Somiglianze basate sul testo
Creare motori di raccomandazione in Python

Rob O'Callaghan
Director of Data
Lavorare senza attributi chiari

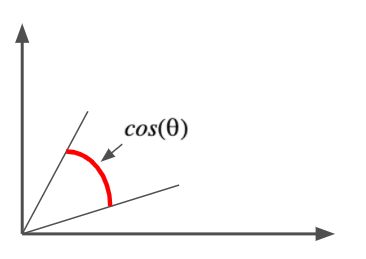
Similarità coseno
Distanza coseno: $$cos(\theta)=\frac{A.B }{||A||\cdot||B||}$$
Creare motori di raccomandazione in Python
Rob O'Callaghan
Director of Data
Distanza coseno: $$cos(\theta)=\frac{A.B }{||A||\cdot||B||}$$

