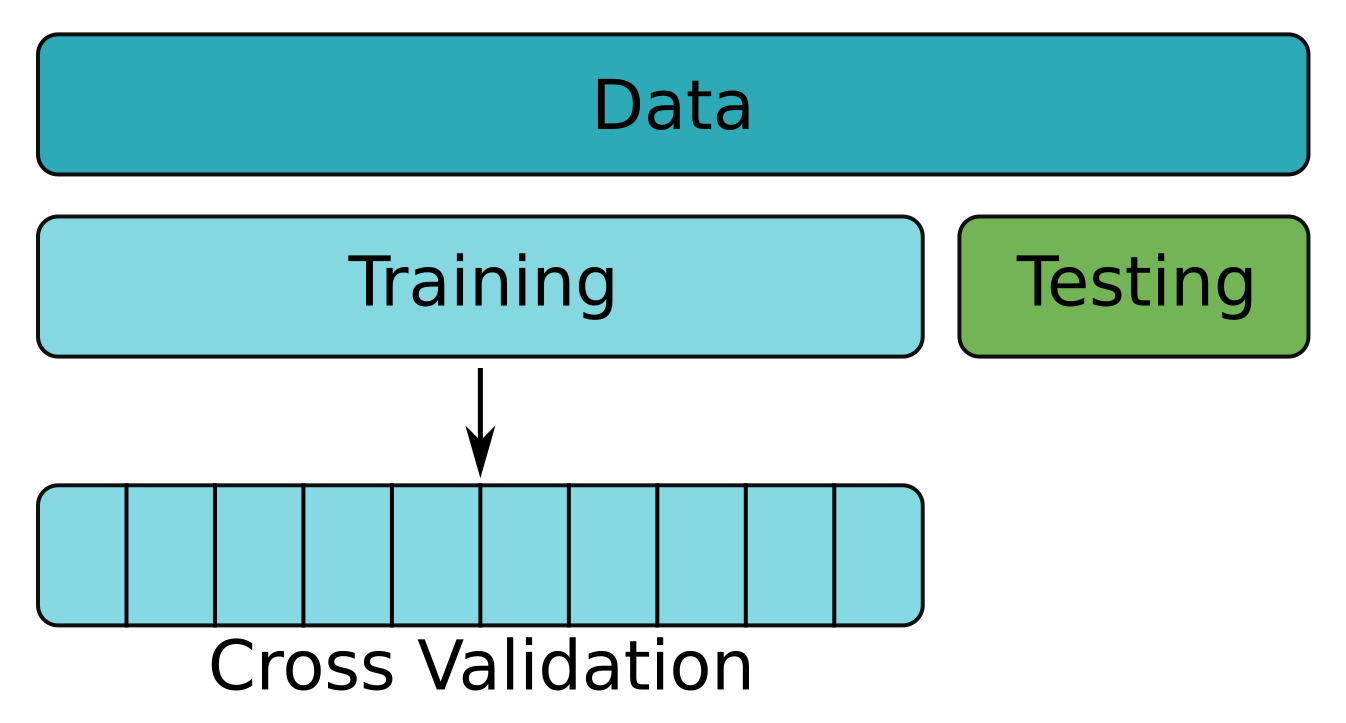
Validazione incrociata
Machine Learning con PySpark

Andrew Collier
Data Scientist, Fathom Data


Pieghe su pieghe - prima piega

Pieghe su pieghe - seconda piega
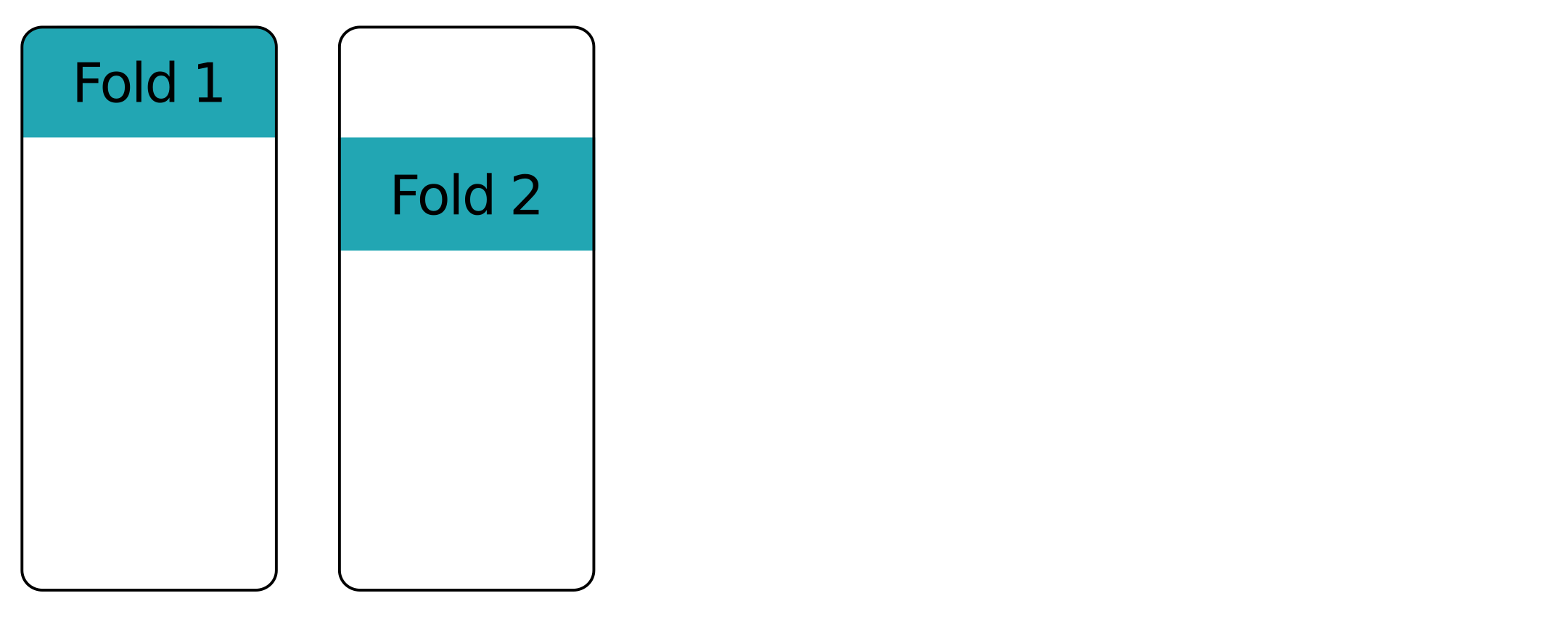
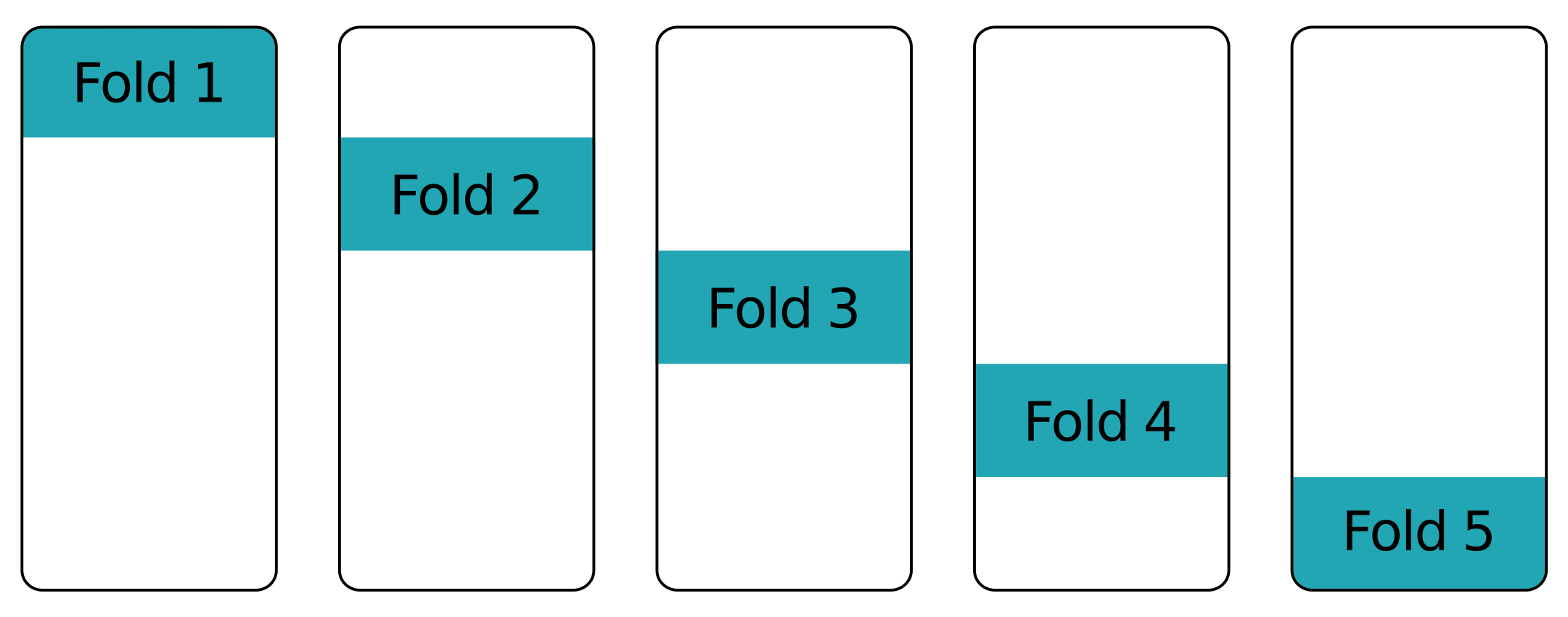
Pieghe su pieghe - altre pieghe
Machine Learning con PySpark
Andrew Collier
Data Scientist, Fathom Data

