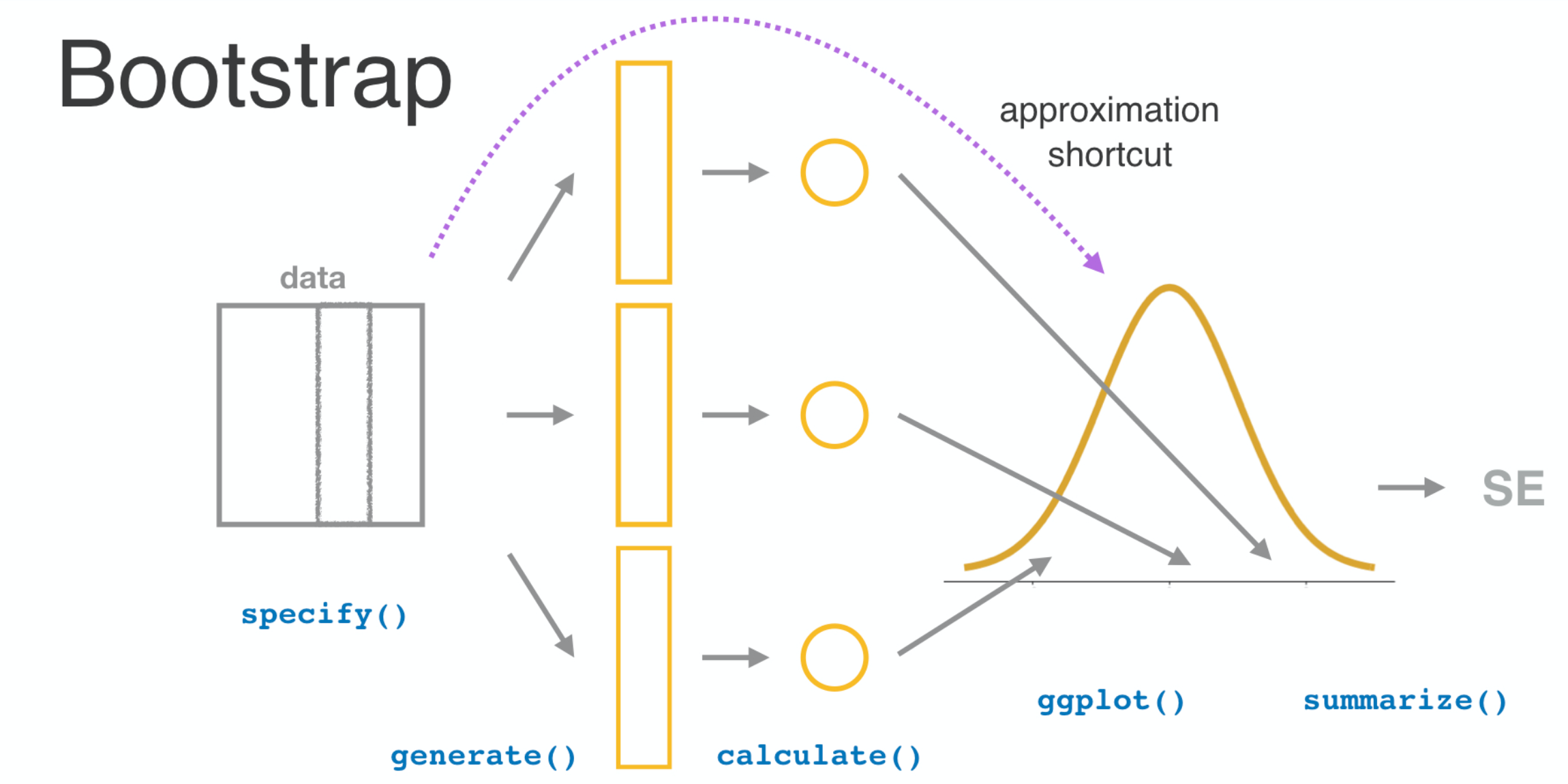
Distribusi normal
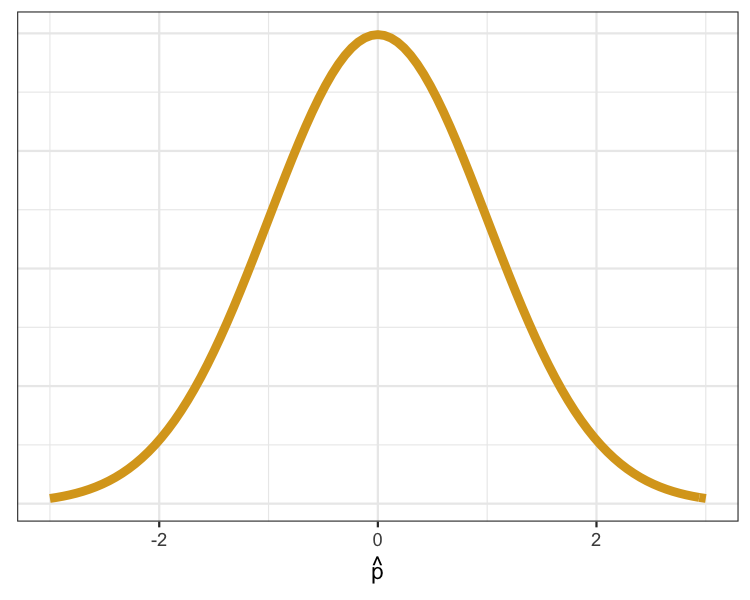
Distribusi sampling
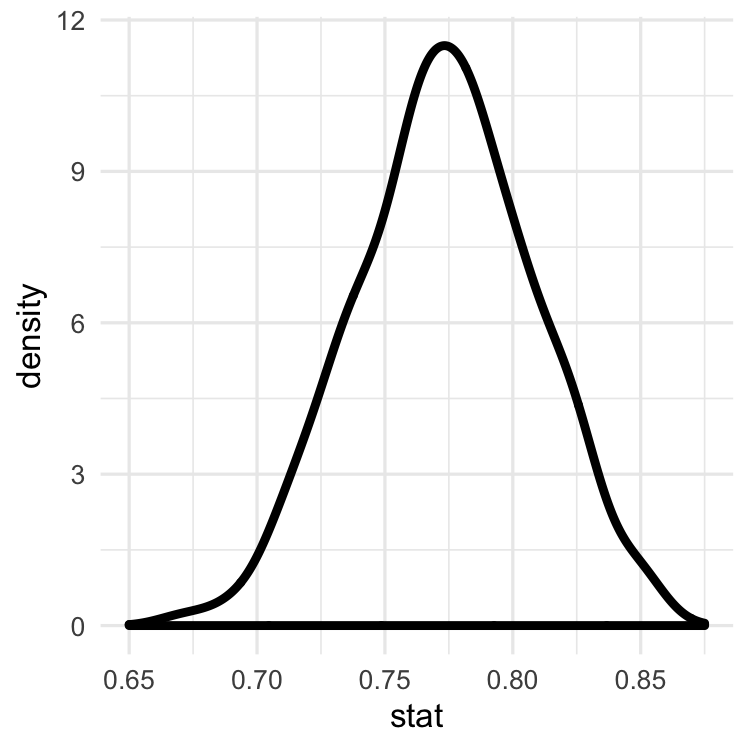
Distribusi sampling
Distribusi sampling
Inferensi untuk Data Kategorik di R
Andrew Bray
Assistant Professor of Statistics at Reed College

