Non selezionare colonne non necessarie nel risultato
Ricorda: Redshift è colonnare e legge per colonna
Usa DISTKEY e SORTKEY
Usali nelle seguenti clausole quando possibile
JOIN
WHERE
GROUP BY
Usa i SORTKEY in ordine in ORDER BY
Ottimo: sortkey_1, sortkey_2, sortkey_3
Non ottimale: sort_key_1, sort_key_3
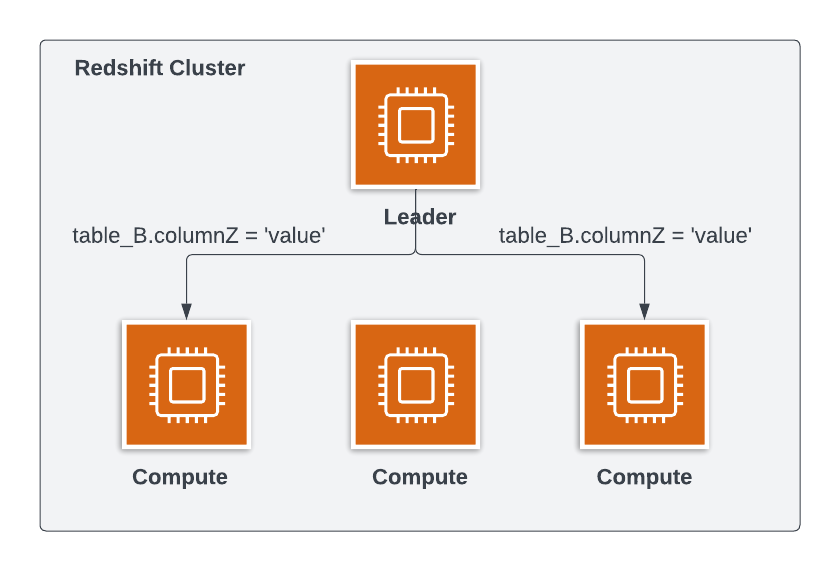
Costruire buoni predicati
Usa DISTKEY e SORTKEY
Vicino alla join della tabella
Evita funzioni in esse
SELECT receipts.cookie_id,
sum(receipts.total)
FROM receipts
JOIN cookies ON receipts.cookie_id = cookies.cookie_id
-- Keep cookies predicates in the join to push down to nodes holding the records for cookies
AND cookies.available_on < '2023-11-14'
AND cookies.end_of_sale IS null
-- Predicates that are not part of the join or on the joined table stay in the WHERE clause
WHERE receipts.order_time > '2023-11-13'
GROUP BY 1 ORDER BY 1;
Mantieni coerente l'ordine delle colonne
Quando usi:
GROUP BY
ORDER BY
Sbagliato
GROUP BY col_one, col_two, col_three
ORDER BY col_two, col_three, col_one
Corretto
GROUP BY col_two, col_three, col_one
ORDER BY col_two, col_three, col_one
Usa le subquery con criterio
Usa join appropriati invece di una semplice subquery
Usa EXISTS nei predicati quando verifichi solo se una subquery restituisce risultati
SELECT column_name
FROM table_name
WHERE EXISTS
(SELECT column_name
FROM table_name
WHERE active is True);
Se riutilizzi subquery, usa CTE per sfruttare la cache