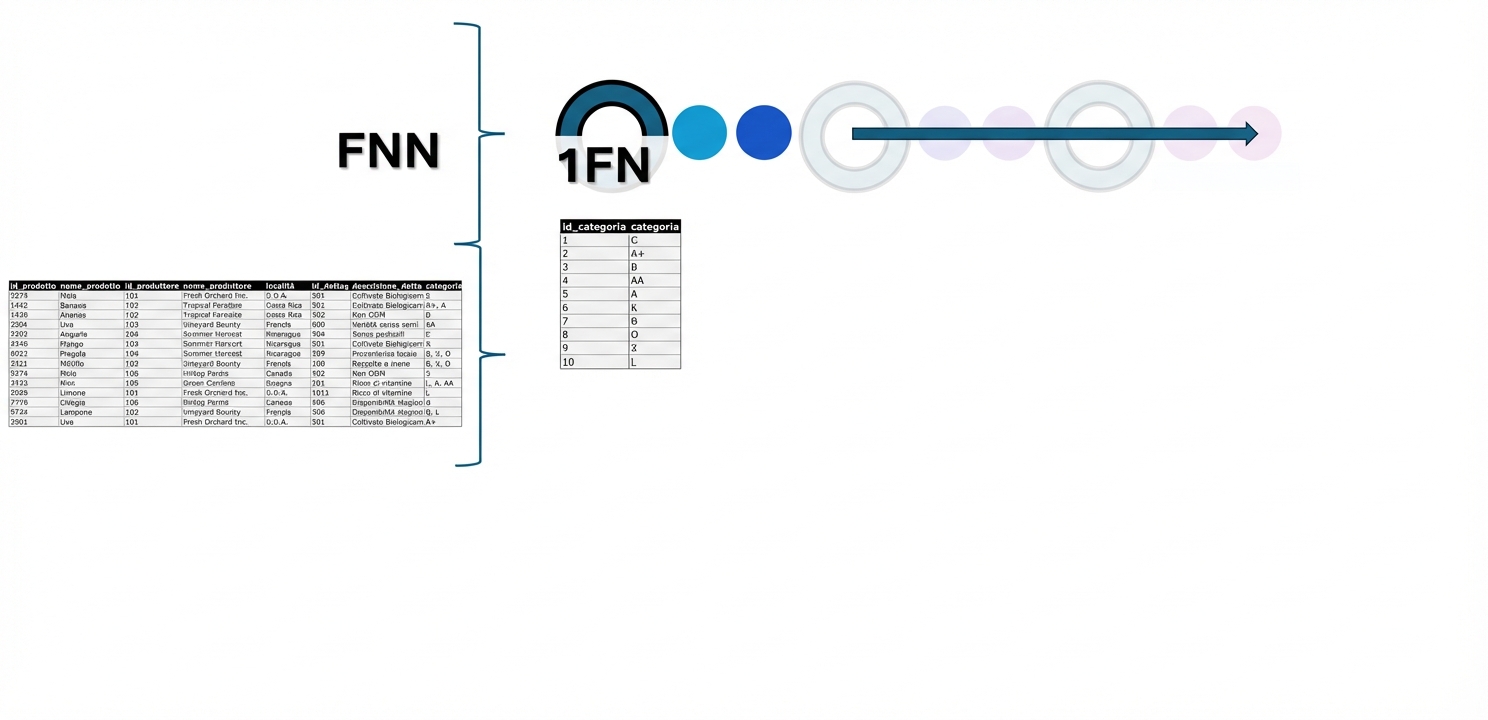
La prima forma normale
Introduzione al Data Modeling in Snowflake

Nuno Rocha
Director of Engineering
Il processo di normalizzazione dei dati
- Normalizzazione dei dati: processo in più fasi per strutturare i dati e ridurre duplicazioni e dipendenze

Il processo di normalizzazione dei dati (1)
- Normalizzazione dei dati: processo in più fasi per strutturare i dati e ridurre duplicazioni e dipendenze

Il processo di normalizzazione dei dati (2)
- Normalizzazione dei dati: processo in più fasi per strutturare i dati e ridurre duplicazioni e dipendenze
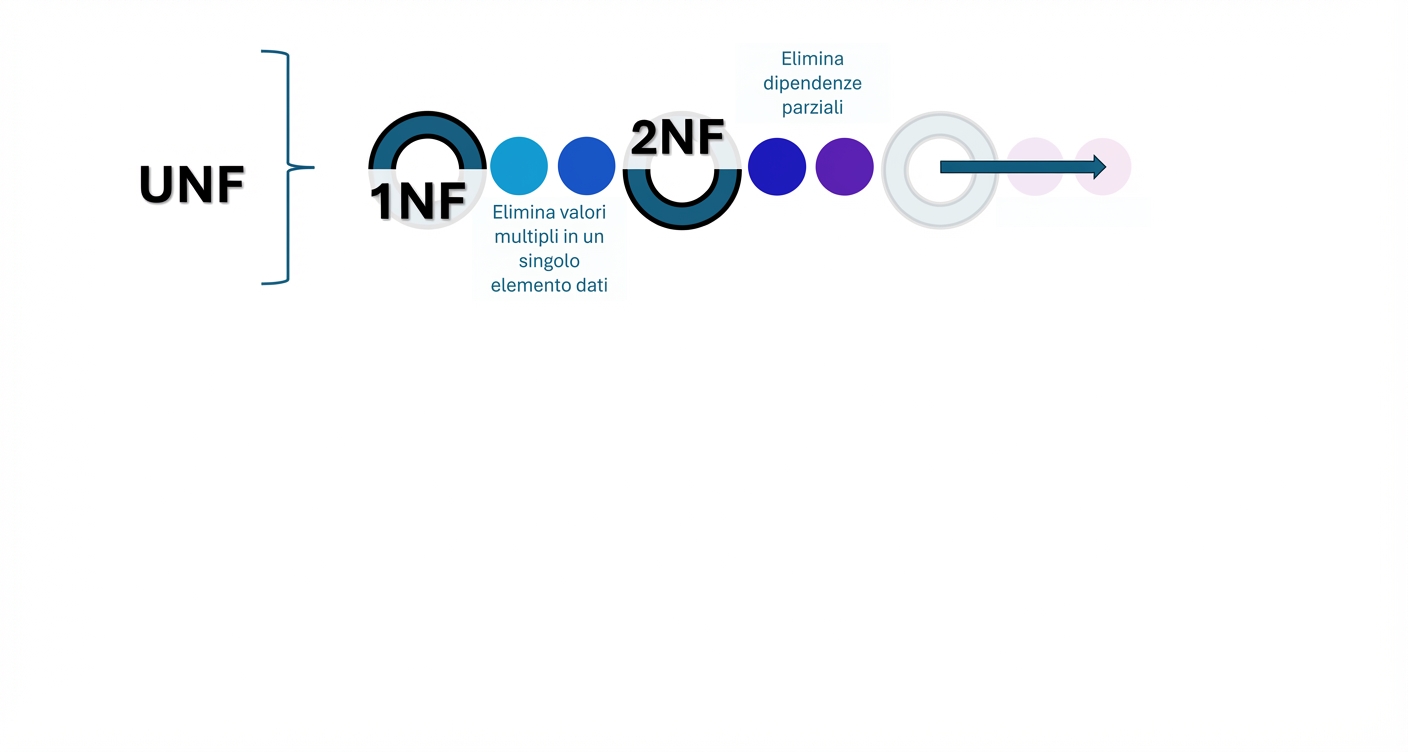
Il processo di normalizzazione dei dati (3)
- Normalizzazione dei dati: processo in più fasi per strutturare i dati e ridurre duplicazioni e dipendenze
La prima forma normale
- Prima forma normale (1NF): ogni colonna di un’entità contiene valori atomici unici
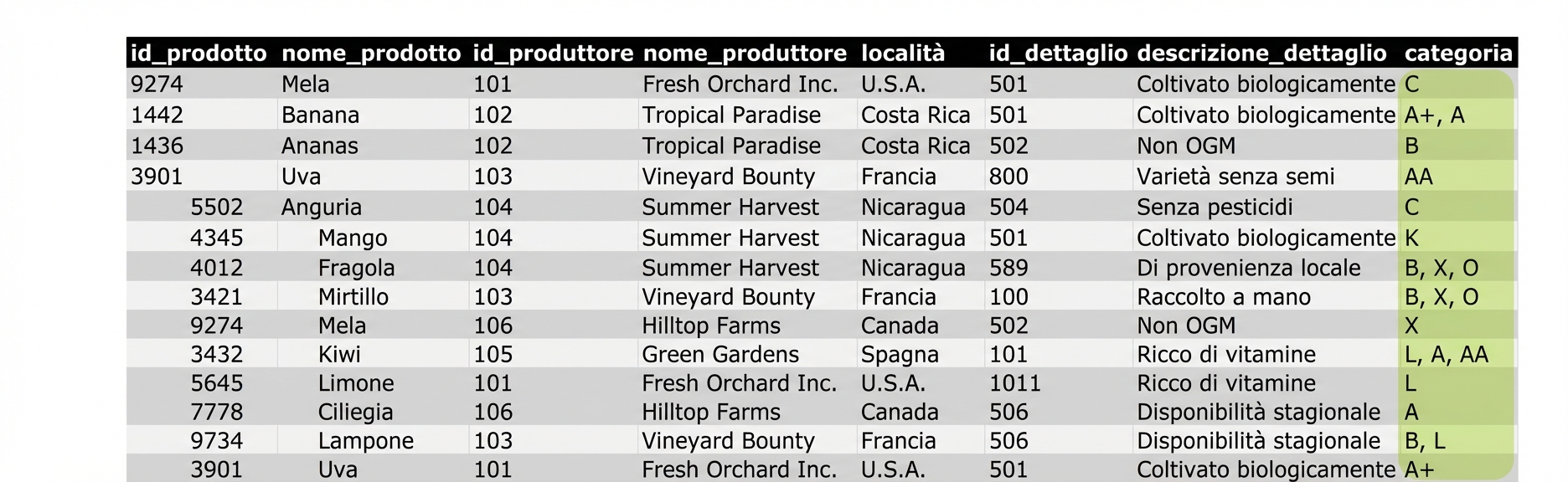
La prima forma normale (1)
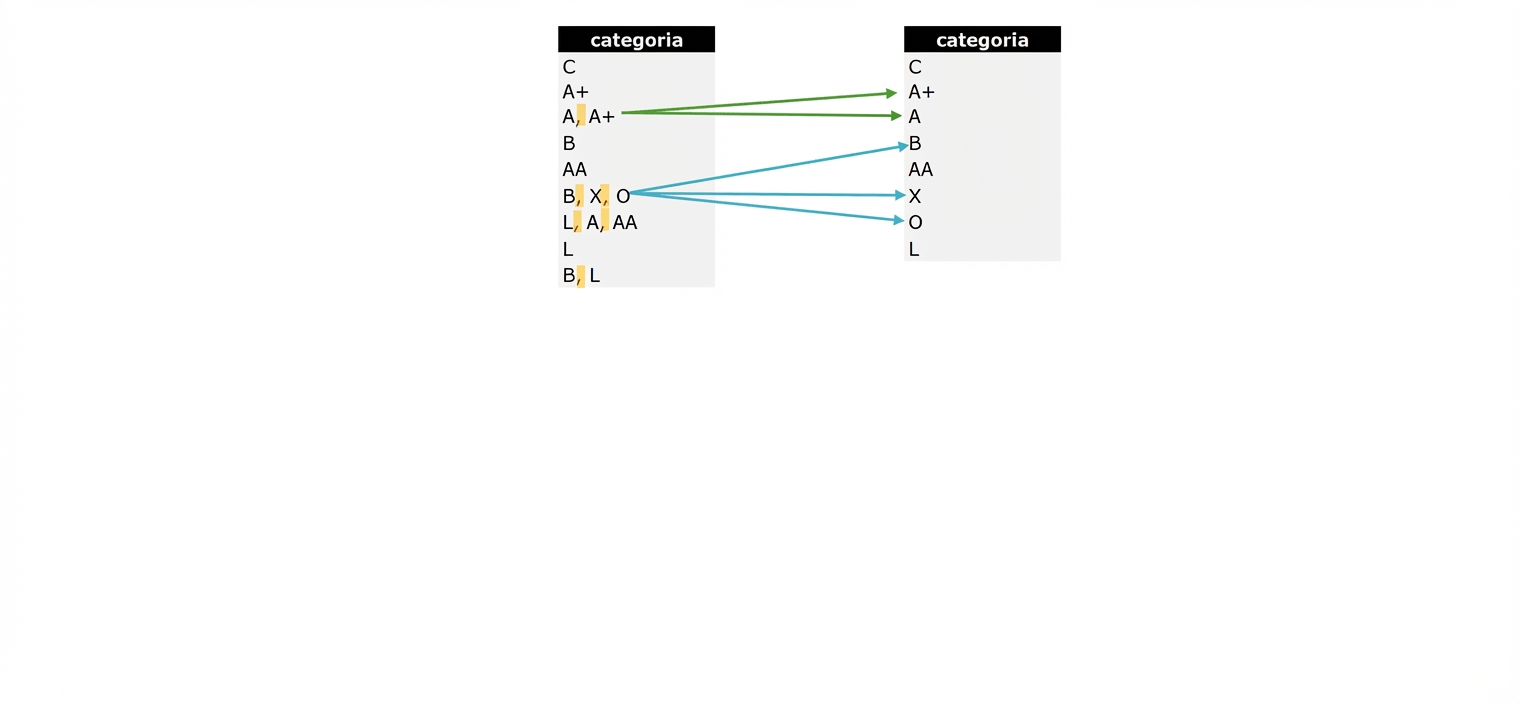
- Dati di categoria in UNF: la categoria L non è isolata, quindi non puoi aggiornarne i valori

La prima forma normale (2)
- Passo di verifica: interroga i valori unici per valutare la conformità alla 1NF.
SELECT DISTINCT category
FROM allproducts;

Funzioni Snowflake per la 1NF
- TRIM: rimuove gli spazi all’inizio e alla fine dei valori
SELECT TRIM(category)
FROM allproducts;

Funzioni Snowflake per la 1NF
- TRIM: rimuove gli spazi all’inizio e alla fine dei valori.
- LATERAL & FLATTEN: trattano una lista di valori come una tabella di elementi singoli.
- SPLIT: separa i valori in base a un delimitatore.
SELECT TRIM(f.value)
FROM allproducts,
LATERAL FLATTEN(INPUT => SPLIT(allproducts.category, ',')) f;
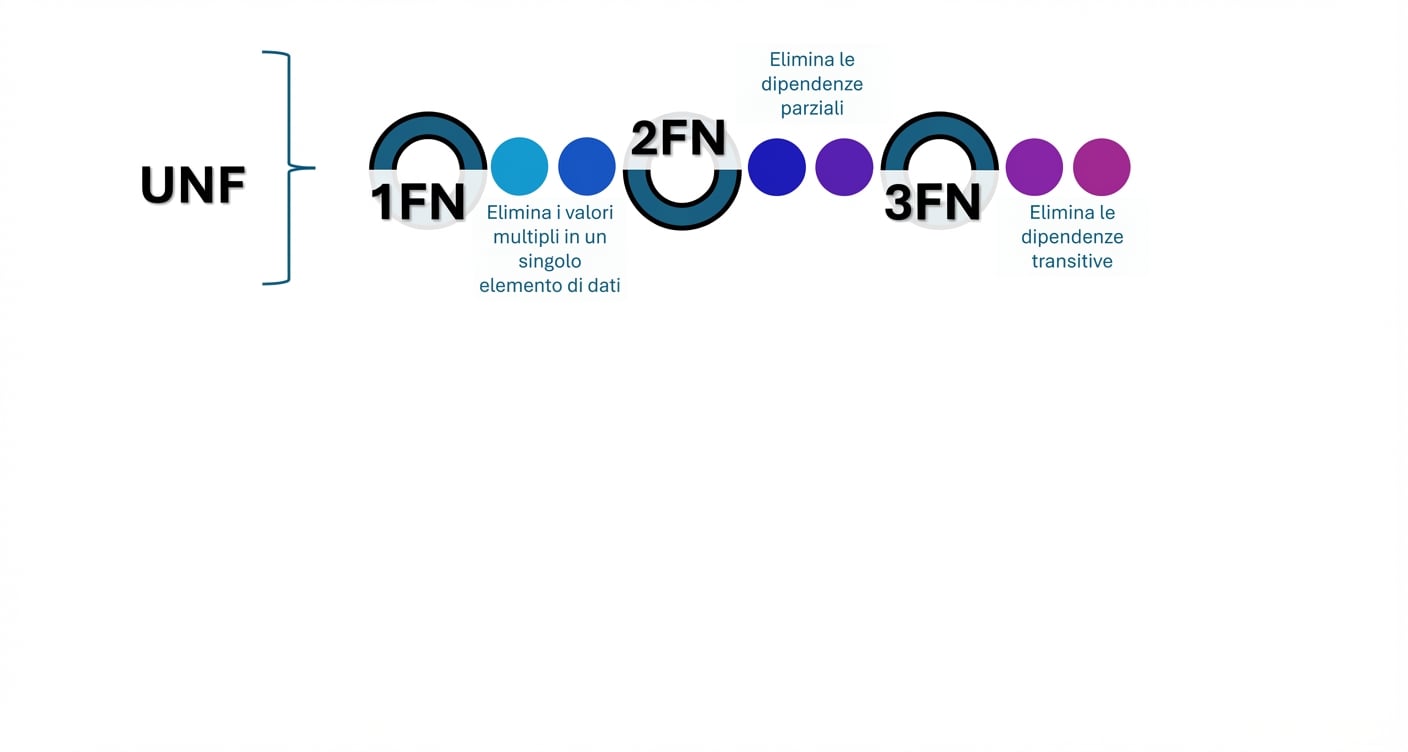
Verso la normalizzazione dei dati