Pipeline
Machine Learning con PySpark

Andrew Collier
Data Scientist, Fathom Data
Leakage?

Solo per i dati di training.

Per dati di test e di training.
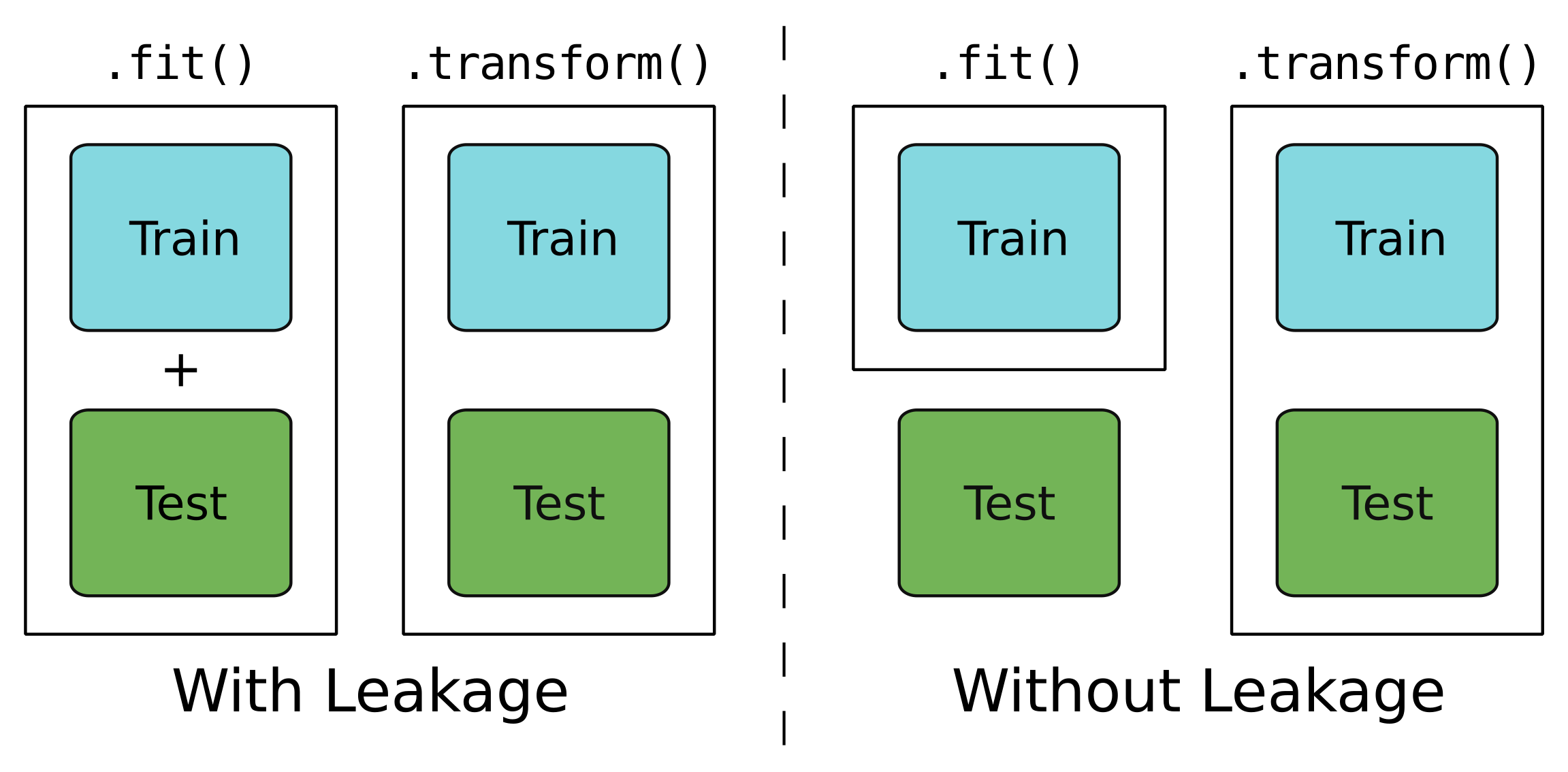
Un modello con leakage
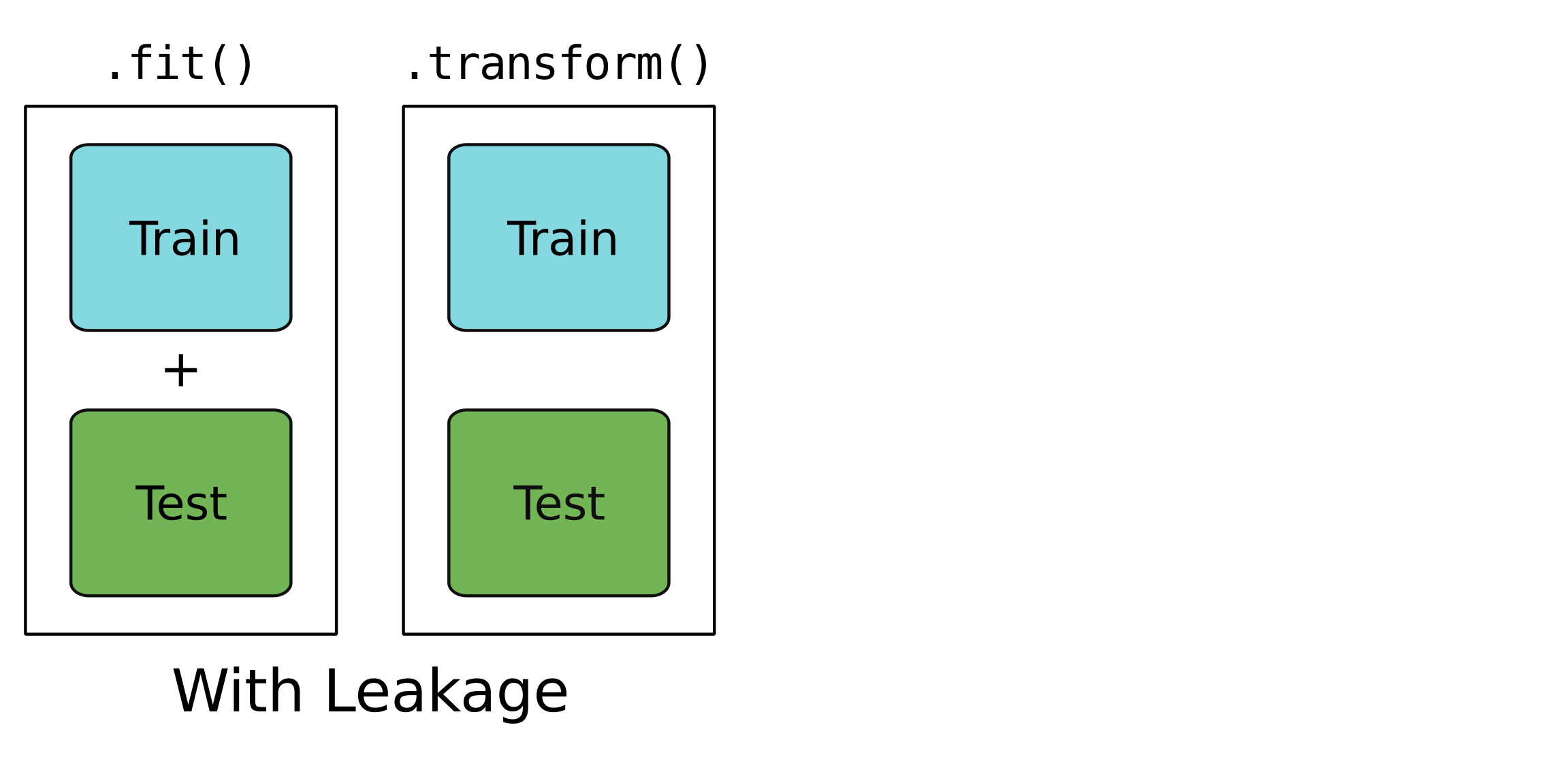
Un modello a tenuta stagna
Pipeline
Una pipeline è una serie di operazioni.

Puoi applicare ogni operazione singolarmente... oppure applicare direttamente la pipeline!

