Leakage nelle feature: uso di dati non disponibili nel caso reale
Leakage nella strategia di validazione: la strategia non rispecchia il caso reale
Dati temporali
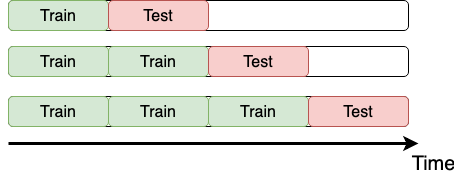
Time K-fold cross-validation
Time K-fold cross-validation
# Importa TimeSeriesSplit
from sklearn.model_selection import TimeSeriesSplit
# Crea un oggetto TimeSeriesSplit
time_kfold = TimeSeriesSplit(n_splits=5)
# Ordina train per data
train = train.sort_values('date')
# Cicla su ogni split di cross-validation
for train_index, test_index in time_kfold.split(train):
cv_train, cv_test = train.iloc[train_index], train.iloc[test_index]
Pipeline di validazione
# Lista per i risultati
fold_metrics = []
for train_index, test_index in CV_STRATEGY.split(train):
cv_train, cv_test = train.iloc[train_index], train.iloc[test_index]
# Allena un modello
model.fit(cv_train)
# Fai previsioni
predictions = model.predict(cv_test)
# Calcola la metrica
metric = evaluate(cv_test, predictions)
fold_metrics.append(metric)
Confronto modelli
Numero fold
MSE Modello A
MSE Modello B
Fold 1
2.95
2.97
Fold 2
2.84
2.45
Fold 3
2.62
2.73
Fold 4
2.79
2.83
Punteggio di validazione complessivo
import numpy as np
# Media semplice sui fold
mean_score = np.mean(fold_metrics)