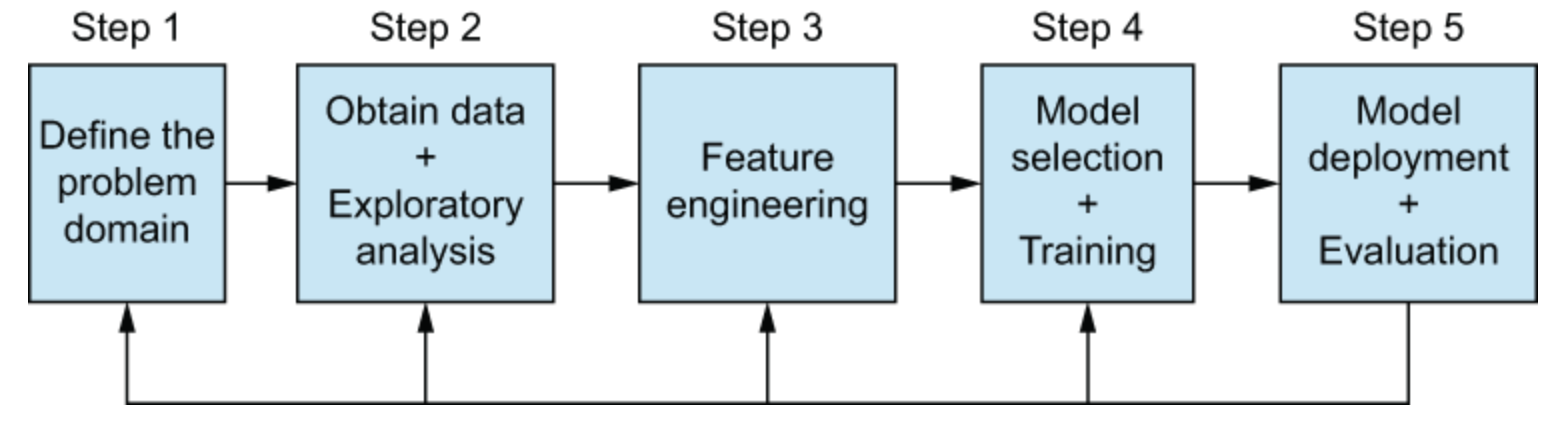
Feature engineering
Sviluppare modelli di Machine Learning per la produzione

Sinan Ozdemir
Data Scientist and Author
Introduzione al feature engineering
- Trasformare i dati di training per massimizzare le performance della pipeline ML
- Ridurre la complessità computazionale
- Esempi
- Aggregare dati da più fonti
- Costruire nuove feature
- Applicare trasformazioni alle feature
1 https://www.manning.com/books/feature-engineering-bookcamp
Aggregare dati da più fonti
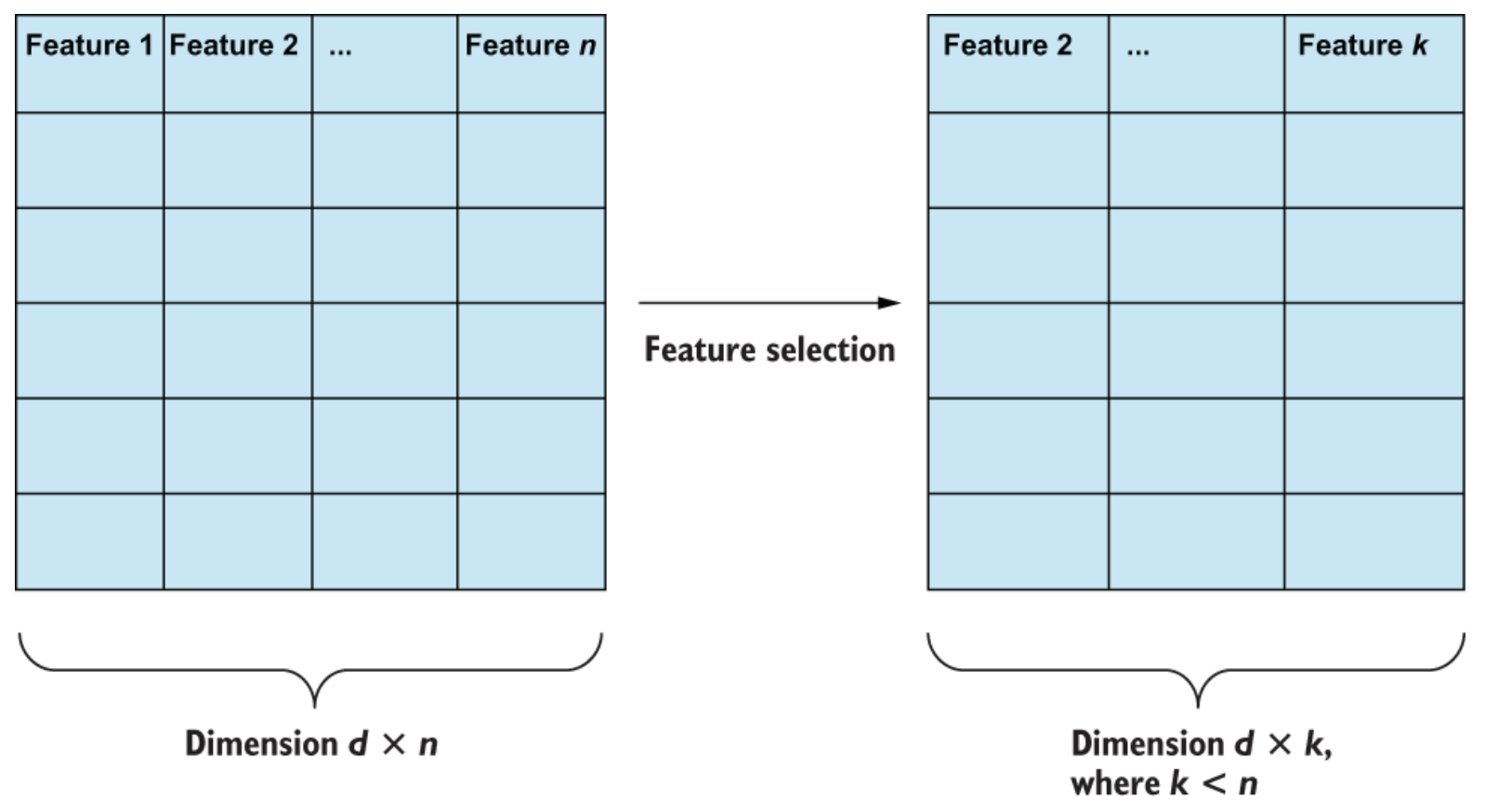
Selezione delle feature
1 https://www.manning.com/books/feature-engineering-bookcamp
Per saperne di più sul feature engineering


