Migliorare le tue visualizzazioni dei dati in Python
Nick Strayer
Instructor
denver_may = pollution.query("city == 'Denver' & month == 8")
# Esegui la media bootstrap su un vettore
def bootstrap(data, n_boots):
return [np.mean(np.random.choice(data,len(data)))
for _ in range(n_boots) ]
# Genera 1.000 campioni bootstrap
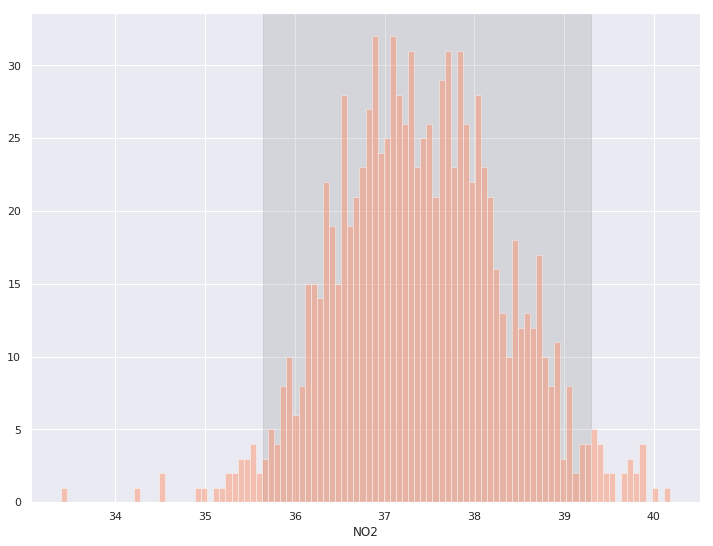
boot_means = bootstrap(denver_may.NO2, 1000)
# Limiti inferiore e superiore dell'intervallo al 95%
lower, upper = np.percentile(boot_means, [2.5, 97.5])
# Sfondo ombreggiato dell'intervallo
plt.axvspan(lower, upper, color='grey', alpha=0.2)
# Istogramma dei campioni
sns.histplot(boot_means, bins = 100)
# Crea un DataFrame dei dati bootstrap
denver_may_boot = pd.concat([
denver_may.sample(n=len(denver_may), replace=True).assign(sample=i)
for i in range(100)])
# Regressioni per ogni campione
sns.lmplot('CO', 'O3', data=denver_may_boot, scatter=False,
# Chiedi a seaborn di tracciare
# una retta per ogni ricampionamento
hue='sample',
# Linee arancioni e trasparenti
line_kws = {'color': 'coral', 'alpha': 0.2},
# Niente intervalli di confidenza
ci=None, legend = False)
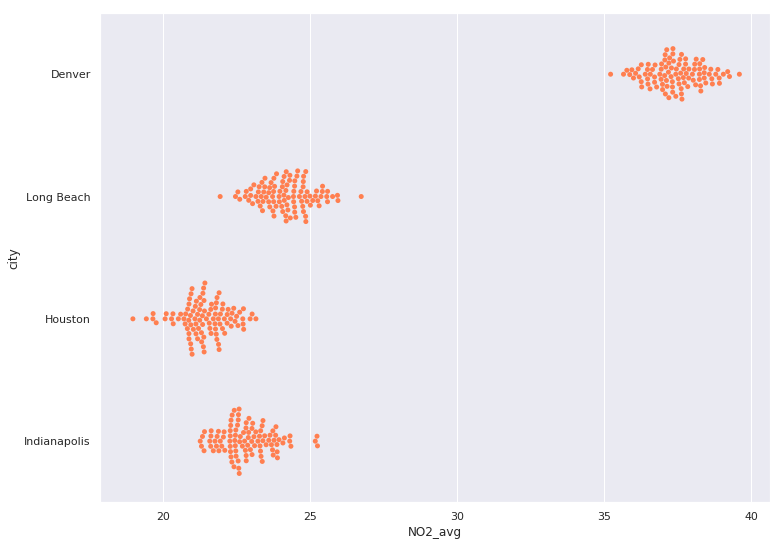
aug_pol = pollution.query("month == 8")
# DataFrame contenitore per i campioni bootstrap
city_boots = pd.DataFrame()
for city in ['Denver', 'Long Beach', 'Houston', 'Indianapolis']:
# Filtra il NO2 della città
city_NO2 = aug_pol[aug_pol.city == city].NO2
# 100 campioni bootstrap del NO2 della città, in un DataFrame
cur_boot = pd.DataFrame({ 'NO2_avg': bootstrap(city_NO2, 100),
'city': city })
# Aggiungi agli altri bootstrap
city_boots = pd.concat([city_boots,cur_boot])
# Visualizza molti bootstrap con un beeswarm
sns.swarmplot(y="city", x="NO2_avg", data=city_boots,
# Imposta lo stesso colore per tutti
color='coral')
Pronti a (ri)campionare
Migliorare le tue visualizzazioni dei dati in Python