Iperparametri di KNN
Rilevamento delle anomalie in Python

Bekhruz (Bex) Tuychiev
Kaggle Master, Data Science Content Creator
Metriche di distanza

Distanza Manhattan
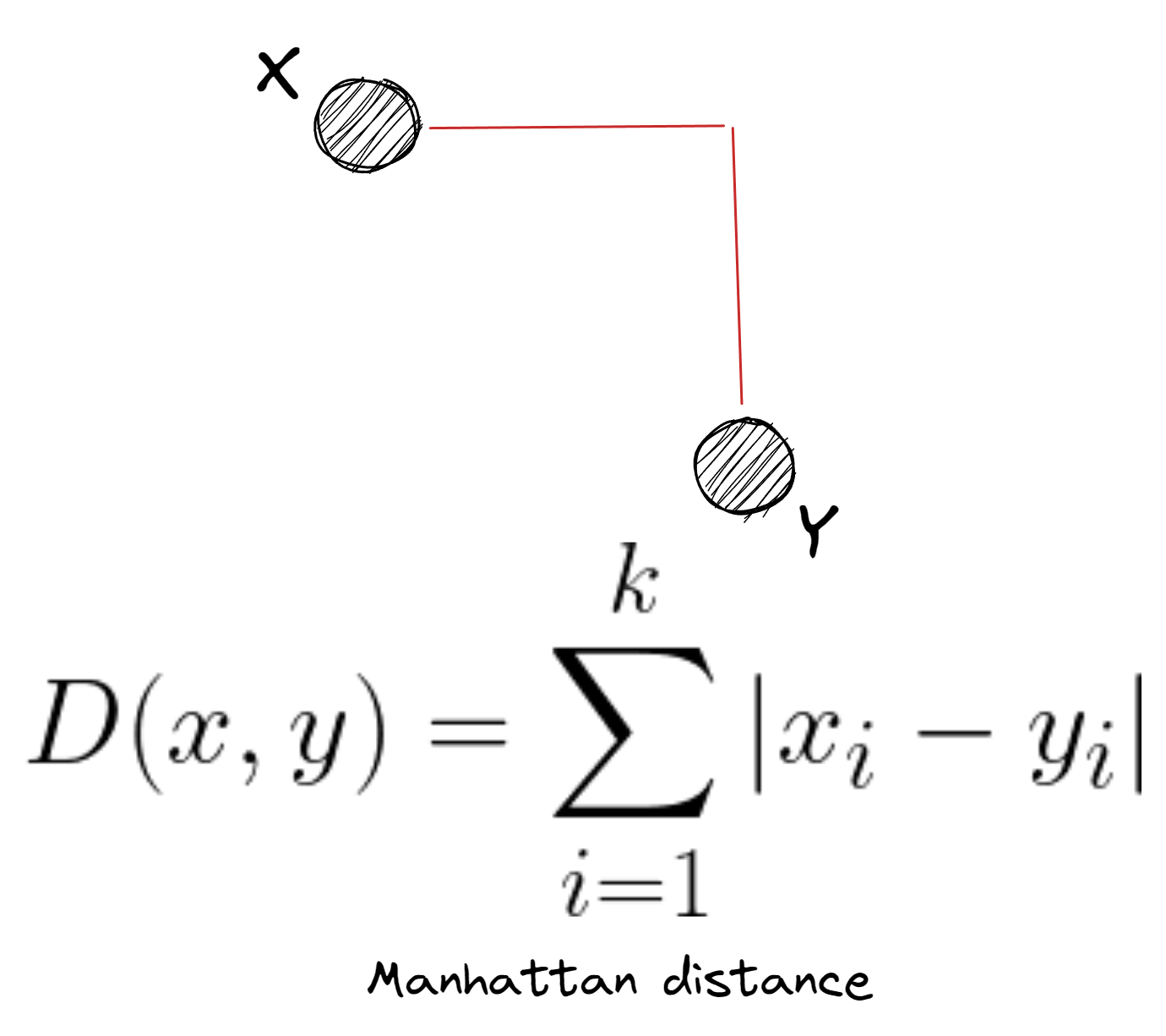
Distanza Manhattan
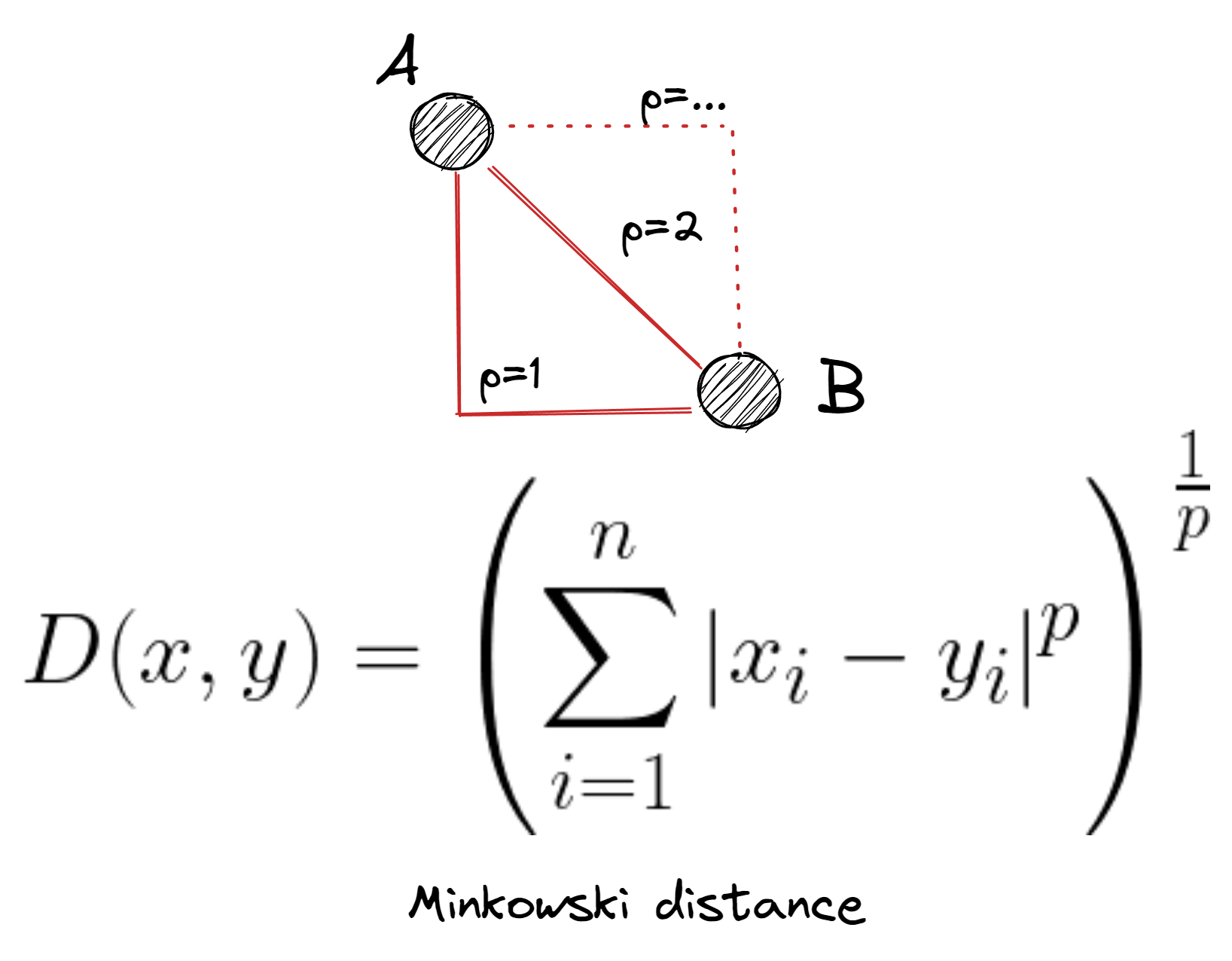
Distanza di Minkowski
Rilevamento delle anomalie in Python
Bekhruz (Bex) Tuychiev
Kaggle Master, Data Science Content Creator

