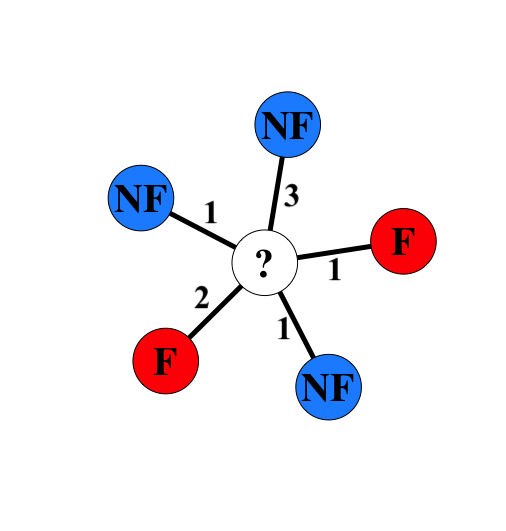
Inferensi berbasis jejaring sosial
Deteksi Fraud di R

Tim Verdonck
Professor Data Science at KU Leuven
Inferensi berbasis jejaring sosial
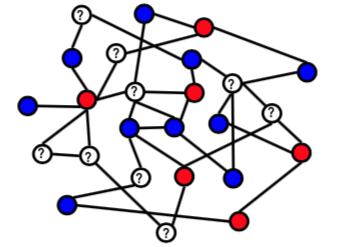
Inferensi berbasis jejaring sosial
Non-relasional vs relasional
Model non-relasional
- Hanya memakai informasi lokal
- Regresi logistik, pohon keputusan, ...
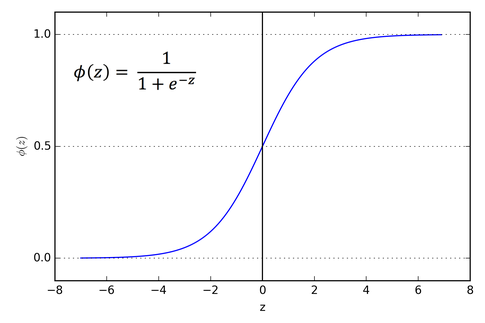
Model relasional
- Memanfaatkan tautan dalam jaringan
- Klasifikator tetangga relasional
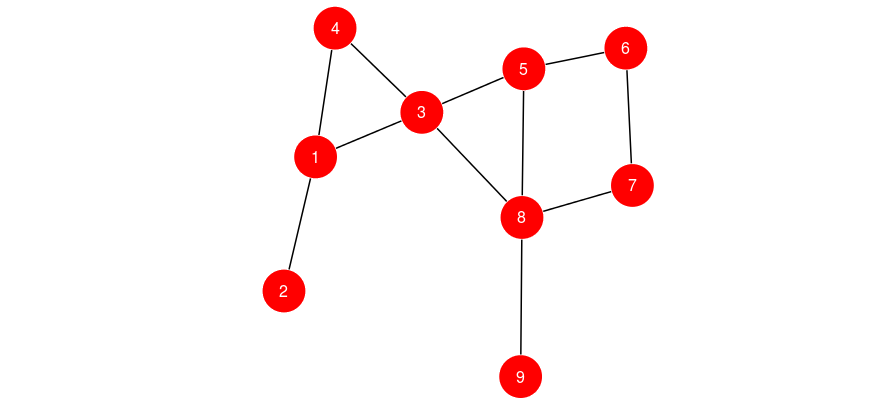
Klasifikator tetangga relasional
Klasifikator tetangga relasional
Klasifikator tetangga relasional berbobot