L’ecosistema tidymodels
Modellazione con tidymodels in R

David Svancer
Data Scientist
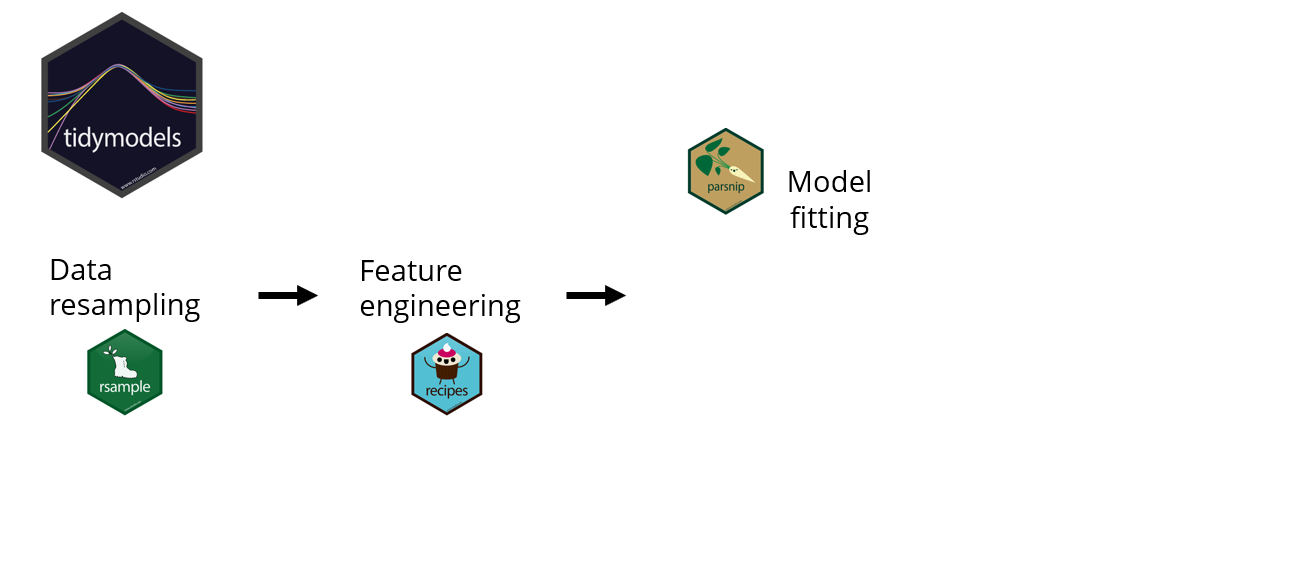
Raccolta di pacchetti di machine learning

Raccolta di pacchetti di machine learning

Raccolta di pacchetti di machine learning

Raccolta di pacchetti di machine learning
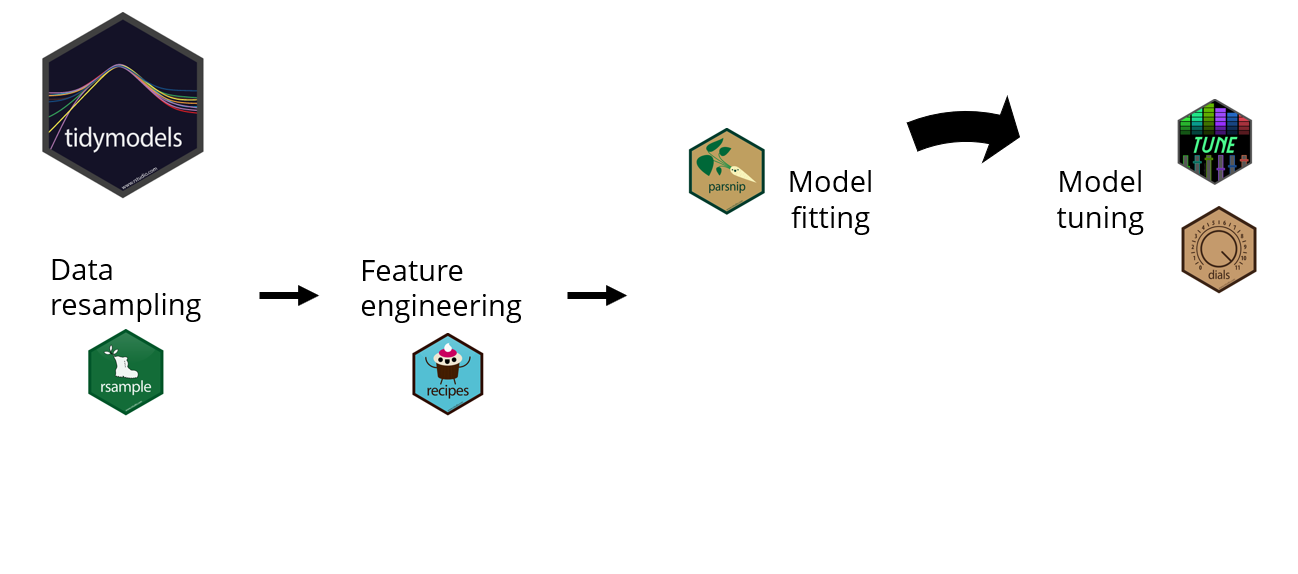
Raccolta di pacchetti di machine learning
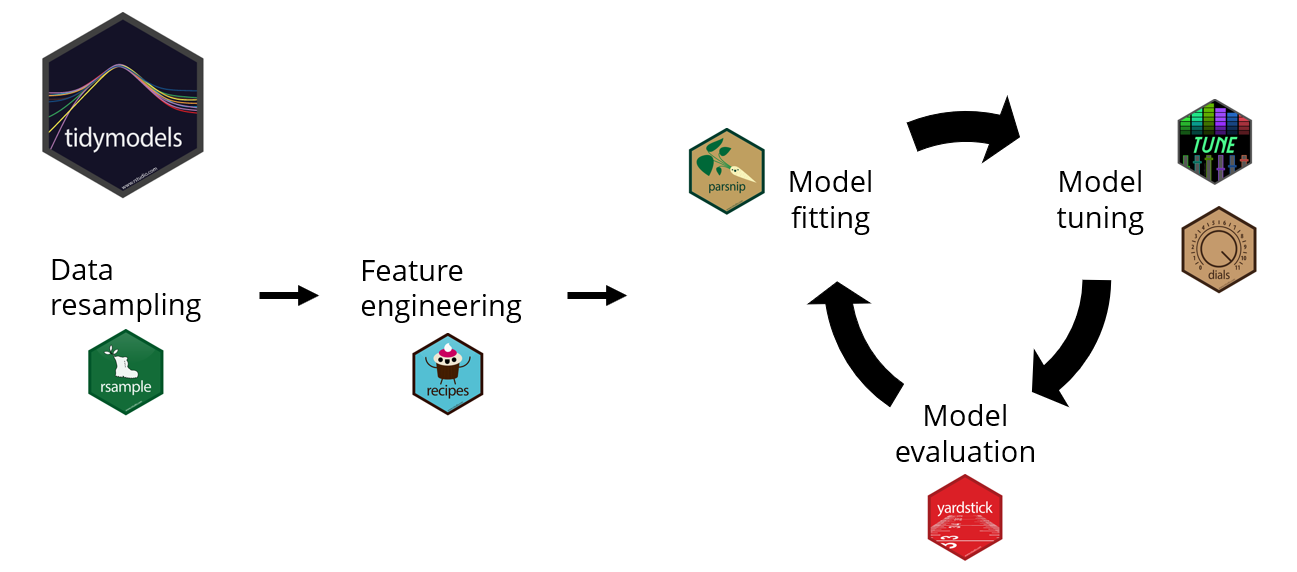
Raccolta di pacchetti di machine learning
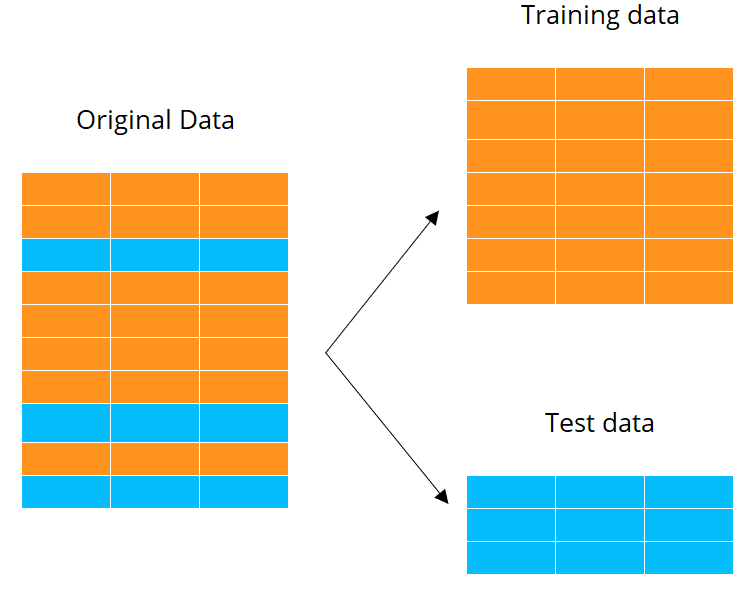
Campionamento dei dati