Schemi esterni, formati di file e di tabella
Introduzione a Redshift

Jason Myers
Principal Architect
Schemi esterni
Componenti del database
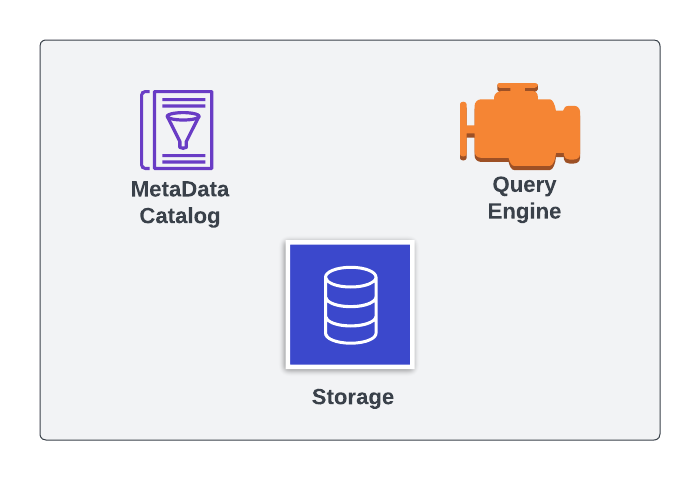
- Quando catalogo metadati e storage non sono nel cluster, sono considerati esterni
Redshift Spectrum
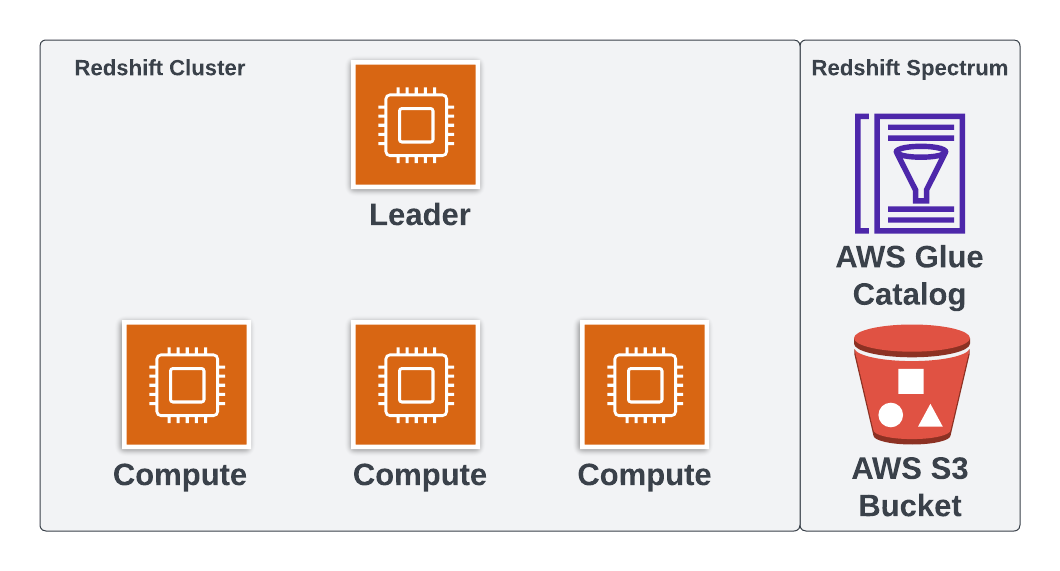
- Redshift è il motore
- Usa AWS Glue Data Catalog e storage AWS S3 per default

