Dari dataset ke model deteksi
Deteksi Fraud di R

Sebastiaan Höppner
PhD researcher in Data Science at KU Leuven
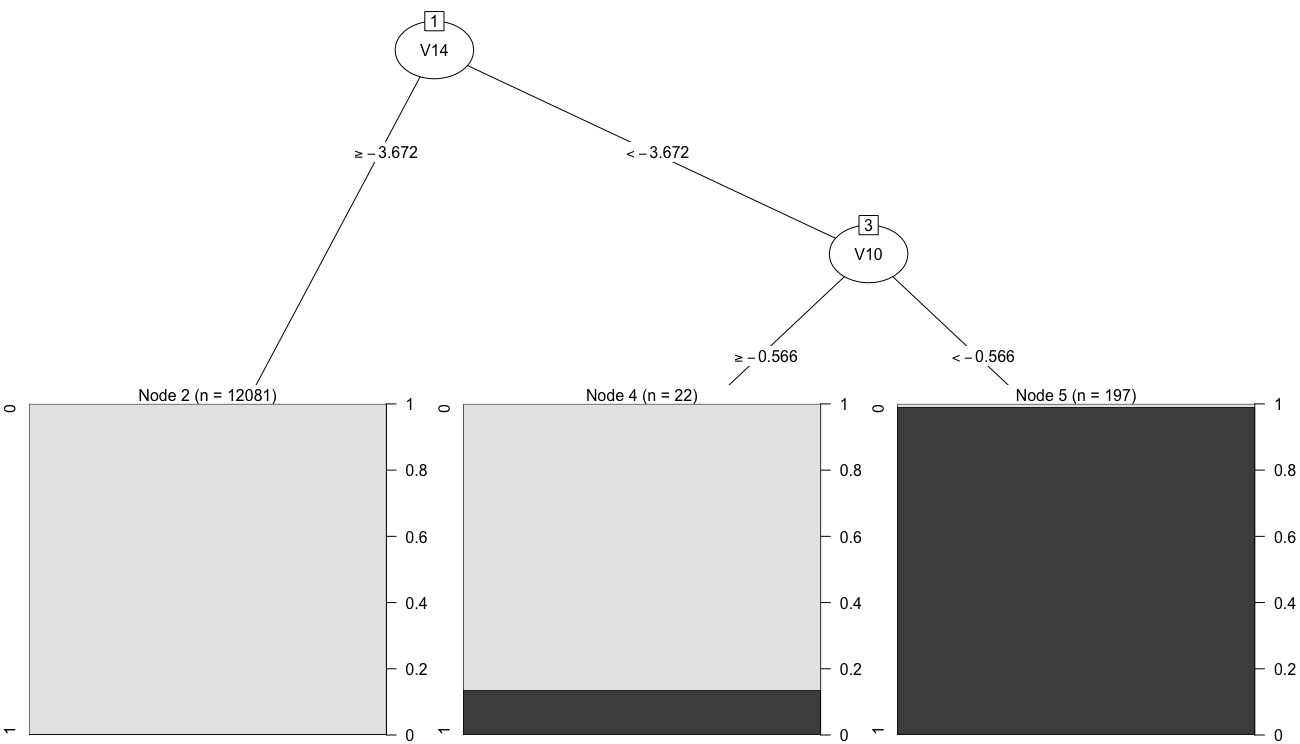
library(partykit)
plot(as.party(model1))
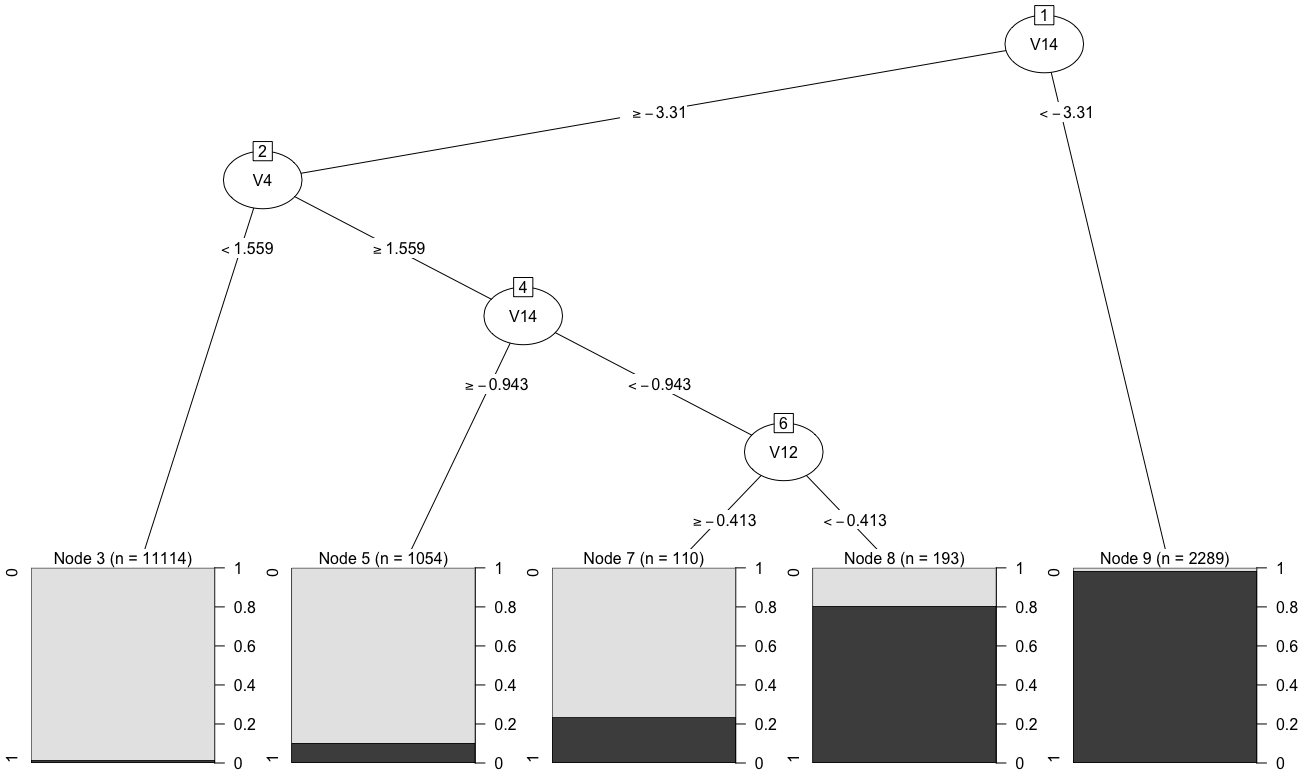
library(rpart)
model2 = rpart(Class ~ ., data = train_oversampled)
Matriks biaya
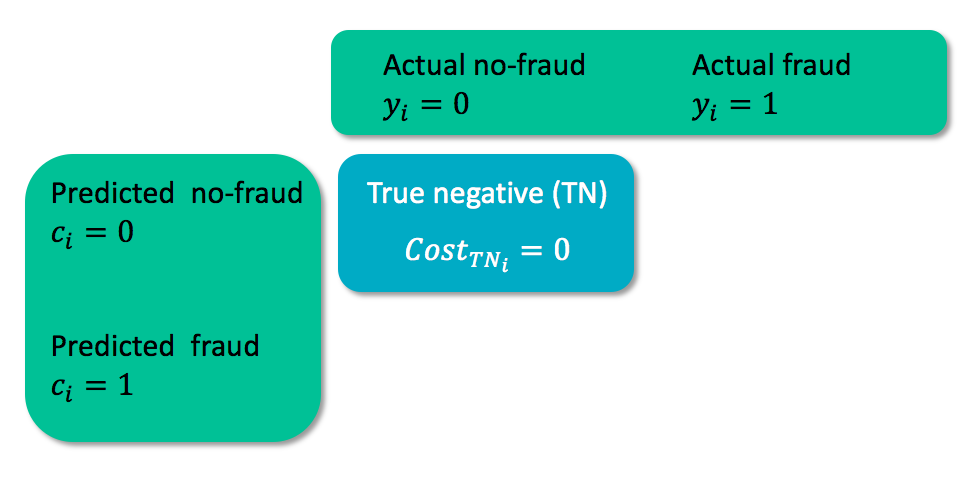
- $y_i$ = kelas sebenarnya kasus $i$
- $c_i$ = kelas prediksi untuk kasus $i$
Matriks biaya
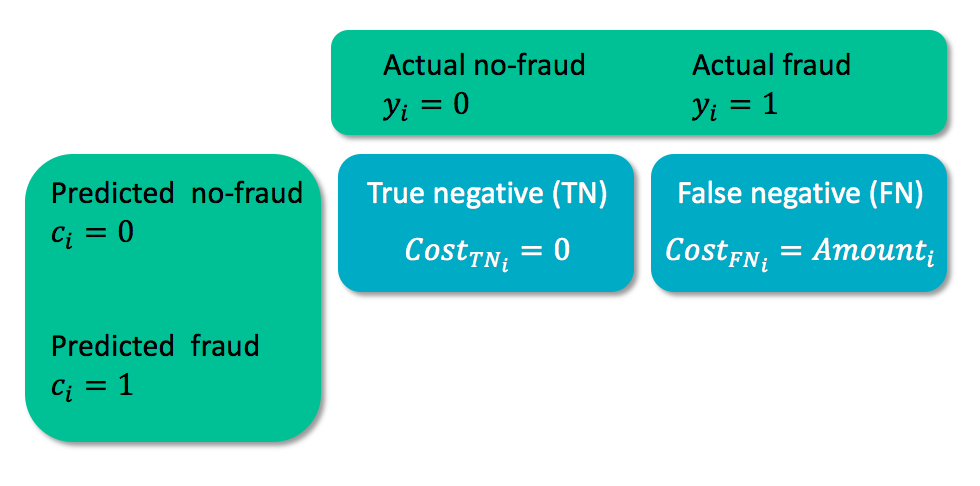
- $y_i$ = kelas sebenarnya kasus $i$
- $c_i$ = kelas prediksi untuk kasus $i$
Matriks biaya
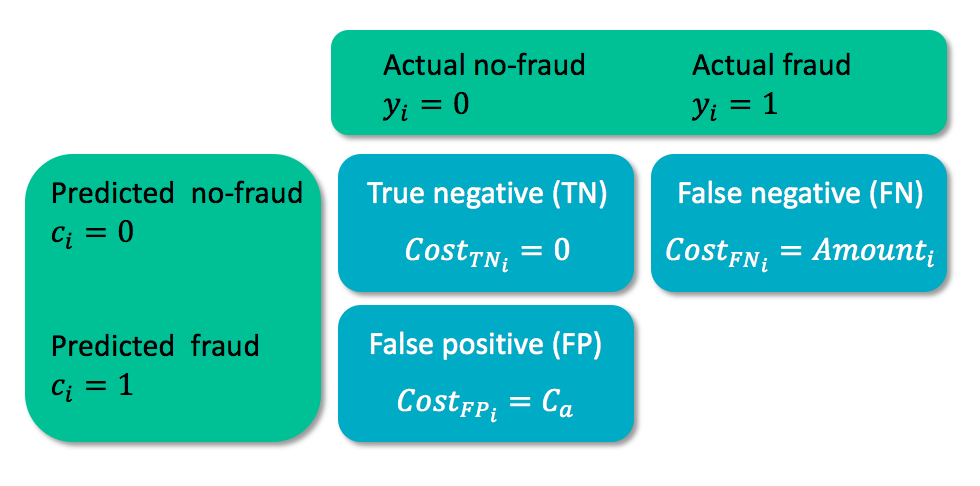
- $C_a$ = biaya analisis kasus
Matriks biaya
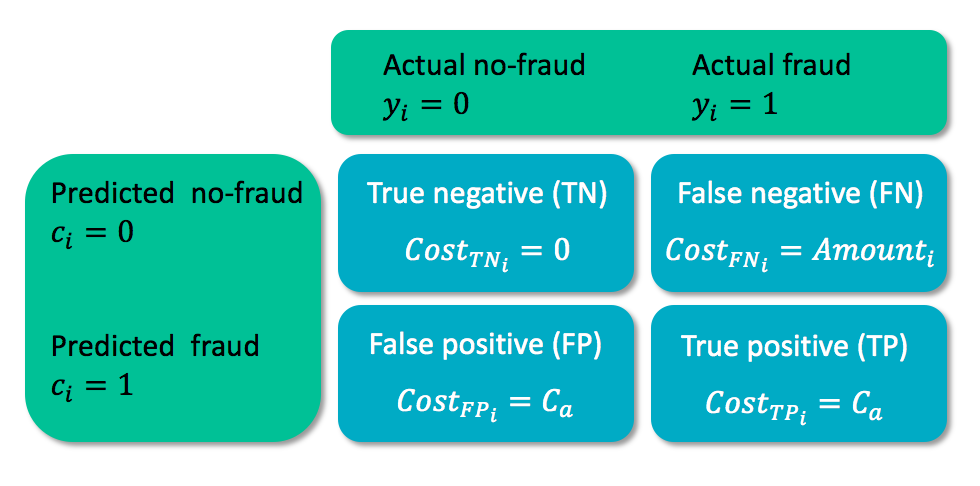
- $C_a$ = biaya analisis kasus

