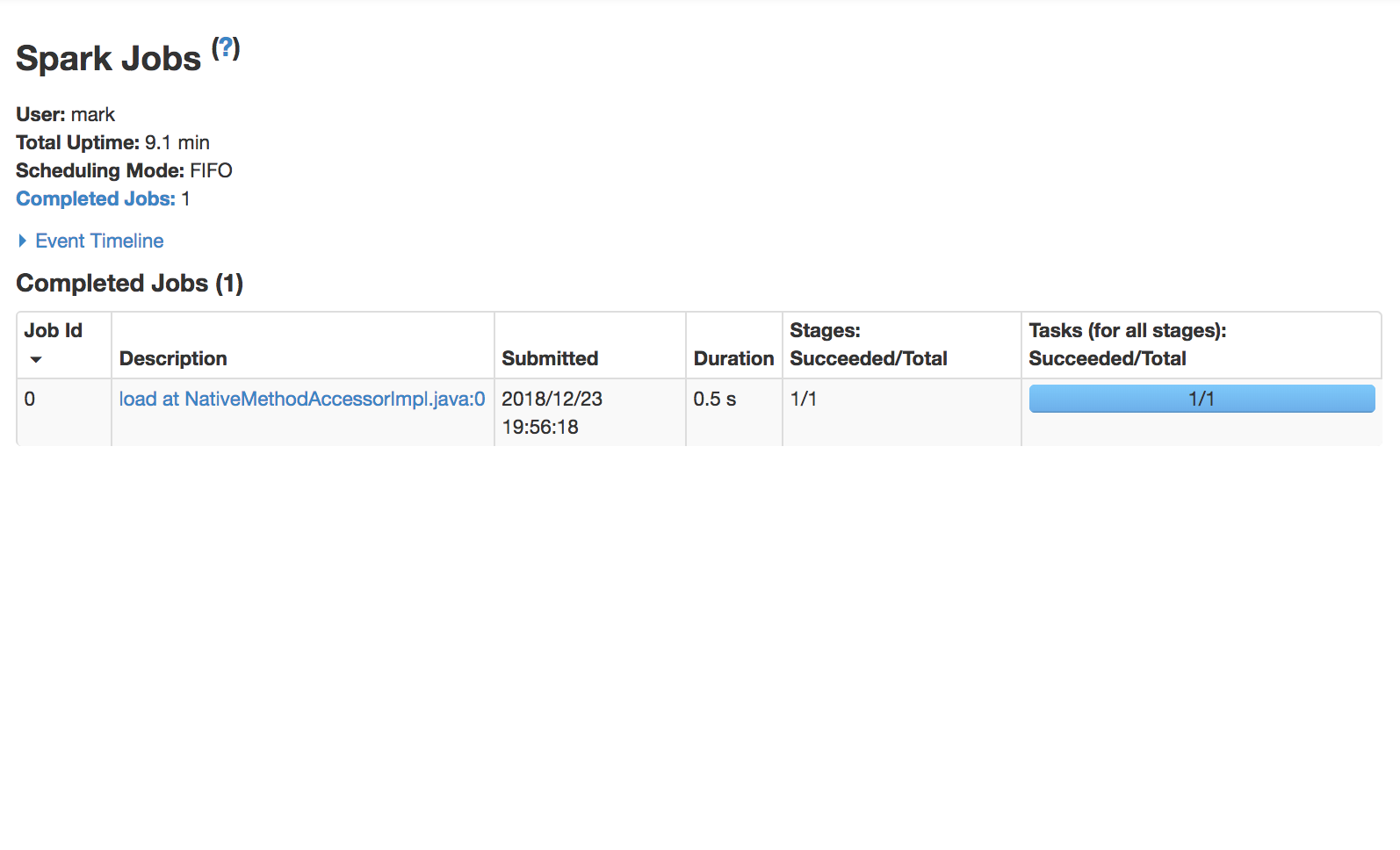
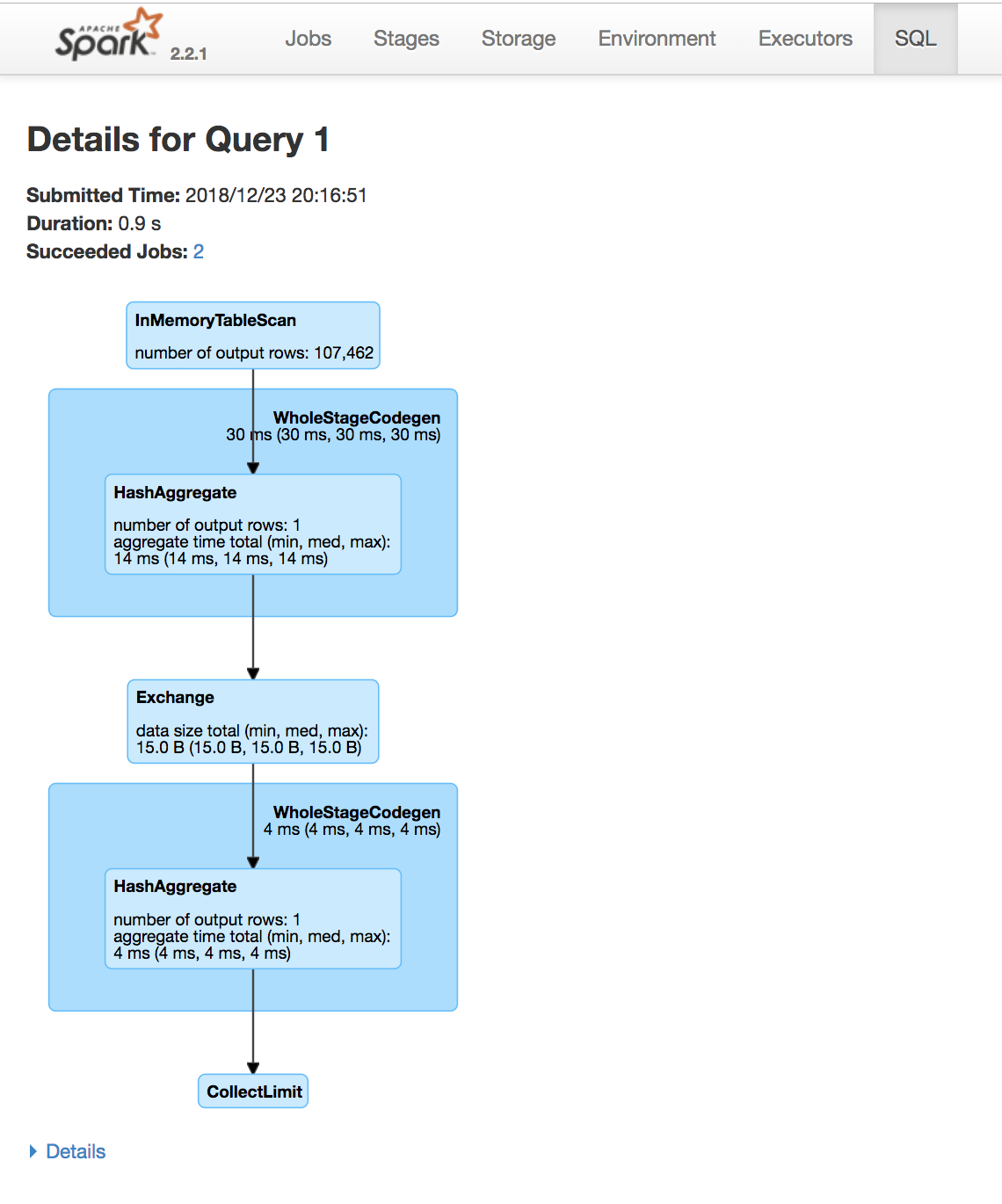
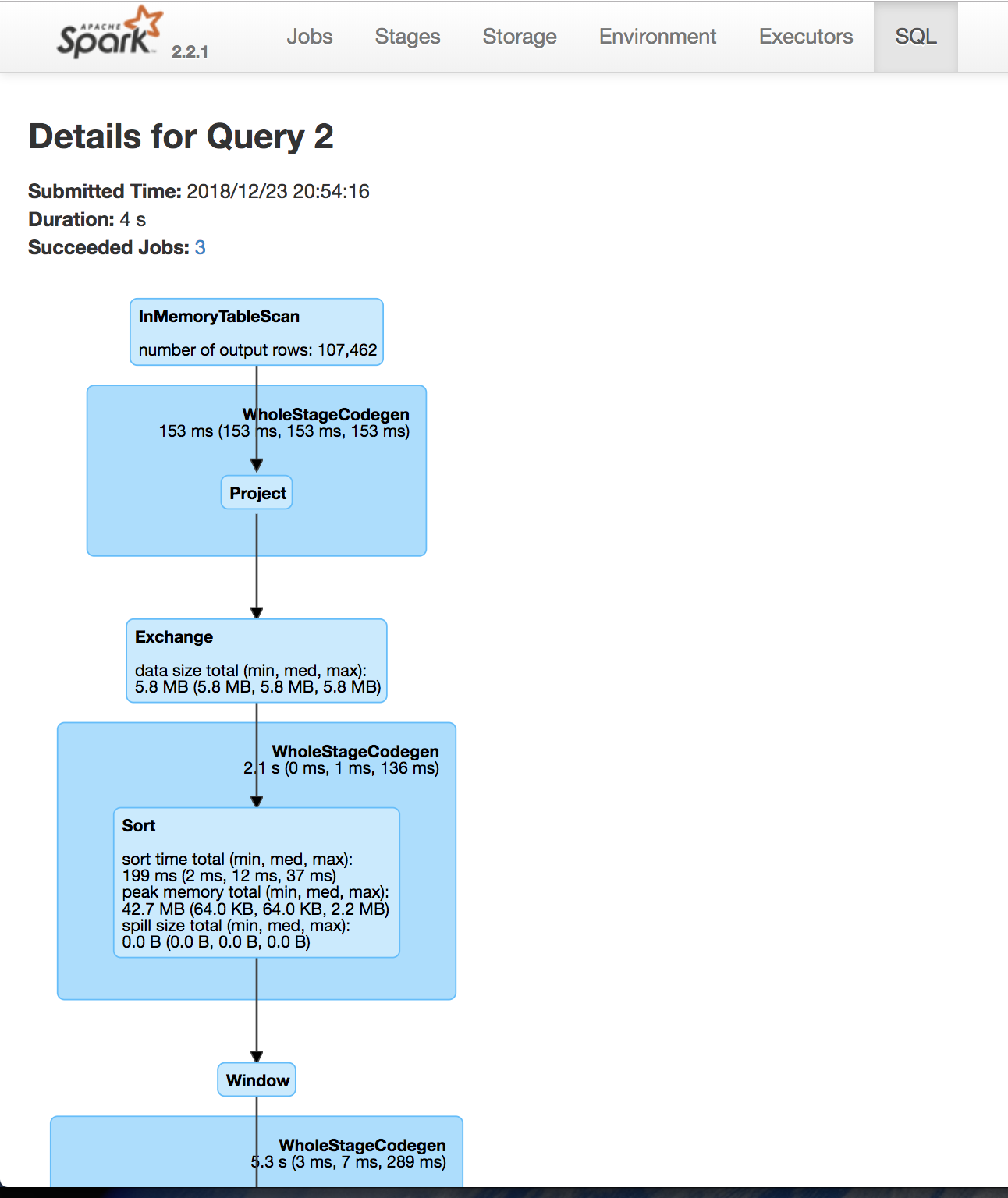
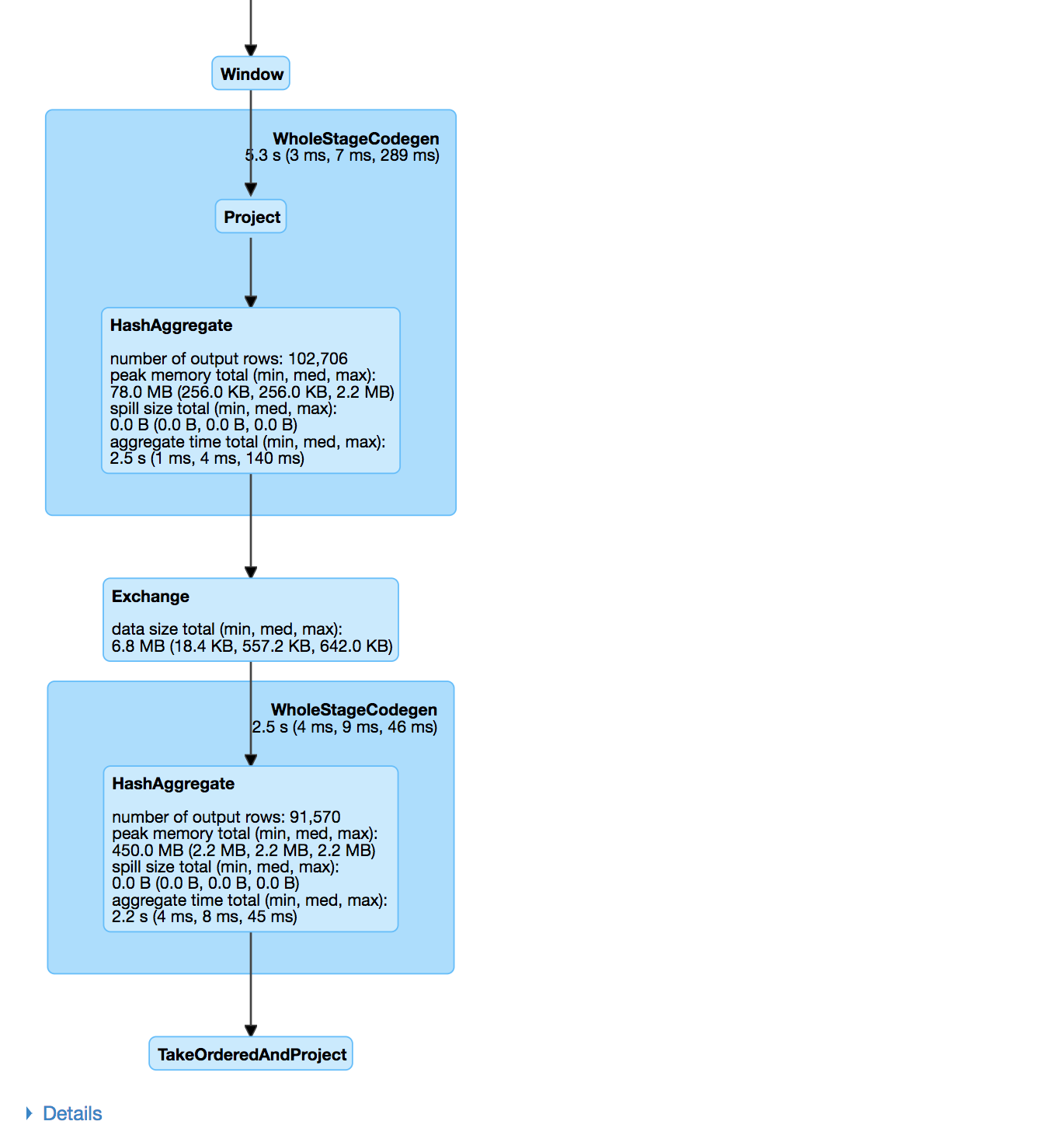
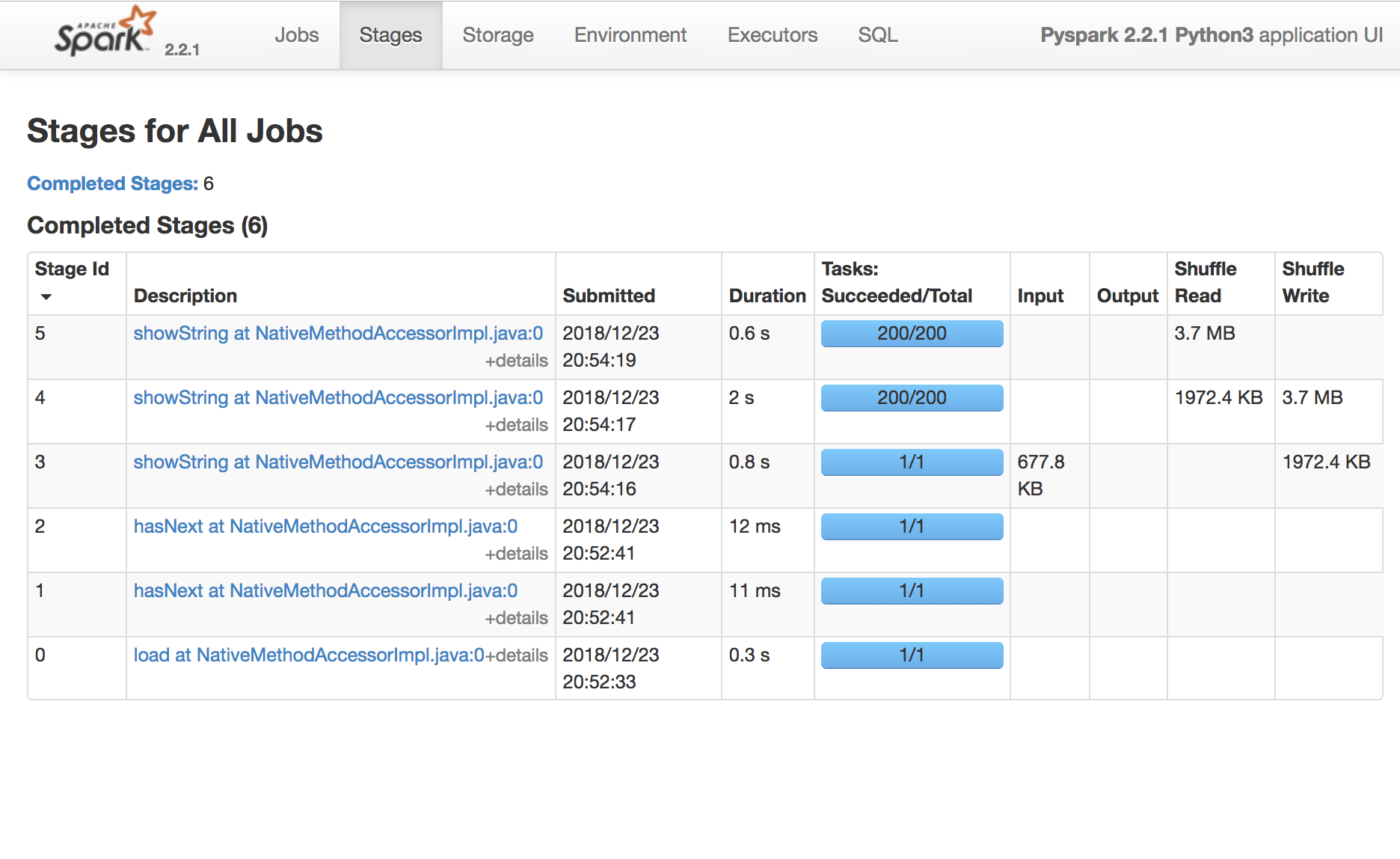
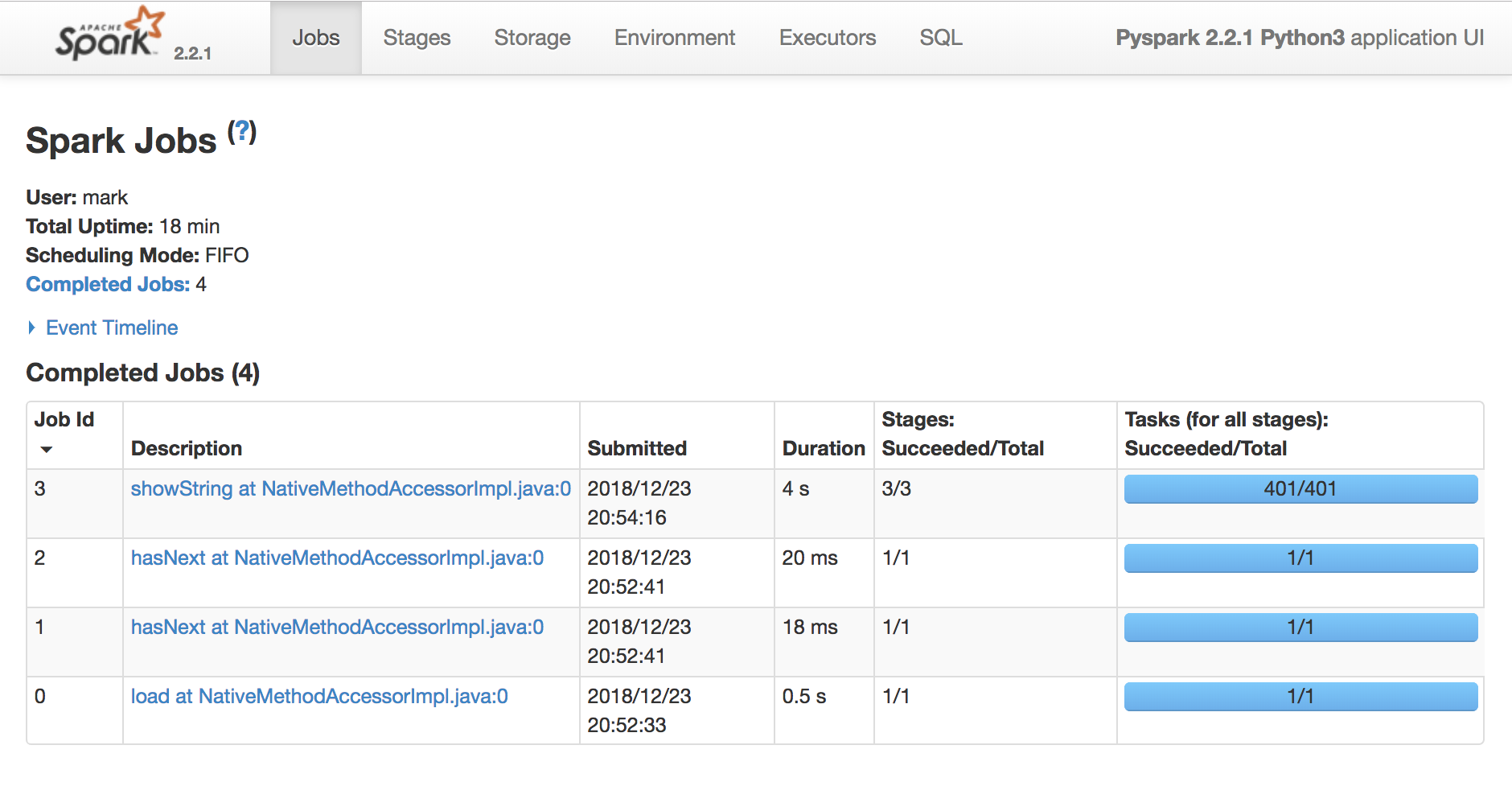
Usa la Spark UI per ispezionare l’esecuzione
Un task Spark è un’unità di esecuzione che gira su una singola CPU
Uno stage Spark è un gruppo di task che eseguono lo stesso calcolo in parallelo, ciascuno su un sottoinsieme di dati
Un job Spark è un’elaborazione avviata da un’azione, divisa in uno o più stage.